













引言:在运营商背景环境下,运维是阻挡不了各路大佬的规则的,当面对一个庞大组网架构,而其中包含了14种品牌厂商、30多种设备型号的网络设备时,我们一开始是拒绝的….但是***算是艰难成功了。这篇文章给大家分享一下我们是怎样实现统一自动化管理的。
1、本篇文章的目的:
- 分享一种网络运维自动化的实现过程,针对包含大量异构网络设备的组网环境。
- 运营商或者具有相似痛点的运维团队;
- 希望转型自主研发;
- 具备基础python脚本编写能力(入门快);
2、背景和痛点
我先放两张图让大家感受一下:
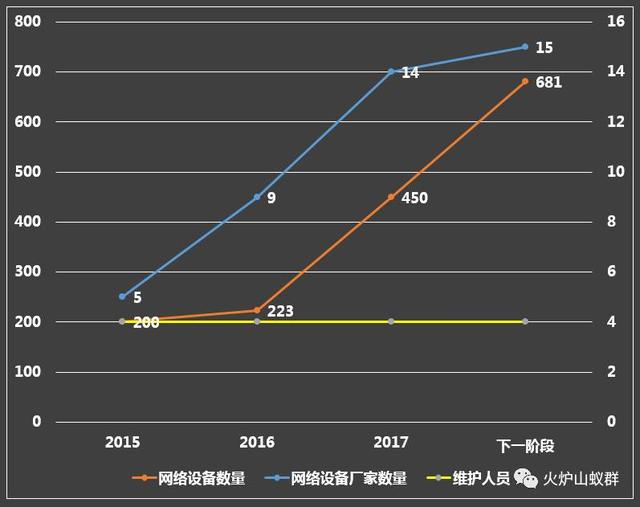

可以看到,无论设备数量和种类如何疯长,负责网络运维的一直只有四个人,老板一直无视我们的加人请求,老板一直非常相信我们的能力。
正常来说单纯地增加设备数量并不会带来多少压力,而设备厂商的增多就是另一回事儿了,不同于X86服务器挂载相同的操作系统,网络设备系统往往是封闭独立的,有着截然不同的指令手册,以及各种特殊的功能。总而言之,它们很难统一。
我再放两张图,是日常运维中很常见的场景:
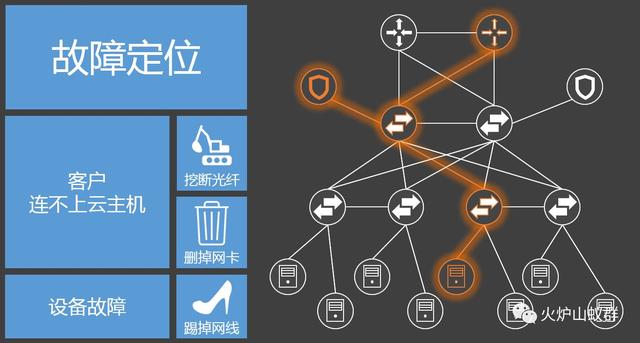
故障定位,从出口路由器一直沿路查到用户虚拟机是一件很常见的事情,这个过程中可能会经历路由器、防火墙、三层交换机、二层交换机、负载均衡器等等设备(它们来自不同的厂商)
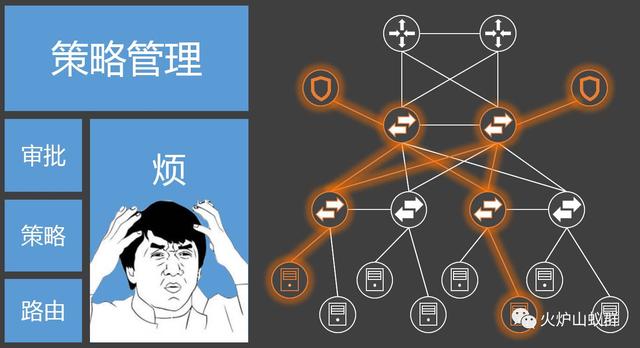
策略管理,刨去复杂的流程之外,不同的策略要定位到不同的网络域中,要在不同的防火墙上做操作(也是不同的厂商)。
如果一开始就拿这些场景去做自动化,会无从下手,或者会写出一大堆复杂重复的脚本来,效率不高;看过前面拥抱开源系列文章的同学可能会想到用现成的工具,例如Ansible,很可惜它不能管到这么多种设备。
看来只能自己动手了,接下来为了便于理解,我们不去想上面的复杂场景,用一个简单但又耗时的小场景来思考:
先看一下手工要怎么操作:

紧接着***个想到的肯定是写脚本来实现:

