












【51CTO.com原创稿件】在这篇文章中,我们将展示如何建立一个深度神经网络,能做到以 90% 的精度来对图像进行分类,而在深度神经网络,特别是卷积神经网络兴起之前,这还是一个非常困难的问题。
深度学习是目前人工智能领域里最让人兴奋的话题之一了,它基于生物学领域的概念发展而来,现如今是一系列算法的集合。
事实已经证明深度学习在计算机视觉、自然语言处理、语音识别等很多的领域里都可以起到非常好的效果。
在过去的 6 年里,深度学习已经应用到非常广泛的领域,很多最近的技术突破,都和深度学习相关。
这里仅举几个例子:特斯拉的自动驾驶汽车、Facebook 的照片标注系统、像 Siri 或 Cortana 这样的虚拟助手、聊天机器人、能进行物体识别的相机,这些技术突破都要归功于深度学习。
在这么多的领域里,深度学习在语言理解、图像分析这种认知任务上的表现已经达到了我们人类的水平。
如何构建一个在图像分类任务上能达到 90% 精度的深度神经网络?
这个问题看似非常简单,但在深度神经网络特别是卷积神经网络(CNN)兴起之前,这是一个被计算机科学家们研究了很多年的棘手问题。
本文分为以下三个部分进行讲解:
- 展示数据集和用例,并且解释这个图像分类任务的复杂度。
- 搭建一个深度学习专用环境,这个环境搭建在 AWS 的基于 GPU 的 EC2 服务上。
- 训练两个深度学习模型:***个模型是使用 Keras 和 TensorFlow 从头开始端到端的流程,另一个模型使用是已经在大型数据集上预训练好的神经网络。
一个有趣的实例:给猫和狗的图像分类
有很多的图像数据集是专门用来给深度学习模型进行基准测试的,我在这篇文章中用到的数据集来自 Cat vs Dogs Kaggle competition,这份数据集包含了大量狗和猫的带有标签的图片。
和每一个 Kaggle 比赛一样,这份数据集也包含两个文件夹:
- 训练文件夹:它包含了 25000 张猫和狗的图片,每张图片都含有标签,这个标签是作为文件名的一部分。我们将用这个文件夹来训练和评估我们的模型。
- 测试文件夹:它包含了 12500 张图片,每张图片都以数字来命名。对于这份数据集中的每幅图片来说,我们的模型都要预测这张图片上是狗还是猫(1= 狗,0= 猫)。事实上,这些数据也被 Kaggle 用来对模型进行打分,然后在排行榜上排名。

我们观察一下这些图片的特点,这些图片各种各样,分辨率也各不相同。图片中的猫和狗形状、所处位置、体表颜色各不一样。
它们的姿态不同,有的在坐着而有的则不是,它们的情绪可能是开心的也可能是伤心的,猫可能在睡觉,而狗可能在汪汪地叫着。照片可能以任一焦距从任意角度拍下。
这些图片有着***种可能,对于我们人类来说在一系列不同种类的照片中识别出一个场景中的宠物自然是毫不费力的事情,然而这对于一台机器来说可不是一件小事。
实际上,如果要机器实现自动分类,那么我们需要知道如何强有力地描绘出猫和狗的特征,也就是说为什么我们认为这张图片中的是猫,而那张图片中的却是狗。这个需要描绘每个动物的内在特征。
深度神经网络在图像分类任务上效果很好的原因是,它们有着能够自动学习多重抽象层的能力,这些抽象层在给定一个分类任务后又可以对每个类别给出更简单的特征表示。
深度神经网络可以识别极端变化的模式,在扭曲的图像和经过简单的几何变换的图像上也有着很好的鲁棒性。让我们来看看深度神经网络如何来处理这个问题的。
配置深度学习环境
深度学习的计算量非常大,当你在自己的电脑上跑一个深度学习模型时,你就能深刻地体会到这一点。
但是如果你使用 GPUs,训练速度将会大幅加快,因为 GPUs 在处理像矩阵乘法这样的并行计算任务时非常高效,而神经网络又几乎充斥着矩阵乘法运算,所以计算性能会得到令人难以置信的提升。
我自己的电脑上并没有一个强劲的 GPU,因此我选择使用一个亚马逊云服务 (AWS) 上的虚拟机,这个虚拟机名为 p2.xlarge,它是亚马逊 EC2 的一部分。
这个虚拟机的配置包含一个 12GB 显存的英伟达GPU、一个 61GB 的 RAM、4 个 vCPU 和 2496 个 CUDA 核。
可以看到这是一台性能巨兽,让人高兴的是,我们每小时仅需花费 0.9 美元就可以使用它。当然,你还可以选择其他配置更好的虚拟机,但对于我们现在将要处理的任务来说,一台 p2.xlarge 虚拟机已经绰绰有余了。
我的虚拟机工作在 Deep Learning AMI CUDA 8 Ubuntu Version 系统上,现在让我们对这个系统有一个更清楚的了解吧。
这个系统基于一个 Ubuntu 16.04 服务器,已经包装好了所有的我们需要的深度学习框架(TensorFlow,Theano,Caffe,Keras),并且安装好了 GPU 驱动(听说自己安装驱动是噩梦般的体验)。
如果你对 AWS 不熟悉的话,你可以参考下面的两篇文章:
