今天给大家分享的主题是基于 StackStorm 的携程运维自动化平台。
去年 5 月,勒索病毒爆发,席卷全球,影响了政府部门、医疗机构、公共交通、学校、企业等等,给全世界带来了巨大损失。
如果有投资眼光的人,遇到这个事情,考虑的可能是购买比特币。而作为运维工程师,考虑的只是如何防止病毒影响自己公司的业务。相信很多运维同行,都参与到了应对勒索病毒的战役中。
关于这个病毒,虽然传播广,看起来威力巨大,但是也有很多应对措施。比如关闭 445 端口防止病毒传播,或者内网建立开关域名防止病毒运行。
当然,这些只是 workaround 的方案,最根本的还是要及时更新服务器的安全补丁。

如果只有几台、几十台服务器,补丁更新很简单,登陆上去点下安装或者敲一条命令就可以搞定。
当你有成千上万台服务器的时候靠人工是不可能的,如果一下子发一条命令下去到所有服务器也不合适,可能对业务造成巨大影响。

那么该如何自动给上万台服务器打补丁呢?我们先看一下,一台服务器上怎么操作打补丁。
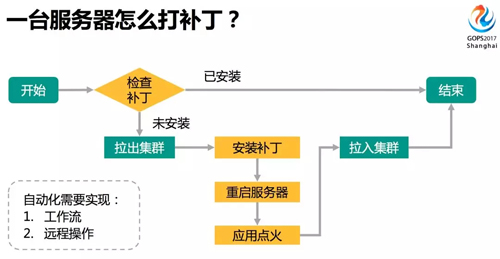
上图是个比较简单的操作流程。首先,检查服务器是否已经安装了补丁,如果已经安装流程就结束。
如果还没有安装,先将服务器拉出集群脱离生产,然后安装补丁,重启服务器让补丁生效。
在拉入集群之前,可能还需要给应用点火,比如让应用建缓存,让应用恢复到正常状态再接入生产流量。
这其中还有一些复杂问题,比如一个集群拉出部分服务器后,剩余服务器可能扛不住,要考虑集群可用性。
这样一个给一台服务器打补丁的过程,如果要实现自动化,就要完成两方面的任务:
- 实现图中整个工作流的运转。
- 不可能一台台登陆服务器操作,所以要实现远程操作,也就是图中的黄色部分。
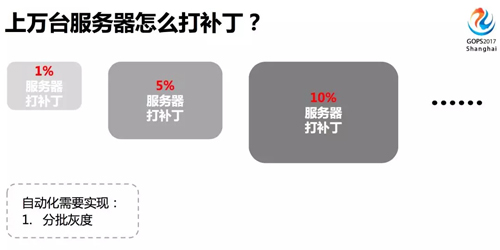
实现了一台服务器自动打补丁后,再从 1 扩展到 1000、10000,给成千上万台服务器打补丁,要做的一件事就是灰度、灰度、灰度,重要的事情说三遍。
不管你操作多么熟练,技术多么高超,对自己开发的工具多么自信,在做生产大批量运维操作的时候,都要谨慎再谨慎。
而分批灰度是做到谨慎的很好的方法,可以大大减小对生产的影响,提高网站可用性。

