












【51CTO.com快译】虽然当前有很多种方法可以为您构建出物联网(IoT)的数据部署架构,但是往往适合于某一家企业的架构并不一定适合另一家。虽然根据物联网项目的大小不同和复杂程度,有着许多种组件可供您选择,但是它们往往会形成一种相似的架构,即:部署各个传感器的收集器或IoT网关设备,从多个传感器节点那里收集数据,然后转发到企业的上游数据收集之中。
这些网关或收集器设备通常会使用ZWave(译者注:智能家居领域的无线组网规格)设备来接入到互联网进行数据上传,或者桥接各种蓝牙设备与WiFi,以及使用其他的网络连接。
不过,大多数这些网关或收集器设备往往是“哑”网关类型。它们除了向上游收集器做转发之外,不做任何事情。那么我们是否能够将IoT网关转变成为一台智能设备呢?使您在发送数据之前,能够在收集器设备上进行本地分析和数据处理。如果能够实现的话,势必会非常有用!
构建网关
在我决定构建(另一个)物联网智能网关设备之前,我已经(在某种程度上)建立了一个运行着InfluxDB(译者注:InfluxDB是一个当下比较流行的时序数据库,它使用Go语言来编写)的ARTIK-520设备。但是,这个ARTIK-520并不是***的,而大家在建立物联网设备的时候,经常会追求越便宜越好的原则。虽然实际情况并非总是如此,但是当您建立的网关越来越多的时候,就需要考虑到成本因素了。
我翻出了几年前购买的Pine-64(译者注:Pine-64是一款64位的软硬件开源平台,属于卡片电脑,更多信息请浏览https://www.pine64.org/),开始了自己的尝试。您一定会问:为什么是Pine-64,而不是树莓派(Raspberry Pi)呢?因为Pine-64只有一半的成本,它只要15美元而不是树莓派的35美元,就这么简单。
而且我的Pine-64有着同等配置的ARM A53四核1.2GHz的处理器和2GB的内存。相比于树莓派的1GB内存来说,我在各种使用过程中会获得更为强大的GPU。另外,它还自带内置的WiFi,不过没有加密狗。我选配了ZWave板卡,因此可以与sub-GHz(译者注:频率为1GHz以下,27MHz~960MHz)的物联网设备进行通信。
运用此类的设备作为IoT网关的一个好处是:您只会受到所用microSD卡容量大小的限制。比如说我只使用了16GB的SD卡,而Pine-64却能够支持高达256GB的存储卡。
怎样才能实现TICK(译者注:Telegraf、InfluxDB、Chronograf和Kapacitor的缩写,分别代表数据采集、数据存储、数据可视化和监控告警),并运行在Pine-64上呢?我建议您使用Xenial的镜像来启动并运行Pine-64。因为它是Pine-64的“官方”Ubuntu版本,所以它非常适用于InfluxDB。请不要忘记运行如下命令:
- apt-get upgrade
一旦它启动并运行起来,您要确保各个组件都已做好更新。
接下来,需要将Influx的各个存储库加载到apt-get:
- curl -sL https://repos.influxdata.com/influxdb.key | apt-key add -
- source /etc/lsb-release
- echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | tee -a /etc/apt/sources.list
您可能需要使用sudo来运行它们,而这里我巧妙地使用了“sudo bash”来使之启动,并保证一切就绪。
接下来,您需要添加一个“必需”的包,来访问InfluxData的存储库:
- apt-get install apt-transport-https
之后就是:
- apt-get install influxdb chronograf telegraf kapacitor
现在我们已经准备进入下一步了!
负载测试设备
我的原始想法只是想看看,在这么小的设备上添加了负载后,它的处理情况是怎样的。因此我从GitHub网站上(https://github.com/influxdata/influx-stress)下载了“influx-stress”并将它运行在该设备上。
- Using batch size of 10000 line(s)
- Spreading writes across 100000 series
- Throttling output to ~200000 points/sec
- Using 20 concurrent writer(s)
- Running until ~18446744073709551615 points sent or until ~2562047h47m16.854775807s has elapsed
哇,它达到了每秒200,000个点!事实证明它的确给Pine-64产生了严重的压力!
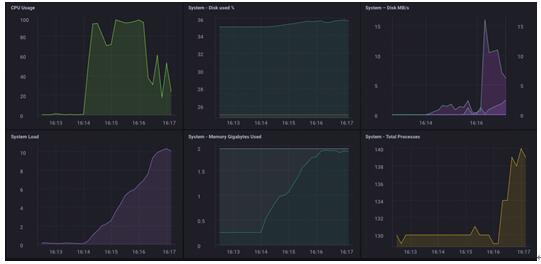
正如您所看到的,它很快接近用光了2GB的内存,并且CPU的使用率也是100%。当然在现实生活中,作为一台网关设备,碰到这样的负荷几乎是不可能的,它一般只会从几十到上百个传感器那里收集数据。
本地分析
正如您从上述仪表盘所看的,我能够轻松地在本地对Pine-64进行分析。同时,它拥有一个板载的HDMI接口和一个完整的GPU,这使得本地访问仪表盘,以及实时监测就变得相当简单了。正如我上面提到的,如果设备能够处理更多的工作,就会显得更有用。
理想状态下,您可能需要收集所有的数据到一台网关设备上,并实现各种本地分析、报警等功能。但是在现实世界中,这并不是网关/收集器所应该具有的,我们应该将各种处理作业“移”出去,即向上游转发数据。
降低物联网数据的采样率
如果只是简单地使用一台网关设备向上游转发所有的数据,那将非常的容易。但是如果您需要处理网络连接问题,或者是想节约花销与带宽的话,您就会希望在转发数据之前降低数据的采样率(data downsampling)。幸运的是一般比较实用的IoT设备都有能力进行各种本地分析、本地警报处理,以及在上游转发之前进行数据采样。而且实现起来并不困难!
