存储,是我们码农每天都要打交道的事情,而当我们面对RAID,SAN,对象存储,分布式数据库等技术的时候,又往往似是而非,存储成了我们熟悉的陌生人。
在老码农眼中,存储仿佛是这个样子的。
从计算机结构出发
存储是计算机的一部分,在冯诺伊曼体系结构中,有一个重要的单元即存储器,它连接了输入/输出,以及控制器和运算器,处于核心纽带的位置。
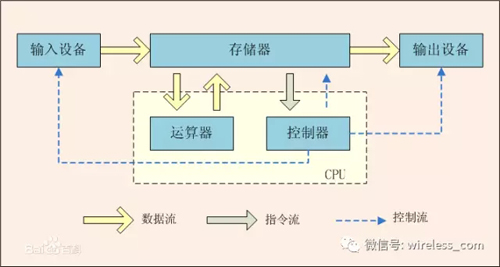
与存储中的数据交互是通过IO实现的,IO的性能直接影响着系统的性能,甚至我们往往把应用分为IO密集型和CPU密集型等等。
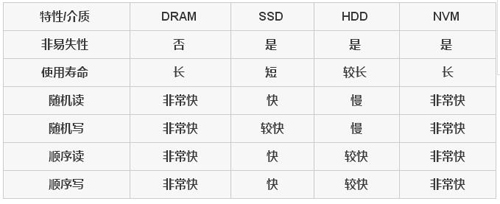
从IO的访问方式来看,可以分为阻塞/非阻塞,同步/异步。在Linux,提供了5种IO模型:
- 阻塞I/O:blocking I/O
- 非阻塞I/O :nonblocking I/O
- I/O复用:I/O multiplexing (select 和poll)
- 信号驱动I/O :signal driven I/O (SIGIO)
- 异步I/O :asynchronous I/O (the POSIX aio_functions)
从性能上看,异步 IO 的性能无疑是***的。
对IO进行抽象,分为逻辑IO和物理IO两类,分为磁盘,卷和文件系统三层。做一个简单的比喻,磁盘象空地,卷如同小区,而文件系统就是小区里的楼房和房间。卷位于操作系统和硬盘之间,屏蔽了底层硬盘组合的复杂性,使得多块硬盘在操作系统来看就像一块硬盘。镜像,快照,磁盘的动态扩展,都可以通过卷来实现。而文件系统最主要的目标就是对磁盘空间的管理。
对程序员而言,我们所面对的一般是文件系统,通过文件系统感知存储中的数据。
提高存储的可靠性—— 磁盘阵列
一旦硬盘故障,面临的很可能就是数据的丢失,将演变成一场灾难。对很多的企业应用而言,直接提高存储可靠性的方式是通过磁盘阵列——RAID。
RAID是Redundant Arrays of Independent Disks的缩写,是把相同的数据存储在多个硬盘的不同的地方。通过把数据放在多个硬盘上,输入输出操作能以平衡的方式交叠,改良性能,也延长了平均故障间隔时间(MTBF),储存冗余数据也增加了容错, 从而提高了存储的可靠性。
常见的RAID类型如下:
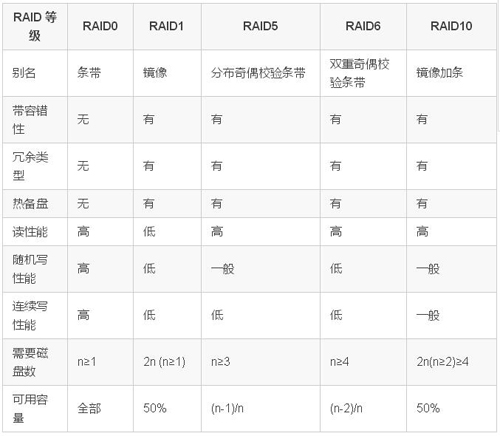
RAID 的两个关键目标是提高数据可靠性和 I/O 性能。实际上, 可以把RAID 看作成一种虚拟化技术,它对多个物理磁盘虚拟成一个大容量的逻辑驱动器。
提高存储的容量——存储网络
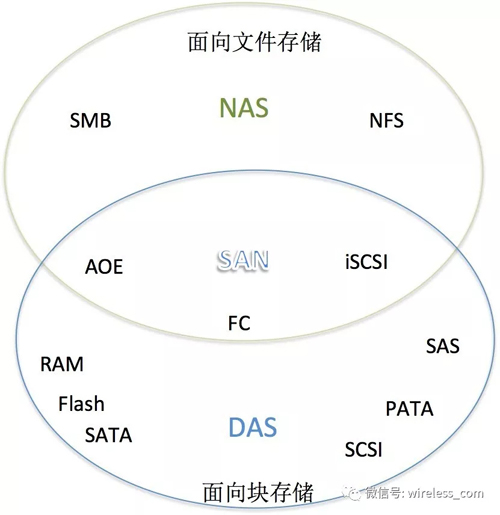
尽管磁盘阵列也在一定程度上提高了存储的容量, 但是难以满足人们对存储容量的需求。为了解决存储空间的问题, 采用分而治之的方式,通过DAS将硬盘独立为存储空间。 DAS(Direct Attached Storage—直接连接存储)是指将存储设备通过SCSI接口或光纤通道等直接连接到一台主机上。DAS 就是一组磁盘的集合体,数据读取和写入等也都是由主机来控制。 然而,DAS 没法实现多主机共享磁盘空间的问题。
为了解决共享的问题,于是有了 SAN ( Storage Area Network)————存储网络。SAN 网络由于不会直接跟磁盘交互,而是解决数据存取的问题,使用的协议比 DAS 的层面要高。对于存储网络而言,对带宽的要求非常高,因此 SAN 网络下,光纤成为连接的基础。光纤上的协议比以太网协议更简洁,性能也更高。