- https://blog.keras.io/running-jupyter-notebooks-on-gpu-on-aws-a-starter-guide.html
- https://hackernoon.com/keras-with-gpu-on-amazon-ec2-a-step-by-step-instruction-4f90364e49ac
这两篇文章可以让你知道两点:
- 建立并连接到一个 EC2 虚拟机。
- 配置网络以便远程访问 jupyter notebook。
用 TensorFlow 和 Keras 建立一个猫/狗图片分类器
环境配置好后,我们开始着手建立一个可以将猫狗图片分类的卷积神经网络,并使用到深度学习框架 TensorFlow 和 Keras。
先介绍下 Keras:Keras 是一个高层神经网络 API,它由纯 Python 编写而成并基于Tensorflow、Theano 以及 CNTK 后端,Keras 为支持快速实验而生,能够把你的 idea 迅速转换为结果。
从头开始搭建一个卷积神经网络
首先,我们设置一个端到端的 pipeline 训练 CNN,将经历如下几步:数据准备和增强、架构设计、训练和评估。
我们将绘制训练集和测试集上的损失和准确度指标图表,这将使我们能够更直观地评估模型在训练中的改进变化。
数据准备
在开始之前要做的***件事是从 Kaggle 上下载并解压训练数据集。
- %matplotlib inline
- from matplotlib import pyplot as plt
- from PIL import Image
- import numpy as np
- import os
- import cv2
- from tqdm import tqdm_notebook
- from random import shuffle
- import shutil
- import pandas as pd
我们必须重新组织数据以便让 Keras 更容易地处理它们。我们创建一个 data 文件夹,并在其中创建两个子文件夹:
- train
- validation
在上面的两个文件夹之下,每个文件夹依然包含两个子文件夹:
- cats
- dogs
***我们得到下面的文件结构:
data/
train/
dogs/
dog001.jpg
dog002.jpg
...
cats/
cat001.jpg
cat002.jpg
...
validation/
dogs/
dog001.jpg
dog002.jpg
...
cats/
cat001.jpg
cat002.jpg
这个文件结构让我们的模型知道从哪个文件夹中获取到图像和训练或测试用的标签。这里提供了一个函数允许你来重新构建这个文件树,它有 2 个参数:图像的总数目、测试集 r 的比重。
- def organize_datasets(path_to_data, n=4000, ratio=0.2):
- files = os.listdir(path_to_data)
- files = [os.path.join(path_to_data, f) for f in files]
- shuffle(files)
- files = files[:n]
- n = int(len(files) * ratio)
- val, train = files[:n], files[n:]
- shutil.rmtree('./data/')
- print('/data/ removed')
- for c in ['dogs', 'cats']:
- os.makedirs('./data/train/{0}/'.format(c))
- os.makedirs('./data/validation/{0}/'.format(c))
- print('folders created !')
- for t in tqdm_notebook(train):
- if 'cat' in t:
- shutil.copy2(t, os.path.join('.', 'data', 'train', 'cats'))
- else:
- shutil.copy2(t, os.path.join('.', 'data', 'train', 'dogs'))
- for v in tqdm_notebook(val):
- if 'cat' in v:
- shutil.copy2(v, os.path.join('.', 'data', 'validation', 'cats'))
- else:
- shutil.copy2(v, os.path.join('.', 'data', 'validation', 'dogs'))
- print('Data copied!')