首先,让我们搭建一台自己的网关设备,使之能够向上转发数据到InfluxDB的另一个实例中。虽然有好几种方法可以做到这一点,但是鉴于我们将通过Kapacitor来降低数据采样率,因此我们在此直接使用kapacitor.conf文件来实现。在该kapacitor.conf文件中,已经有一个部分带有“localhost”的[[influxdb]]条目,所以我们只需要添加一个新的[[influxdb]]部分服务于上游实例便可。如下所示:
- [[influxdb]]
- enabled = true
- name = "mycluster"
- default = false
- urls = ["http://192.168.1.121:8086"]
- username = ""
- password = ""
- ssl-ca = ""
- ssl-cert = ""
- ssl-key = ""
- insecure-skip-verify = false
- timeout = "0s"
- disable-subscriptions = false
- subscription-protocol = "http"
- subscription-mode = "cluster"
- kapacitor-hostname = ""
- http-port = 0
- udp-bind = ""
- udp-buffer = 1000
- udp-read-buffer = 0
- startup-timeout = "5m0s"
- subscriptions-sync-interval = "1m0s"
- [influxdb.excluded-subscriptions]
- _kapacitor = ["autogen"]
这只是解决了一部分的问题。而我们现在需要真正采样数据,并进行发送。在上文中我使用了Chronograf v1.3.10,它有一个内置的TICKscript编辑器,因此我在Chronograf中点击“警报(Alerting)”选项卡,并创建一个新的TICK脚本,然后选择telegraf.autoget数据库作为我的数据源:
由于我实际上并没有从该设备上收集到传感器的数据,所以我在此使用CPU的使用率作为数据,并利用自己的TICKScript来降低采样率。下面我编写了一个非常基础的TICKScript来降低CPU数据的采样率,并且予以向上转发:
- stream
- |from()
- .database('telegraf')
- .measurement('cpu')
- .groupBy(*)
- |where(lambda: isPresent("usage_system"))
- |window()
- .period(1m)
- .every(1m)
- .align()
- |mean('usage_system')
- .as('mean_usage_system')
- |influxDBOut()
- .cluster('mycluster')
- .create()
- .database('downsample')
- .retentionPolicy('autogen')
- .measurement('mean_cpu_idle')
- .precision('s')
该脚本简单地采集了来自“usage_system”字段的CPU每分钟的测量值,在计算出平均值之后,将该值向上写入我的上游InfluxDB实例之中。在这个网关设备上,CPU的数据如下所示:
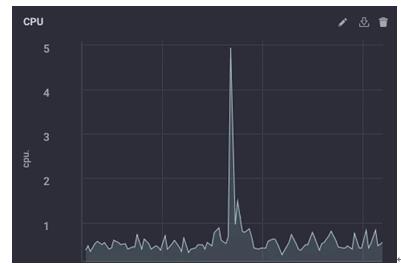
而在上游实例中,其降低采样率后的数据如下所示:
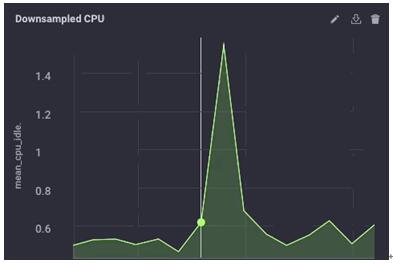
可见数据大体相同,只是粒度略低一些而已。***,我在网关设备上将数据的保留策略设为1天。这样我在不“填满”该设备的情况下,仍然在本地保留着一些历史数据:
现在我的这台IoT网关设备既可以收集本地传感器的数据,又能向本地用户呈现各种分析,还能发出本地报警(只要我开启Kapacitor的警报功能),另外它还降低了本地数据的采样率,并能向上发送到我的企业级InfluxDB实例之中,以用于进一步的分析和处理。在这台网关设备上,我拥有细粒度的毫秒级数据。与此同时,我的上游设备所收到的略低粒度的分钟级数据,足以让我洞悉到各台本地传感器的情况,而不必支付那些花费在各种数据上传中的带宽成本。
利用这个方法,我还可以与一个区域性InfluxDB实例里的分钟级数据进行连接和存储。而且我能够转发更多降低采样率后的数据,到这个用于聚合全企业传感器数据的InfluxDB实例之上。
虽然我完全可以将所有的数据沿着整条“链路”向上发送到最终的企业数据聚合处,但是如果我真的这样聚集来自成千上万台传感器里的数据,其对应的存储和带宽成本势必会被大量无用的细粒度数据所消耗殆尽。
结论
在此,我想再次强调:唯有及时、准确、可操作的物联网数据才能真正有用。所以您的数据越陈旧,就越不具有可操作性;而越不具有可操作性,您就越不需要精细。通过降低数据采样率,以及设置随着时间推移逐步延长的数据保留策略,您可以确保即时数据具有高度的可操作的和高精确度的特性,同时也能保障长期的数据趋势与分析。
原文标题:Architecting IoT Gateway Devices for Data Downsampling,作者: David G. Simmons
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】






