从数据层面来看,存储空间的共享可以体现为文件的共享。NAS(Network Attached Storage)是将存储设备通过标准的以太网,连接到一组主机上,N是组件级的存储方法,能够解决迅速增加存储容量的需求。也就是说,NAS从文件系统层面解决存储的扩容问题。
NAS和SAN本质的不同在文件管理系统的不同。在 SAN中,文件管理系统分别在每一个应用服务器上;而NAS是每个应用服务器通过网络共享协议(如NFS等)使用同一个文件管理系统。NAS的出发点是在应用、用户和文件以及它们共享的数据上;而SAN的出发点在磁盘以及联接它们的基础设施架构。
三者之间的关系如下图所示:
一般存储系统的应用
存储是我们软件产品和服务的必备环节,常见的存储系统应用有:
- 配置数据服务:只读访问
- 缓存系统:有/无持久化
- 文件系统:目录/POSIX
- 对象系统:Blob/KV
- 表格系统:Column/SQL
- 数据库系统:满足ACID
- 备份系统:冷存储/延迟读
- ......
在使用存储系统的时候,我们可能需要关注的指标:
- 存储成本
- 功能: 读/写/列索引/条件查询/事务/权限。。
- 性能:读写的 吞吐/IOPS/延时/负载均衡。。。
- 可用性
- 可靠性
- 可扩展性
- 一致性
存储引擎是存储系统中的发动机,直接决定存储系统的性能和功能,实现了存储系统的增/删/改/查,在数据库系统中广泛采用。 常见的存储引擎有:哈希存储引擎,B树存储引擎(磁盘索引节省内存)和 LSM树存储引擎(随机写转为顺序写)。
分布式存储系统应用——云服务
分布式存储系统一般采用可扩展的系统结构,利用多台存储服务器分担存储负载,利用位置服务器定位存储信息,不但提高了系统的可靠性、可用性和存取效率,而且易于扩展。
分布式存储的应用场景一般分为三种:
- 对象存储: 也就是通常的键值存储,其接口就是简单的GET,PUT,DEL和其他扩展
- 块存储: 通常以QEMU Driver或者Kernel Module的方式存在,需要实现Linux的Block Device接口或者QEMU提供的Block Driver接口,如AWS的EBS,青云的云硬盘,百度云的云磁盘等等
- 文件存储: 支持POSIX的接口,提供了并行化的能力,如Ceph的CephFS,但是有时候又会把GFS,HDFS这种非POSIX接口的类文件存储接口算成此类。
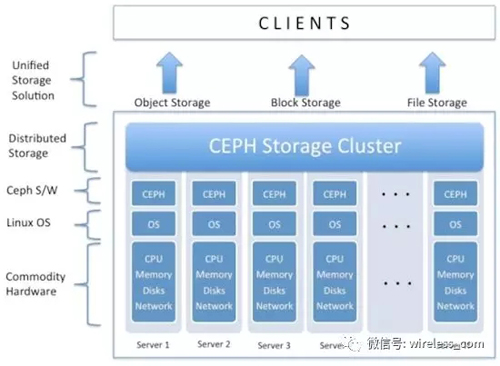
一般地,对象存储通常以大文件为主,要求足够的IO带宽。块存储:即能应付大文件读写,也能处理好小文件读写,块存储要求的延迟是***的。文件存储需要考虑目录、文件属性等等的支持,对并行化的支持难度较大,通过具体实现来定义接口,可能会容易一点。
实现一个分布式存储系统,通常会涉及到元数据,分区,复制,容错等诸多方面。分布式设计采用主从、全分布式或者是兼而有之, 底层的存储可以依赖本地文件系统的接口,或者实现一个简单的物理块管理,但都不是相对容易的事。
幸运的是,分布式存储系统已经成为了云服务的基础能力,尤其是对象存储,如七牛、S3、OSS、BOS 等等, 已经是标配了。有了面向云服务的存储, 使我们更多聚焦在业务本身,各种存储带来的烦恼会逐渐随风而逝么?!
【本文来自51CTO专栏作者“老曹”的原创文章,作者微信公众号:喔家ArchiSelf,id:wrieless-com】