我使用了:
- n:25000(整个数据集的大小)
- r:0.2
- ratio = 0.2
- n = 25000
- organize_datasets(path_to_data='./train/',n=n, ratio=ratio)
现在让我们装载 Keras 和它的依赖包吧:
- import keras
- from keras.preprocessing.image import ImageDataGenerator
- from keras_tqdm import TQDMNotebookCallback
- from keras.models import Sequential
- from keras.layers import Dense
- from keras.layers import Dropout
- from keras.layers import Flatten
- from keras.constraints import maxnorm
- from keras.optimizers import SGD
- from keras.layers.convolutional import Conv2D
- from keras.layers.convolutional import MaxPooling2D
- from keras.utils import np_utils
- from keras.callbacks import Callback
图像生成器和数据增强
在训练模型时,我们不会将整个数据集装载进内存,因为这种做法并不高效,特别是你使用的还是你自己本地的机器。
我们将用到 ImageDataGenerator 类,这个类可以***制地从训练集和测试集中批量地引入图像流。在ImageDataGenerator 类中,我们将在每个批次引入随机修改。
这个过程我们称之为数据增强(dataaugmentation)。它可以生成更多的图片使得我们的模型不会看见两张完全相同的图片。这种方法可以防止过拟合,也有助于模型保持更好的泛化性。
我们要创建两个 ImageDataGenerator 对象。train_datagen 对应训练集,val_datagen 对应测试集,两者都会对图像进行缩放,train_datagen 还将做一些其他的修改。
- batch_size = 32
- train_datagen = ImageDataGenerator(rescale=1/255.,
- shear_range=0.2,
- zoom_range=0.2,
- horizontal_flip=True
- )
- val_datagen = ImageDataGenerator(rescale=1/255.)
基于前面的两个对象,我们接着创建两个文件生成器:
- train_generator
- validation_generator
每个生成器在实时数据增强的作用下,在目录处可以生成批量的图像数据。这样,数据将会***制地循环生成。
- train_generator = train_datagen.flow_from_directory(
- './data/train/',
- target_size=(150, 150),
- batch_size=batch_size,
- class_mode='categorical')
- validation_generator = val_datagen.flow_from_directory(
- './data/validation/',
- target_size=(150, 150),
- batch_size=batch_size,
- class_mode='categorical')
- ##Found 20000 images belonging to 2 classes.
- ##Found 5000 images belonging to 2 classes.
模型结构
我将使用拥有 3 个卷积/池化层和 2 个全连接层的 CNN。3 个卷积层将分别使用 32,32,64 的 3 * 3的滤波器(fiter)。在两个全连接层,我使用了 dropout 来避免过拟合。
- model = Sequential()
- model.add(Conv2D(32, (3, 3), input_shape=(150, 150, 3), padding='same', activation='relu'))
- model.add(MaxPooling2D(pool_size=(2, 2)))
- model.add(Conv2D(32, (3, 3), padding='same', activation='relu'))
- model.add(MaxPooling2D(pool_size=(2, 2)))
- model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
- model.add(MaxPooling2D(pool_size=(2, 2)))
- model.add(Dropout(0.25))
- model.add(Flatten())
- model.add(Dense(64, activation='relu'))
- model.add(Dropout(0.5))
- model.add(Dense(2, activation='softmax'))
我使用随机梯度下降法进行优化,参数 learning rate 为 0.01,momentum 为 0.9。