综合上述对实现上万台服务器自动打补丁的需求,我们搭建了一套自动化运维平台,包括三个模块:
- 使用 SaltStack 实现远程控制。
- 使用 StackStorm 实现操作流程。
- 使用我们自己开发的工具 Jobs 实现分批灰度。
而这样一套系统,不只是可以完成打补丁这样一个功能,基本可以覆盖各种日常运维操作自动化需求,所以拿出来和大家分享,下面将从三方面进行具体介绍。
远程控制
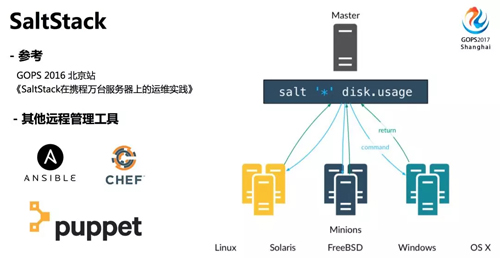
SaltStack 是一个开源的远程管理平台,可以管理各种操作系统的服务器,主要有 minion 和 master 两部分。
minion 安装在要管理的服务器上,启动后与 master 建立长连接,master 下发任务给 minion,minion 运行完成后,将任务结果返回给 master。
类似的远程管理工具还有 ansible、chef、puppet,大家可以根据实际应用场景选择。
操作流程
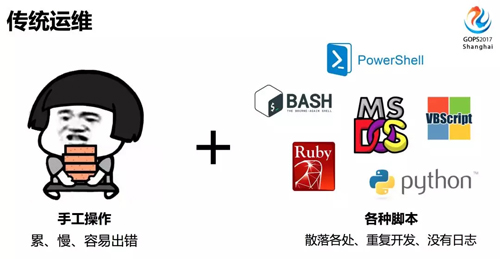
我们从运维发展的过程来看,首先是传统运维,主要靠手工操作。比如上线一台服务器,登陆服务器按照操作文档一步一步操作,更高级一点,把配置命令写到脚本里,运行一个或多个脚本完成配置。
有什么缺点呢?首先,人每天重复这样的工作,很累,又没有体现价值,交付效率低,疲劳时还容易出错,忘记某些配置。
使用脚本呢,容易出现相同功能重复开发,很多脚本不专门记录日志,查找历史操作比较困难。
使用脚本进行运维操作,发生了故障,由于没有统一的运维操作日志,无法及时了解谁做了什么。
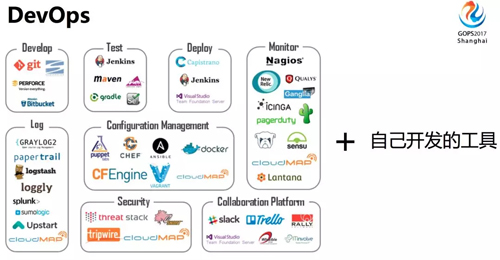
随着时间的发展,运维发展到更高级的 DevOps 时代,我们也正处于这个时代。
这个时代有一个明显的特征,就是各种各样开源工具的使用,同时自己会开发很多工具。工具带来了效率的提升,大大加速了运维自动化的进程。

有这么多的工具可以使用,也会存在一些问题。比如下面这些问题:
- 做一个复杂变更要操作很多工具
- 不同脚本或工具的代码里,相同操作重复造轮子
- 对别人开发的脚本或工具,不清楚具体操作逻辑
- 没有统一的运维操作日志
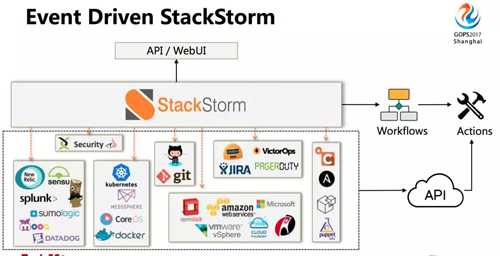
针对上面这些问题,我们考虑使用基于事件驱动的开源自动化运维平台 StackStorm。
你有各种各样的工具,会提供很多操作的 API,你把这些 API 调用实现成 action 放在 StackStorm 上,然后可以把这些 action 组合成复杂的 Workflow 实现不同的任务。
StackStorm 可以实现操作插件化、操作逻辑可视化、运维日志统一化。
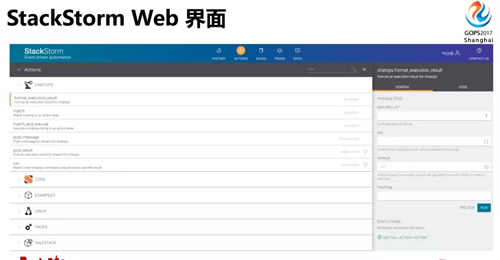
StackStorm 提供了 Web 界面,也提供了 API。你把各种工具的操作放在里面,选中一个操作,填入参数,就可以点击运行。
使用 StackStorm 具体能做一些什么事情呢?

