一、豆瓣音乐
今天爬的是豆瓣音乐top250,比较简单,主要是练练手。
1、加了请求头,本来没加,调试几次突然没数据了,加了请求头开始也没好,后来又好了,可能是网络原因;
2、这次是进入信息页爬的数据,上次爬电影没采用这种方法,缺少了部分数据;
3、数据的预处理用了很多if函数
数据分析
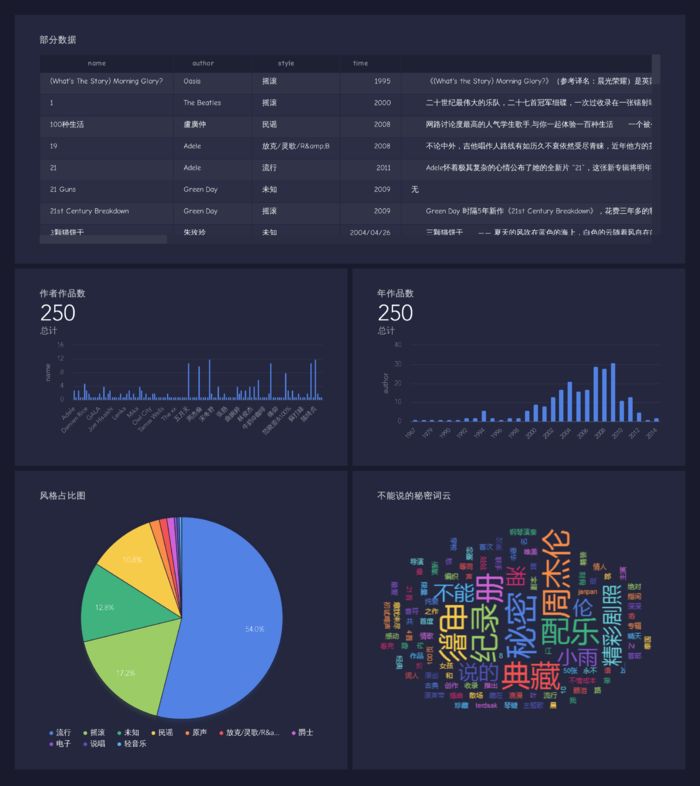
1、部分数据可以见上图
2、中国音乐作者还是很多的。
3、随着音乐设备和网络的普及,流行音乐的发展,可以看出2000年后作品越来越多,到2010年又积极下滑(经典就是经典,无法吐槽现在的音乐)
4、风格大家可以看出流行,摇滚,民谣占了一大半。
5、最后弄了一首周董的《不能说的秘密》做词云,想想小时候都是回忆啊。
代码片段
- import requests
- import re
- from bs4 import BeautifulSoup
- import time
- import pymongo
- client = pymongo.MongoClient('localhost', 27017)
- douban = client['douban']
- musictop = douban['musictop']
- headers = {
- 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
- }
- urls = ['https://music.douban.com/top250?start={}'.format(str(i)) for i in range ( 0 , 250 , 25 )]
- def get_url_music ( url ):
- wb_data = requests . get ( url , headers = headers )
- soup = BeautifulSoup ( wb_data . text , 'lxml' )
- music_hrefs = soup . select ( 'a.nbg' )
- for music_href in music_hrefs :
- get_music_info ( music_href [ 'href' ])
- time . sleep ( 2 )
二、微打赏
网站分析
打开网站,翻页网页不变,看看是post的请求,很好办,直接把参数怼进去,这里只要切换page就能进行翻页。
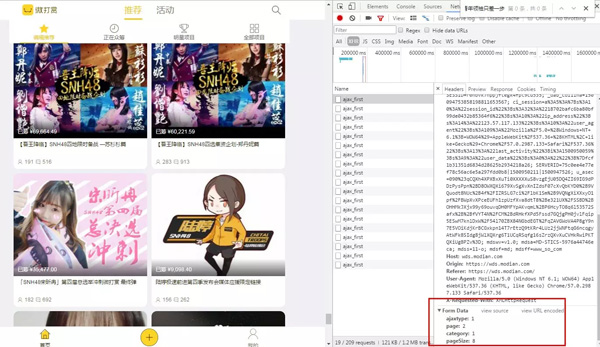
json格式,这里post返回的是json数据,解析json数据就行,小技巧:看preview,解析起来嗖嗖哒。这里需要提取活动的名称,id和参与打赏的人数。这个后面详细页用的到。
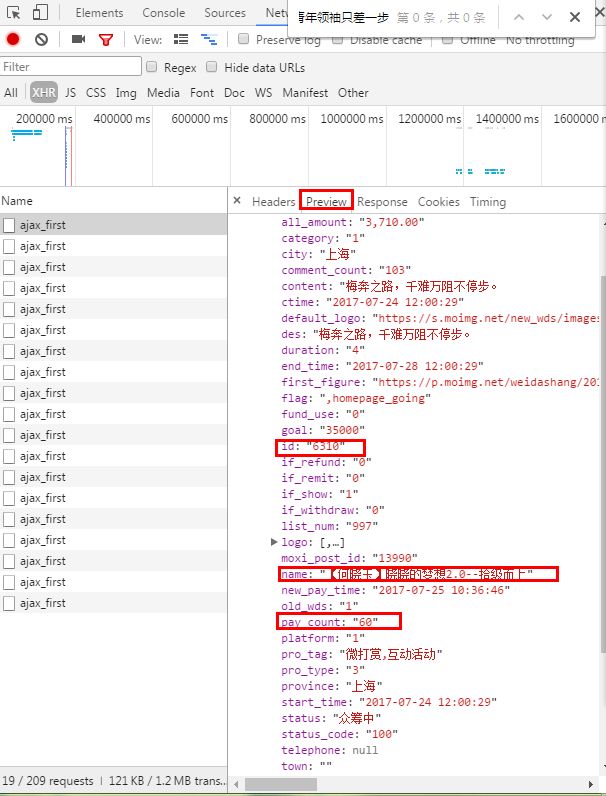
详细页,依旧是post,依旧是json数据,这里的参数pro_id为之前的爬取的id,这一页20个信息,通过前面的参与打赏人数构造出有多少页,继续怼参数。
