近期大家都在讨论 Paxos 算法,我看了很多网上的文章,总觉得有些晦涩难懂,经过一段时间研究,对 Paxos 有了一些理解,在这里总结一下,希望能抛砖引玉。
为什么需要 Paxos
Paxos 要解决的问题,是分布式系统中的一致性问题。那么到底什么是“分布式系统中的一致性问题”呢?
在分布式系统中,为了保证数据的高可用,通常,我们会将数据保留多个副本(replica),这些副本会放置在不同的物理的机器上。
副本要保持一致,那么,所有副本的更新序列就要保持一致。因为数据的增删改查操作一般都存在多个客户端并发操作,到底哪个客户端先做,哪个客户端后做,更新顺序要保证。
如果不是分布式,那么可以通过加锁的方法,谁先申请到锁谁就先操作,但这就存在单点问题。
Paxos 协议主要有两种用法:
- 用来实现全局的锁服务或者命名和配置服务,例如 Google Chubby 以及 Apache ZooKeeper。
- 用它来将用户数据复制到多个数据中心,例如 Google Megastore 以及 Google Spanner。
以一个分布式的 KV 数据库为例,假设数据库对外提供 2 种操作 Put 和 Get,具体架构如下:
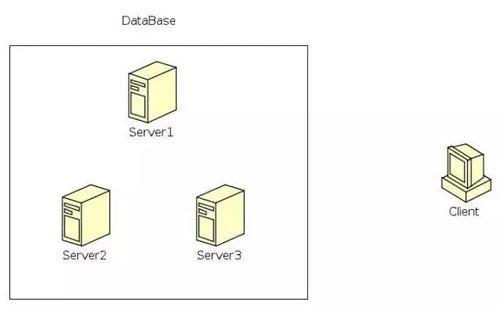
在这样一个架构下,可以通过多台 Server 组成集群来避免单点问题。
我们需要解决的是 3 台 Server 必须保持同步,也就是说,如果向集群发送请求 Put(“a”,1)并成功,那么整个集群任意一台 Server 必须含有("a",1)。
另外假设此时多个 client 并发访问集群,不同客户端的请求可能会落入到不同的 Server 机器上。
比如并发有 Put("b”,2)和 Put(“c”,3),我们需要保证哪个客户端请求先做,哪个后做,保证更新顺序,这就是 Paxos 算法需要解决的问题。
大白话理解 Paxos 算法
我们先来简单描述一下 Paxos 算法,对算法本身有一个直观的认识,然后再结合后面的例子来进一步理解。
在 Paxos 算法中,主要有 3 种角色:
- Proposer:提议者
- Acceptor:决策者
- Learner:最终决策学习者
实现的时候往往采用一组固定数目的 Server,每个 Server 同时担任上述三个角色。
Paxos算法分为以下三个阶段:
Prepare 阶段
Proposer 向大多数 Acceptor 发起 Proposal(epochNo,value)的 Prepare 请求。
Acceptor 收到 Prepare 请求,如果 epochNo 比之前接收到的小,直接拒绝;如果 epochNo 比之前已经接收的大,就将已经接收到的 epochNo ***的 Proposal 返回到 Proposer。
Proposer 发起的 Proposal 至少要收到大多数以上的 Acceptor 的 Prepare 应答后,才能进入接下来的 Accept 阶段,否则需要重新进行 Prepare 阶段向大多数 Acceptor 发起 Prepare 请求。
Accept 阶段
Proposer 收到大多数的 Acceptor 的 Prepare 应答后,看 Acceptor 是否已经有被接受的 Proposal。
如果没有已经接受的 Proposal,就自己提出一个 Proposal,发起 Accept 请求;如果已经有被接受的 Proposal,就从中选出 epochNo ***的 Proposal,发起对该 Proposal 的 Accept 请求。
Acceptor 收到请求后,如果该 Proposal 的 epochNo 比它***一次应答 Prepare 请求的 epochNo 要大,那么就接受该请求;否则拒绝该请求。
Learn 阶段
所有 Acceptor 接受的 Proposal 要不断通知 Learner,或者 Learner 主动去查询,一旦 Learner 确认 Proposal 被大多数的 Acceptor 接受。
那么表示这个 Proposal 的 Value 被 Chosen,Learner 就可以学习这个 Proposal 的 Value,同时自己的 Sever 上就不再受理 Proposor 的请求。
我喜欢通过例子来理解理论,理论源于生活,下面我以生活中的例子来进行该算法的描述。
假设一群驴友决定春节去旅游,驴友遍布全国各地,一共 10 人,为了能达成一致,这 10 个人另外找 5 个作为队长。5 个队长之间相互不通信,只跟 10 个驴友发短信。
***阶段(申请阶段),驴友发短信给 5 个队长,申请与队长进行沟通,队长在任何时刻只能与一个驴友沟通。
发送的每条短信都带有时间,队长采用的原则是同意与短信发送时间***的驴友沟通。
如果出现更新的短信,则与短信更新的驴友沟通。至少大多数队长同意沟通了,这个驴友才能进入第二阶段实质性沟通。
第二阶段(沟通阶段),获得沟通权的驴友 A 收到队长们给他发的旅游地,可能有如下几种情况:
***种情况:沟通的队长们全部都还没有决定到底去哪里旅游,此刻驴友 A 会把自己想去的旅游地发给队长们(比如马尔代夫)。
结果可能大多数队长同意了,整个过程执行完毕,就是去马尔代夫旅游了,其他的驴友迟早会知道。
除此之外就表明失败了,可能队长没有回复(跟女友打电话去了),可能被其他驴友抢占沟通权了(上面说过队长只跟***的短信的人进行沟通)。
如果失败了,A 需要重新开始***阶段申请,重新给队长们发短信申请沟通权。
第二种情况:至少有一个队长已经决定旅游地了,这个时候 A 会收到不同队长决定的多个旅游地,这些旅游地是不同队长跟不同驴友在不同时间做的决定。
A 会先看看有的旅游地是不是被大多数(半数以上)队长同意了,如果有(这里假设 3 个队长决定去三亚,一个去拉萨,另外可能某种原因没搭理),那证明整个决定过程已经达成一致了,A 收拾收拾去三亚吧,结束!