我们日常有很多不同的变更操作,但是经常会重复做一些相同的事情,比如安装软件、重启服务、拉入拉出集群等。
如果把不同变更操作过程进行拆分,就会拆出这样一个个小的运维原子操作。
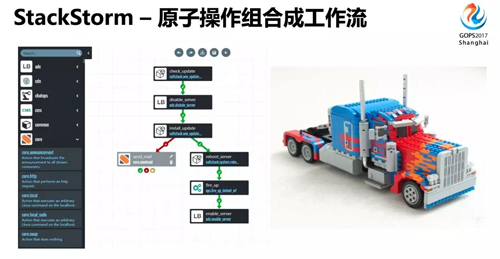
反过来,我们可以把这些运维原子操作进行组合,像乐高积木可以拼出各种各样的模型,我可以将原子操作组合成各种各样的变更流程。
这样相同的操作只需要实现一次,就可以重复使用,避免了重复造轮子,大大提高了开发效率。
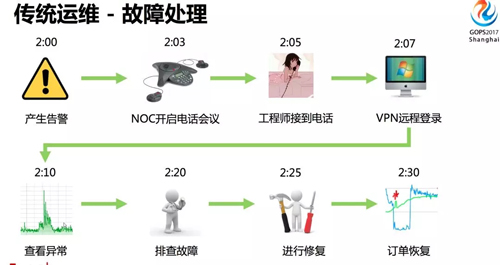
在故障处理方面,我们来看一个常规的 oncall case。
比如凌晨 2 点,出现了一个订单下跌的告警,NOC 开启电话会议,将相关工程师 call 进来,工程师接到电话后迷迷糊糊地爬起来,问出现了什么问题,NOC 需要陈述一遍。
然后工程师匆匆忙忙打开电脑,通过 VPN 登陆到内网查看相关监控指标,利用自己的经验进行故障排查,花了很多时间终于定位到故障,然后进行修复操作,最后故障恢复。

这样的故障处理过程,存在什么问题呢?
- 修复时间长
- 半夜处理故障,操作容易出错,而且影响第二天上班
- 随着业务增长,报警增多,无法及时处理
- 导致网站可用性下降
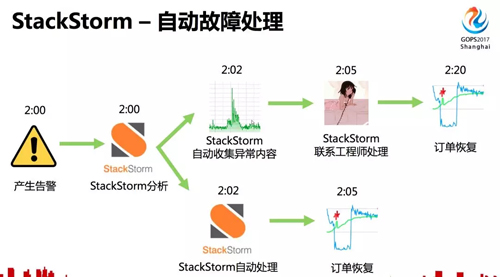
如果使用 StackStorm,故障处理的过程是怎么样的呢?
StackStorm 有 webhook 可以监听报警,当一个报警发送给 StackStorm 后,StackStorm 可以先进行一些分析,基于专家经验或者基于机器学习,分析完成之后,判断这个报警是否可以自动处理,如果可以就执行故障修复操作,故障恢复。
如果自己无法处理,会收集故障异常内容,以及初步分析结果,发送给相应的工程师,为工程师节省了一些收集信息和排查的时间,工程师可以快速进行故障修复。
对于一些常规的频繁发生的故障,如果已经有一些固定的处理方法,完全可以交给 StackStorm 自动处理。
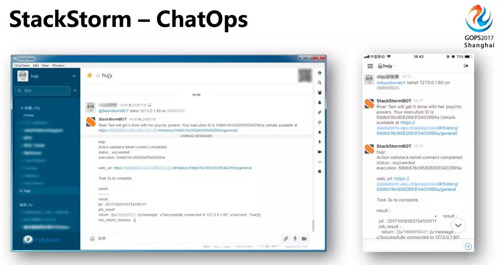
StackStorm 可以与 ChatOps 结合,进行日常运维操作,比如你正在参加 GOPS,StackStorm 将报警和初步分析发给你,你通过手机在 Chat Room 下发指令给 StackStorm,快速进行故障修复。
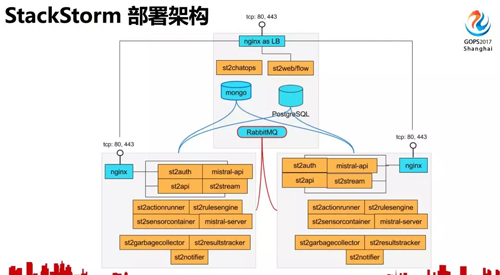
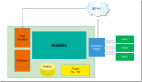
了解了 StackStorm 的一些功能,再来看看 StackStorm 的部署架构。
图中黄色的部分是 StackStorm 的主要模块,包括认证、api、规则引擎、worker、chatops、webui 等等。
mistral 作为 Workflow 引擎,以 PostgreSQL 作为数据库,MongoDB 存储 action 定义、日志,RabbitMQ 是所有任务的消息队列。这是一个高可用的架构,每一台服务器上都运行着 worker 和 mistral。
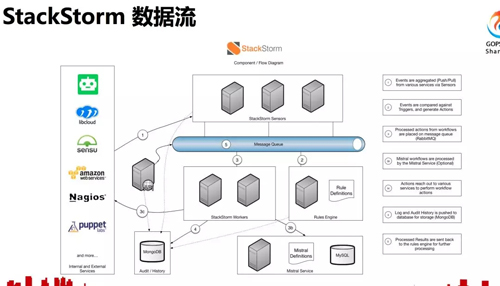
这是 StackStorm 的数据流图,StackStorm 将 chat message 对应到动作是通过这里的规则引擎,上面提到的运维原子操作组合成工作流,工作流的解析由 mistral 来完成,每一个具体 action 的执行由 worker 完成。