- epochs = 50
- lrate = 0.01
- decay = lrate/epochs
- sgd = SGD(lr=lrate, momentum=0.9, decay=decay, nesterov=False)
- model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])
Keras 提供了一个非常方便的方法来展示模型的全貌。对每一层,我们可以看到输出的形状和可训练参数的个数。在开始拟合模型前,检查一下是个明智的选择。
model.summary()
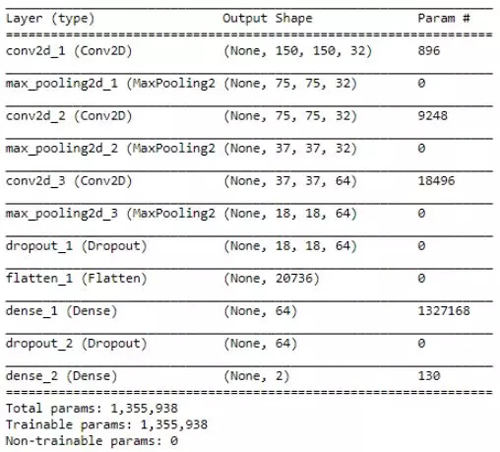
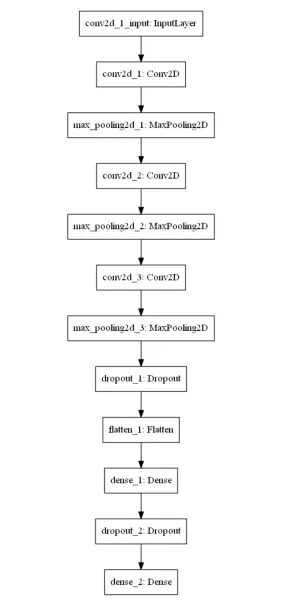
下面让我们看一下网络的结构。
结构可视化
在训练模型前,我定义了两个将在训练时调用的回调函数 (callback function):
- 一个用于在损失函数无法改进在测试数据的效果时,提前停止训练。
- 一个用于存储每个时期的损失和精确度指标:这可以用来绘制训练错误图表。
- ## Callback for loss logging per epoch
- class LossHistory(Callback):
- def on_train_begin(self, logs={}):
- self.losses = []
- self.val_losses = []
- def on_epoch_end(self, batch, logs={}):
- self.losses.append(logs.get('loss'))
- self.val_losses.append(logs.get('val_loss'))
- history = LossHistory()
- ## Callback for early stopping the training
- early_stopping = keras.callbacks.EarlyStopping(monitor='val_loss',
- min_delta=0,
- patience=2,
- verbose=0, mode='auto')
我还使用了 keras-tqdm,这是一个和 keras ***整合的非常棒的进度条。它可以让我们非常容易地监视模型的训练过程。
要想使用它,你仅需要从 keras_tqdm 中加载 TQDMNotebookCallback 类,然后将它作为第三个回调函数传递进去。
下面的图在一个简单的样例上展示了 keras-tqdm 的效果。
关于训练过程,还有几点要说的:
- 我们使用 fit_generator 方法,它是一个将生成器作为输入的变体(标准拟合方法)。
- 我们训练模型的时间超过 50 个 epoch。
- fitted_model = model.fit_generator(
- train_generator,
- steps_per_epoch= int(n * (1-ratio)) // batch_size,
- epochs=50,
- validation_data=validation_generator,
- validation_steps= int(n * ratio) // batch_size,
- callbacks=[TQDMNotebookCallback(leave_inner=True, leave_outer=True), early_stopping, history],
- verbose=0)
这个模型运行时的计算量非常大:
- 如果你在自己的电脑上跑,每个 epoch 会花费 15 分钟的时间。
- 如果你和我一样在 EC2 上的 p2.xlarge 虚拟机上跑,每个 epoch 需要花费 2 分钟的时间。
分类结果
我们在模型运行 34 个 epoch 后达到了 89.4% 的准确率(下文展示训练/测试错误和准确率),考虑到我没有花费很多时间来设计网络结构,这已经是一个很好的结果了。现在我们可以将模型保存,以备以后使用。
model.save(`./models/model4.h5)
下面我们在同一张图上绘制训练和测试中的损失指标值:
- losses, val_losses = history.losses, history.val_losses
- fig = plt.figure(figsize=(15, 5))
- plt.plot(fitted_model.history['loss'], 'g', label="train losses")
- plt.plot(fitted_model.history['val_loss'], 'r', label="val losses")
- plt.grid(True)
- plt.title('Training loss vs. Validation loss')
- plt.xlabel('Epochs')
- plt.ylabel('Loss')
- plt.legend()
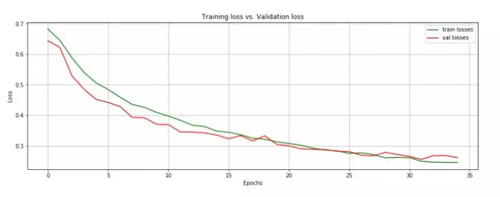
当在两个连续的 epoch 中,测试损失值没有改善时,我们就中止训练过程。
下面绘制训练集和测试集上的准确度。
- losses, val_losses = history.losses, history.val_losses
- fig = plt.figure(figsize=(15, 5))