如果都没有达到半数(比如 2 个去三亚,1 个去拉萨,1 个去昆明,1 个没搭理),这时候 A 可能想去马尔代夫,但也不按照自己意愿乱来了(这里是 Paxos 的关键所在,后者认可前者,否则整个过程无止境了)。
A 会根据收到队长的所有旅游地中找到***的那个决定地(比如去昆明是那个队长在 1 分钟前决定的,去拉萨的队长是半小时前决定的,去三亚的队长是 1 小时前决定的),于是 A 顶***的决定,去昆明。
这时候去昆明的决定又更新了,这样下一个抢到沟通权的驴友也很大可能会顶去昆明,这样决定去昆明的队长会越来越多。
一旦某个时刻大多数(半数以上),队长都同意了去某个地点,比如去昆明,后续获得沟通权的驴友 B 会发现大多数队长都决定去昆明了,它也会服从,最终所有的驴友都达成一致去昆明。
Paxos 的基本思想大致就是上面过程,Paxos 利用的是选举,少数服从多数的思想。
只要 N 个(N 为奇数,至少大于等于 3)节点中,有[N/2]+1(这里N/2为向下取整)或以上个节点同意了某个决定,则认为系统达到了一致。
这样的话,客户端不必与所有服务器通信,选择与大部分通信即可;也无需服务器都全部处于工作状态,有一些服务器挂掉,只有保证半数以上存活着,整个过程也能持续下去,容错性相当好。
Paxos 中的 Acceptor 相当于上面的队长,Proposer 相当于上面的驴友,epochNo 号就相当于例子中申请短信的发送时间。
Paxos 最消耗时间的地方就在于需要半数以上同意沟通了才能进入第二步。
试想一下,一开始,所有驴友就给队长狂发短信,每个队长收到的***短信来自不同驴友。
这样,就难以达到半数以上都同意与某个驴友沟通的状态,为了减小这个时间,Paxos 还有 Fast Paxos 的改进等等。
另外,Paxos 并不指代一个协议,而是一类协议的统称,比较常见的 Paxos类协议有:basic paxos 和 multi-paxos。
这里的例子说的是 basic paxos,basic paxos 协议较复杂,且相对效率较低,所以现在所有和 paxos 有关的协议的系统,一般都是基于 multi-paxos 来实现的。
有兴趣了解可以参考文章:https://zhuanlan.zhihu.com/p/25664121
Paxos 在数据库高可用上的使用
作为 DBA,为了实现高可用,最常用的高可用方式是主从模式,以 MySQL 为例,主要有如下几种:
强同步复制
binlog 同步到从库之后,从库返回给主库 ok 之后才能返回给客户端提交成功。
这就有个问题,一旦主从之间网络出现抖动,甚至从库宕机,则主库就无法再继续提供服务,这种模式实现了数据的强一致,但是牺牲了服务的可用性。
异步复制
主库写本地成功后,立刻返回给客户端说成功,无需等待从库应答。
这样一旦主库宕机,可能会有少量的日志没有同步到从库造成部分数据丢失,这种模式可用性很好,但是牺牲了数据的一致性。
半同步复制
这种模式是一个折中,主要指至少有一个从库节点收到日志返回给主库 ok 之后,这时就可以返回给客户端提交成功,当网络环境不好的时候可能退化为异步复制。
另外主从模式还有一个无法绕过的问题,就是选主,为了主从模式的选主,长期以来也诞生了很多种高可用方案,如 MMM、MHA、中间层等等,但显然理论和思路都不是***进的。
总结一下,针对主从方式处理数据库高可用有诸多缺陷,要想改进这种数据同步方式,可以梳理数据库高可用的几点需求:
- 数据不丢失
- 服务持续可用性
- 自动选主
- 自动容错
使用 Paxos 协议的日志同步就可以实现以上的三个需求,当然 Paxos 协议需要依赖一个基本假设。
主备之间有多数派机器(N/2+1)是存活且它们之间的网络通讯正常,如果不满足这个条件,则无法启动服务,数据也无法写入和读取。
所以我们可以使用 Paxos 进行 redolog 或者 binlog 的复制,从而保证高可用强一致的集群。
主从的切换也不需要担心,只需要有个 vip,后端映射后面数据库的多点就行,Paxos 会自动保证多点的一致性写入,业界阿里云使用 Paxos 或者 raft 来做的企业三节点的 MySQL 集群。
蒲聪,平台事业部 DBA,2013 年 6 月加入去哪儿网,目前负责支付平台事业部的 MySQL 数据库和 HBase 整体的运维工作,从无到有建立去哪儿网 HBase 运维体系,在 MySQL 和 Hbase 数据库上有丰富的架构、调优和故障处理等经验。目前专注于分布式数据库领域的研究和实践工作。