StackStorm 有下面三大好处:
- 提高了自动化开发效率
- 操作逻辑可视化
- 运维任何操作都有明细的记录
分批灰度

虽然 StackStorm 有很多优点,但是当你想对上万台服务器做一个操作时,你一定不会希望自己手动分批次,手动输入到 StackStorm 里面点击运行,运行如果出错,还要去看 StackStorm 不便于阅读的输出及报错堆栈。
你想要的,是建一个任务,指定一批服务器,在某个时间,执行某个任务,最后给出一个运行结果统计。所以基于大批量服务器自动操作需求,我们开发了称作 Jobs 的工具。
主要为了实现三个目标:
- 可以根据选择的分批策略自动分批,比如按服务器比例 1%、5%、10% 这样分批。
- 操作是插件化的,操作运行代码不在 Jobs 中实现,这里就要结合 StackStorm,Jobs 将命令下发给 StackStorm,具体的运行逻辑在 StackStorm 中实现。
- 可以进行结果统计,多少成功了,多少失败了,在任务详情页可以很明确地看到。
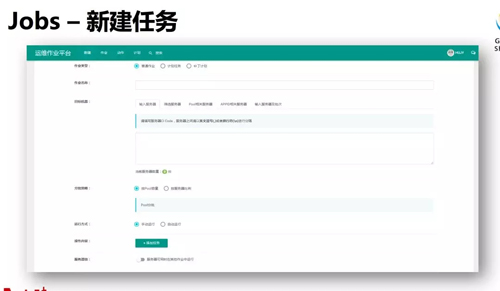
上图就是 Jobs 系统的新建任务界面,有分批策略、筛选服务器等等。
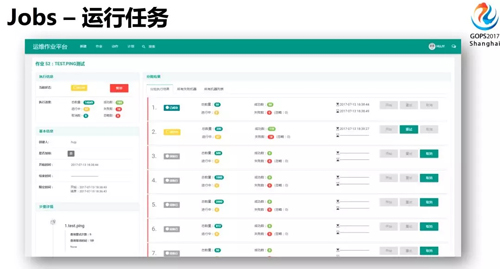
上图是 Jobs 任务详情页,左边是任务信息,右边是具体的分批的情况。分批运行任务,即使任务运行造成了故障,可以及时发现及时停止,控制影响范围。
总结
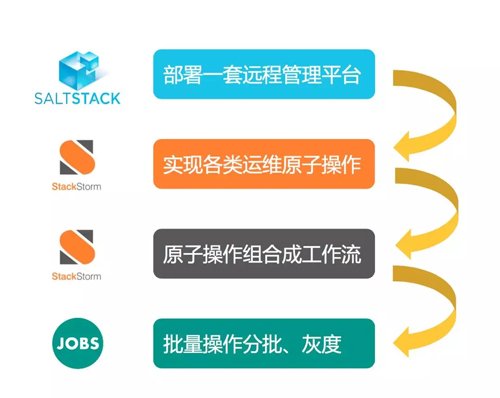
如果想搭建一套运维自动化的平台,首先部署一套远程管理框架,可以是 saltstack 或者 ansible 等。
然后在 StackStorm 上实现日常的运维原子操作,再根据具体的操作需求,将原子操作组合成工作流。
最后,对于大批量服务器运维任务,可以考虑开发一套具有分批灰度功能的系统,完成自动化操作。
胡俊雅,携程资深技术支持工程师,负责公司 SaltStack、StackStorm 等运维平台管理,运维自动化工具开发。