不错,我们已经把工作量压缩到三个脚本中了,但是这样的程度人人都可以,而且是不够的(后面会讲为什么这样是不够的),我们需要更高效,利用率更高的方法。
3、分析
在做这件事之前,让我们站在高处分析一下:
(1)我们的大团队中包含网络运维(简称运维)、平台研发(简称开发)、一线运维(简称一线)以及更多的团队。
(2)经过早期团队标准化和自动化工作的推进,运维已经具备了全员写脚本的能力,如果可以,他们更愿意自己写脚本,而非到开发那里提需求、排期,因为这样太慢了。
(3)经过早期人工运维的时期,运维已经掌握了大量的运维经验,沉淀出很多的大大小小的运维场景,每种场景需要的自动化能力是不一样的,所以如果能自己实现,运维仍然是不愿意去交给开发实现的,因为这样不仅慢,而且还可能要沟通很久。
(4)在全员实现脚本能力之前,开发是会经常收到各种各样奇怪的需求的,并且不得不排期,一个一个实现并集成到大平台中,时间久了这个平台也变得臃肿不堪,丧失功能定位。
(5)运维有一部分工作是可以前移给一线的,这样一线可以直接解决掉客户的问题,避免后续麻烦且费时的工单流转。当然,不是“免费”前移的,一线并不会深入学习这些复杂的组网架构,运维需要把场景浓缩成为简易执行的脚本或工具,才适合前移。
综上,我们应该做一个工具或者模块(我们使用python),它可以:
-
提供网络运维场景***层的各种原子操作
-
实现大部分环节自动化
-
实现异构设备的标准化封装
-
可以非常方便地自由编排,实现各种运维场景。
称呼这个模块叫做Forward,它的目的是使团队的分工模式变成这样:
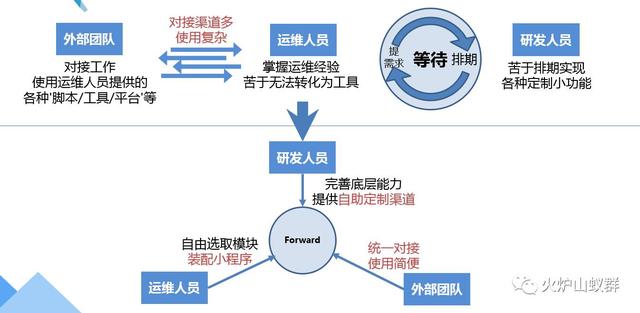
***!
开发专注于丰富底层原子操作,不再身陷各种奇怪需求中;运维可以用它自己动手、快速实现目标。
制定好目标了,然后需要决定从哪里下手,我模拟了网络运维的场景,所有场景都可以归纳为这样的步骤:
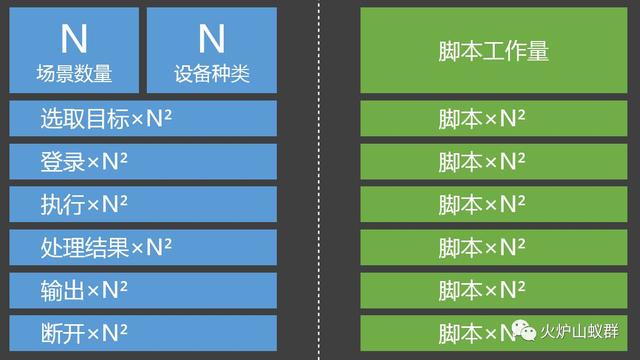
这张图也解释了为什么直接写脚本是不够的,当设备种类和维护场景都很多的时候,会浪费大量时间在脚本的重复功能上。
仔细检查上图后可以很容易分析出哪些环节适合自动化,哪些环节适合留给运维去“装配”的:
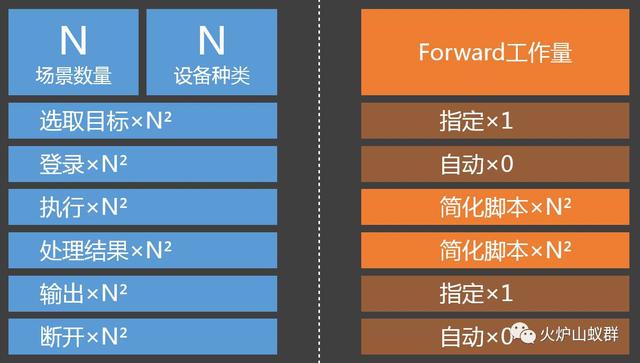
经过这样的处理后再去写脚本,就舒服多了,运维也可以在第三个、第四个环节转化自己的运维经验了。可以说:这样既体现了开发的价值,又保留了运维的发挥空间。
4、架构
为了实现Forward的目标状态,我们构思了一个简易的代码层级架构,如下图:

根据功能的特性:
-
把重复性***的原子类操作放到***层,例如底层连接协议的实现等;
-
中间层是类库封装,经过了这一层后所有设备对编程者来说就都是统一格式的类库了,屏蔽掉了异构系统差异,这一层是整个模块里比较核心的部分,下面将会用一个章节来详细介绍;
-
上层就是模块主程序层了,主要做一些流程初始化、多线程的事情(例如类库批量初始化和登录,这种密集网络IO场景非常适合PYTHON多线程),负责和编程者脚本对接。
换到宏观角度来看实现,如图:
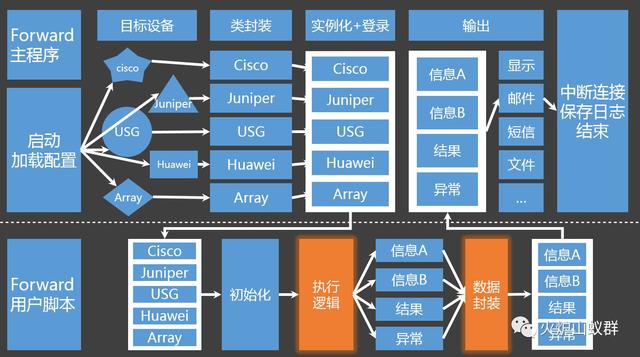
其实Forward用户只需要关注虚线以下的部分,拿到Forward返回的标准类实例后,考虑给哪个设备执行什么功能,先后顺序怎么安排,结果怎么处理等等,其他都不需要再关心了。
到目前为止,只剩一个元素没有说明白的了,那就是标准类库/标准类实例,它们是用户得以快速编排场景的前提,接下来就对它们做一个介绍。
6、统一类库
之前提到类库层是核心,我们是为了屏蔽底层网络设备异构差异、统一格式而设置的类库层,那么类库具体是什么样子?
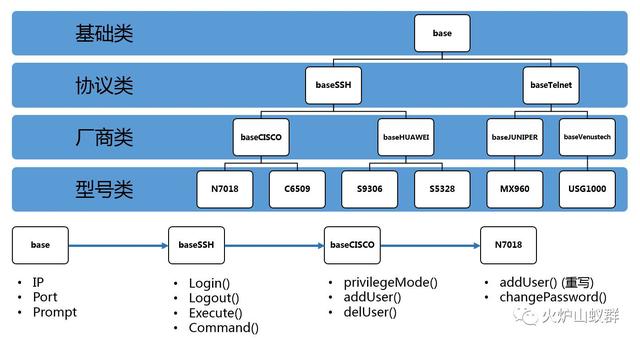
这张图表示了Forward类库层的简化继承关系,以用户管理功能为视角,可以看到从上至下的属性/方法分布,可以避免重复开发。到了最末枝的类节点时,已经有很明显的功能区别了,根据设备种类的不同,可能会包含交换器/路由器/防火墙等不同专有方法。
经过统一类库封装,不同设备添加用户的指令就简化为统一的“addUser”方法了,这是一个比较大的进步,因为我们批量添加300个账户的任务可以简化成一个几行代码的脚本了:

用户甚至都不需要知道这三种设备添加账户的指令是什么,因为它们已经封装在不同的类库中了!
7、总结
Forward的实现思路分享结束了,实现它并不难,但是需要持续投入力量去扩充类库方法以及文档。
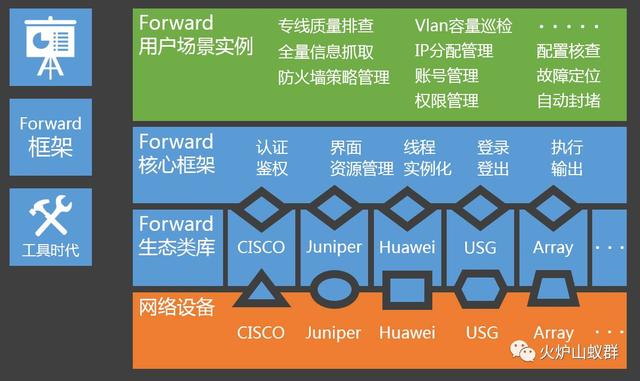
我习惯称呼这张图为“生态图”,它表示了使用Forward的网络运维生态圈,开发与运维和谐相处,每个人都有发挥空间,现在Forward各类封装场景实例调用次数已经达到万级,小到IP查询,大到故障定位都有它的身影。
结局:有了Forward助力网络运维后,老板更加无视了我们的加人请求,老板更加相信了网络运维团队的能力,然后接维了更多的网络设备…
之后还要做什么
说来说去,Forward也仅仅是一个模块而已,参考一个运维自研水平的套路:
手工 -> 脚本 -> 工具 -> 平台 -> 智能
Forward顶多可以算到工具这个级别,而在团队中和Forward同级别的运维模块已经有4个了,一个比一个棒,在上层不做一个平台就太对不起它们了,试想如果能用浏览器和鼠标完成各种运维操作,那就能前移更多的工作给一线了,那就能更高效率的完成工作了:
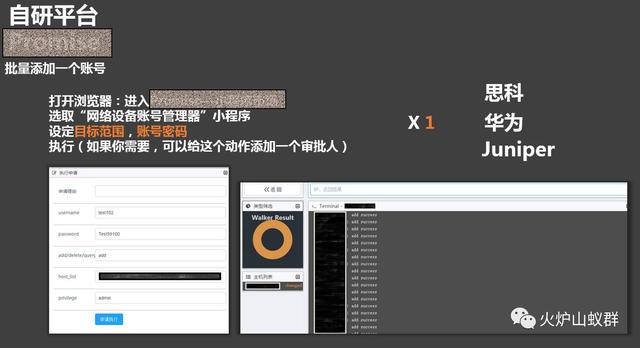
比如说前面提到的批量添加300个账户的任务,这个平台也已经实现了,我们会放到后面的文章中介绍,欢迎继续关注“火炉山蚁群”!

















