













明确维度定义后,还可以换一种更清晰的方式来审视数据库的结构。
这是我们常见的E-R图:

E-R图是个网状结构,实体(表)之间的外键关系直接画在图上,当实体较多时这个图就会显得非常零乱,关联线很随意,任何两个实体之间都有可能发生关联,表现出来的数据结构耦合度很高。在增加删除实体时就要考虑与之关联的所有其它实体,很可能发生遗漏关联或循环关联的现象。
一
而如果把维度抽取出来之后,我们可以使用总线式的结构图:
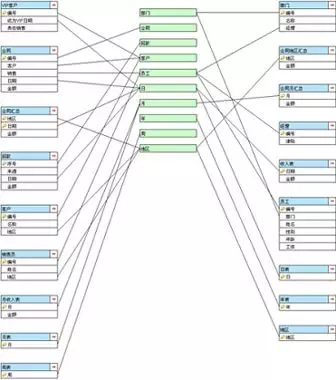
所有维度单独列出来处于中心地位,实体(表)只和维度发生关联,实体之间没有直接的关联线,数据结构的耦合度看起来很低。增加删除实体时不会影响到其它实体,不会发生遗漏关联和重复关联。
不过,需要指出的是。无论是E-R图还是总线图,只要画正确时,其中的关联线数量是差不多的,这是数据本身的关系决定的。总线图并不会比E-R中的关联线更少,但改变了看待方法后会更清晰。
二
为了提供关联查询能力,有些BI产品将表间关联关系(相当于一个局部E-R图)直接暴露给业务人员,这不是个好办法,业务人员难以理解E-R图,这个方案的可用性很差。如果能够由业务人员选择了数据项(字段)后就自动建立出合理的关联,那样可用性就能提高很多了。
有了维度概念,就可以一定程度地实现这一目标。
业务人员任意选择了字段之后,我们可以找出这些字段所在表,再在这些表之间寻找同维字段(优先选择主键),然后使用这些同维字段建立JOIN关系。当某个表上只有***的字段和另一表的主键字段同维时,那么基于这两个字段建立的JOIN关系在绝大多数情况下都是正确合理的。而且,在数据结构不是特别复杂的时候,两表之间只有***字段同维的条件也常常能够满足,这时候就真地能只基于数据项自动建立正确的关联关系,有些BI产品确实是这么做的。
不过,这种办法不能处理同表自关联和表间有多个同维字段的情况,以及多次递归关联的问题。想要完善地解决问题,还是需要基于DQL语法来实现关联。
三
上面的讨论中,我们会把发现的同维字段JOIN起来,DQL语法也是这样,只要同维的(广义)字段就可以JOIN。这样的JOIN一定有业务意义吗?
是的,只要是同维字段,JOIN起来总能想出合理业务意义。反过来,也只有同维字段之间可以JOIN,不同维字段的JOIN是没有业务意义的,不过SQL并不禁止,只要数据类型相同就可以JOIN。字段同维和JOIN有业务意义是等价的,DQL在这方面可以确保这一点。
DQL中GROUP BY总是要对应着ON(如果单表可以看成是省略ON),也就是说,GROUP BY总是针对某个维度进行的。事实上也是这样,针对测度的分组运算没有业务意义,不过SQL并没有明确出维度和测度的概念,也不会禁止这个运算。DQL则确保了不会发生无业务意义的分组。
利用这个特点,可以提高分组运算的性能。维度可能的取值是由维表长度决定的,而维表是事先知道的,这样在分组时可以采用类似基数排序法的手段提速,当然,针对维度的排序运算也可以用这种办法。不过,这个算法细节与本篇主题相关性较低,这里就不详细说明了。






