代码片段
- import requests
- import json
- import math
- def get_sup_info ( url , page ):
- params = {
- 'ajaxtype' : 1 ,
- 'page' : page ,
- 'category' : 1 ,
- 'pageSize' : 8
- }
- cookies = {
- 'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36' ,
- 'Cookie': 'acw_tc=AQAAAKLQ3U/WTAYAggq7PZ24WOlm9vQW; PHPSESSID=r0nbvk7hppjftegk4fpt9cu535; _uab_collina=150094753858198811653567; mdswv=v1.0; mdsa=MD-STICS-5976a44746eca; mdss=6-o; mdsf=md; mdsff=www_so_com;
- }
- html = requests.post(url, data=params, headers=cookies)
- json_data = json.loads(html.text)
- des = json_data[' des ']
- for data in des:
- name = data[' name ']
- id = data[' id ']
- pay_count = data[' pay_count ']
- all_page = math.ceil(int(pay_count)/20)
- for i in range(1,int(all_page)+1):
- get_app_info(i,id,name)
三、阳光电影
爬虫分析
这里涉及跨页的爬取,需要理清爬虫的思路。首先打开网站,需爬取前11个分类的电影数据,经典影片格式不一样,爬虫时过滤掉了。
进入电影列表页后,正则爬取页数和电影的分类标签,以此构造分页url,然后爬取电影的名字和url。
最后在详细页爬取电影的下载地址,爬取结果如下:

代码片段
- import requests
- import re
- from lxml import etree
- import csv
- def get_resource(url,cate_name,cate_url,movie_name):
- res = requests.get(url)
- res.encoding = 'gb2312'
- html = etree.HTML(res.text)
- movie_resource = html.xpath('//tbody//tr/td/a/text()')[0]
- writer.writerow((cate_name,cate_url,movie_name,url,movie_resource))
- print(movie_resource)