近日,OpenAI 在 GitHub 上开源***工具包 gradient-checkpointing,该工具包通过设置梯度检查点(gradient-checkpointing)来节省内存资源。据悉,对于普通的前馈模型,可以在计算时间只增加 20% 的情况下,在 GPU 上训练比之前大十多倍的模型。雷锋网(公众号:雷锋网) AI 研习社将该开源信息编译整理如下:
通过梯度检查点(gradient-checkpointing)来节省内存资源
训练非常深的神经网络需要大量内存,利用 Tim Salimans 和 Yaroslav Bulatov 共同开发的 gradient-checkpointing 包中的工具,可以牺牲计算时间来解决内存过小的问题,让你更好地针对模型进行训练。
对于普通的前馈模型,可以在计算时间只增加 20% 的情况下,在 GPU 上训练比之前大十多倍的模型。
训练深度神经网络时,损失的梯度是在内存密集部分通过反向传播(backpropagation)算法来计算的。在训练模型时定义计算图中的检查点,并在这些检查点之间通过反向传播算法重新计算这些图,可以在降低内存的同时计算梯度值。
当训练一个 n 层的深度前馈神经网络时,可以利用这种方式将内存消耗减少到 O (sqrt (n)),代价是需要执行一个额外的前向传递操作。这个库可以在 Tensorflow 中实现这一功能——使用 Tensorflow graph editor 来自动重写后向传递的计算图。
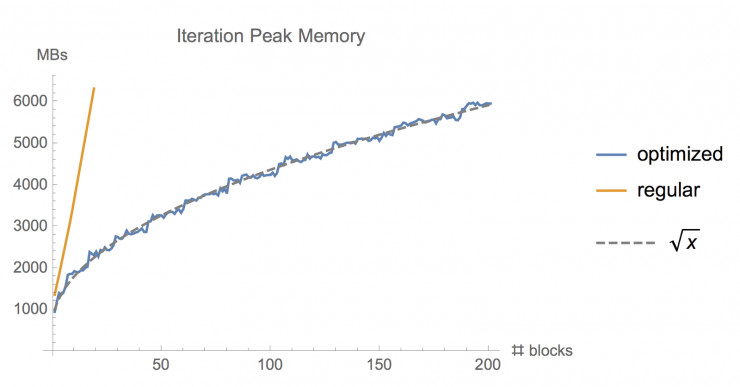
图:使用常规的 tf.gradients 函数和使用这种优化内存梯度实现法(memory-optimized gradient implementation)训练不同层数的 ResNet 模型时需要的内存对比
大家现在就可以安装
pip install tf-nightly-gpu
pip install toposort networkx pytest
当执行这一程序时,需要保证能找到 CUPTI。
这时可以执行
export LD_LIBRARY_PATH="${LD_LIBRARY_PATH}:/usr/local/cuda/extras/CUPTI/lib64
使用方法
这个库提供嵌入式功能,能对 tf.gradients 函数进行替换,可以输入如下程序来引入相关函数:
from memory_saving_gradients import gradients
大家可以像使用 tf.gradients 函数一样使用 gradients 函数来计算参数损失的梯度。
gradients 函数有一个额外的功能——检查点(checkpoints)。
检查点会对 gradients 函数进行指示——在计算图的前向传播中,图中的哪一部分节点是用户想要检查的点。随后,会在后向传播中重新计算检查点之间的节点。
大家可以为检查点提供一系列张量(gradients (ys,xs,checkpoints=[tensor1,tensor2])),或者可以使用如下几个关键词('collection'、'memory' 、'speed')来进行设置。
覆盖 tf.gradients 函数
使用 gradients 函数的另一个方法是直接覆盖 tf.gradients 函数,方法如下:
import tensorflow as tf
import memory_saving_gradients
# monkey patch tf.gradients to point to our custom version, with automatic checkpoint selection
def gradients_memory (ys, xs, grad_ys=None, **kwargs):
return memory_saving_gradients.gradients (ys, xs, grad_ys, checkpoints='memory', **kwargs)
tf.__dict__["gradients"] = gradients_memory
这样操作之后,所有调用 tf.gradients 函数的请求都会使用新的节省内存的方法。
测试
在测试文件夹中,有已经写好的用于测试代码准确性和不同模型占用内存的脚本。
大家可以执行 ./run_all_tests.sh 来修改代码,并着手测试。
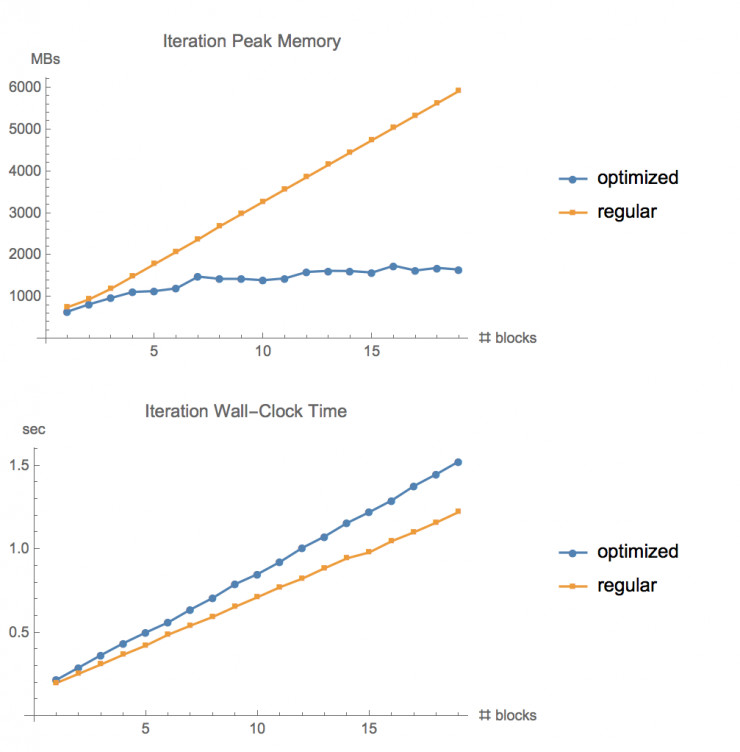
图:在 CIFAR10 数据集上,使用常规的梯度函数和使用***的优化内存函数,在不同层数的 ResNet 网络下的内存占用情况和执行时间的对比
via:GitHub