- plt.plot(fitted_model.history['acc'], 'g', label="accuracy on train set")
- plt.plot(fitted_model.history['val_acc'], 'r', label="accuracy on validation set")
- plt.grid(True)
- plt.title('Training Accuracy vs. Validation Accuracy')
- plt.xlabel('Epochs')
- plt.ylabel('Loss')
- plt.legend()
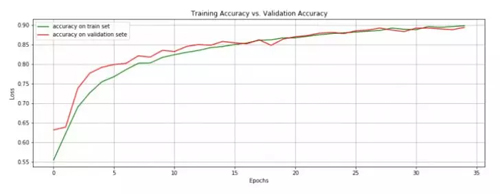
这两个指标一直是增长的,直到模型即将开始过拟合的平稳期。
装载预训练的模型
我们在自己设计的 CNN 上取得了不错的结果,但还有一种方法能让我们取得更高的分数:直接载入一个在大型数据集上预训练过的卷积神经网络的权重,这个大型数据集包含 1000 个种类的猫和狗的图片。
这样的网络会学习到与我们分类任务相关的特征。
我将加载 VGG16 网络的权重,具体来说,我要将网络权重加载到所有的卷积层。这个网络部分将作为一个特征检测器来检测我们将要添加到全连接层的特征。
与 LeNet5 相比,VGG16 是一个非常大的网络,它有 16 个可以训练权重的层和 1.4 亿个参数。要了解有关 VGG16 的信息,请参阅此篇 pdf 链接:https://arxiv.org/pdf/1409.1556.pdf
- from keras import applications
- # include_top: whether to include the 3 fully-connected layers at the top of the network.
- model = applications.VGG16(include_top=False, weights='imagenet')
- datagen = ImageDataGenerator(rescale=1. / 255)
现在我们将图像传进网络来得到特征表示,这些特征表示将会作为神经网络分类器的输入。
- generator = datagen.flow_from_directory('./data/train/',
- target_size=(150, 150),
- batch_size=batch_size,
- class_mode=None,
- shuffle=False)
- bottleneck_features_train = model.predict_generator(generator, int(n * (1 - ratio)) // batch_size)
- np.save(open('./features/bottleneck_features_train.npy', 'wb'), bottleneck_features_train)
- ##Found 20000 images belonging to 2 classes.
- generator = datagen.flow_from_directory('./data/validation/',
- target_size=(150, 150),
- batch_size=batch_size,
- class_mode=None,
- shuffle=False)
- bottleneck_features_validation = model.predict_generator(generator, int(n * ratio) // batch_size,)
- np.save('./features/bottleneck_features_validation.npy', bottleneck_features_validation)
- ##Found 5000 images belonging to 2 classes.
图像在传递到网络中时是有序传递的,所以我们可以很容易地为每张图片关联上标签。
- train_data = np.load('./features/bottleneck_features_train.npy')
- train_labels = np.array([0] * (int((1-ratio) * n) // 2) + [1] * (int((1 - ratio) * n) // 2))
- validation_data = np.load('./features/bottleneck_features_validation.npy')
- validation_labels = np.array([0] * (int(ratio * n) // 2) + [1] * (int(ratio * n) // 2))
现在我们设计了一个小型的全连接神经网络,附加上从 VGG16 中抽取到的特征,我们将它作为 CNN 的分类部分。
- model = Sequential()
- model.add(Flatten(input_shape=train_data.shape[1:]))
- model.add(Dense(512, activation='relu'))
- model.add(Dropout(0.5))
- model.add(Dense(256, activation='relu'))
- model.add(Dropout(0.2))
- model.add(Dense(1, activation='sigmoid'))
- model.compile(optimizer='rmsprop',
- loss='binary_crossentropy', metrics=['accuracy'])
- fitted_model = model.fit(train_data, train_labels,
- epochs=15,
- batch_size=batch_size,
- validation_data=(validation_data, validation_labels[:validation_data.shape[0]]),
- verbose=0,
- callbacks=[TQDMNotebookCallback(leave_inner=True, leave_outer=False), history])
在 15 个 epoch 后,模型就达到了 90.7% 的准确度。这个结果已经很好了,注意现在每个 epoch 在我自己的电脑上跑也仅需 1 分钟。
- fig = plt.figure(figsize=(15, 5))
- plt.plot(fitted_model.history['loss'], 'g', label="train losses")
- plt.plot(fitted_model.history['val_loss'], 'r', label="val losses")
- plt.grid(True)
- plt.title('Training loss vs. Validation loss - VGG16')
- plt.xlabel('Epochs')
- plt.ylabel('Loss')
- plt.legend()
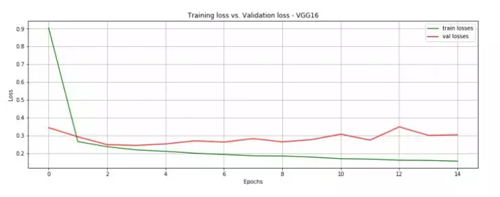
- fig = plt.figure(figsize=(15, 5))
- plt.plot(fitted_model.history['acc'], 'g', label="accuracy on train set")
- plt.plot(fitted_model.history['val_acc'], 'r', label="accuracy on validation sete")
- plt.grid(True)
- plt.title('Training Accuracy vs. Validation Accuracy - VGG16')
- plt.xlabel('Epochs')
- plt.ylabel('Loss')
- plt.legend()
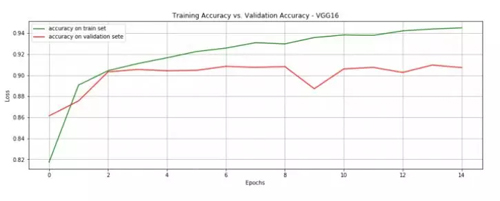
许多深度学习领域的大牛人物都鼓励大家在做分类任务时使用预训练网络,实际上,预训练网络通常使用的是在一个非常大的数据集上生成的非常大的网络。
而 Keras 可以让我们很轻易地下载像 VGG16、GoogleNet、ResNet 这样的预训练网络。想要了解更多关于这方面的信息,请参考这里:https://keras.io/applications/
有一句很棒的格言是:不要成为英雄!不要重复发明轮子!使用预训练网络吧!
接下来还可以做什么?
如果你对改进一个传统 CNN 感兴趣的话,你可以:
- 在数据集层面上,引入更多增强数据。
- 研究一下网络超参数(network hyperparameter):卷积层的个数、滤波器的个数和大小,在每种组合后要测试一下效果。
- 改变优化方法。
- 尝试不同的损失函数。
- 使用更多的全连接层。
- 引入更多的 aggressive dropout。
如果你对使用预训练网络获得更好的分类结果感兴趣的话,你可以尝试:
- 使用不同的网络结构。
- 使用更多包含更多隐藏单元的全连接层。
如果你想知道 CNN 这个深度学习模型到底学习到了什么东西,你可以:
- 将 feature maps 可视化。
- 可以参考:https://arxiv.org/pdf/1311.2901.pdf
如果你想使用训练过的模型:
- 可以将模型放到 Web APP 上,使用新的猫和狗的图像来进行测试。这也是一个很好地测试模型泛化性的好方法。
总结
这是一篇手把手教你在 AWS 上搭建深度学习环境的教程,并且教你怎样从头开始建立一个端到端的模型,另外本文也教了你怎样基于一个预训练的网络来搭建一个 CNN 模型。
用 Python 来做深度学习是让人愉悦的事情,而 Keras 让数据的预处理和网络层的搭建变得更加简单。
如果有一天你需要按自己的想法来搭建一个神经网络,你可能需要用到其他的深度学习框架。
现在在自然语言处理领域,也有很多人开始使用卷积神经网络了,下面是一些基于此的工作:
使用了 CNN 的文本分类:
https://chara.cs.illinois.edu/sites/sp16-cs591txt/files/0226-presentation.pdf
自动为图像生成标题:
https://cs.stanford.edu/people/karpathy/sfmltalk.pdf
字级别的文本分类:
https://papers.nips.cc/paper/5782-character-level-convolutional-networks-fortext-classification.pdf
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】



















