就是这么简单!
文章目录
- 前言
- 设计一个函数
- 构造要爬取的网址
- 确定要爬取的内容的位置
- 构建输入和调用部分
- 程序完整代码
0 前言
有时候,总有一些重复又琐碎的工作,却不得不做……
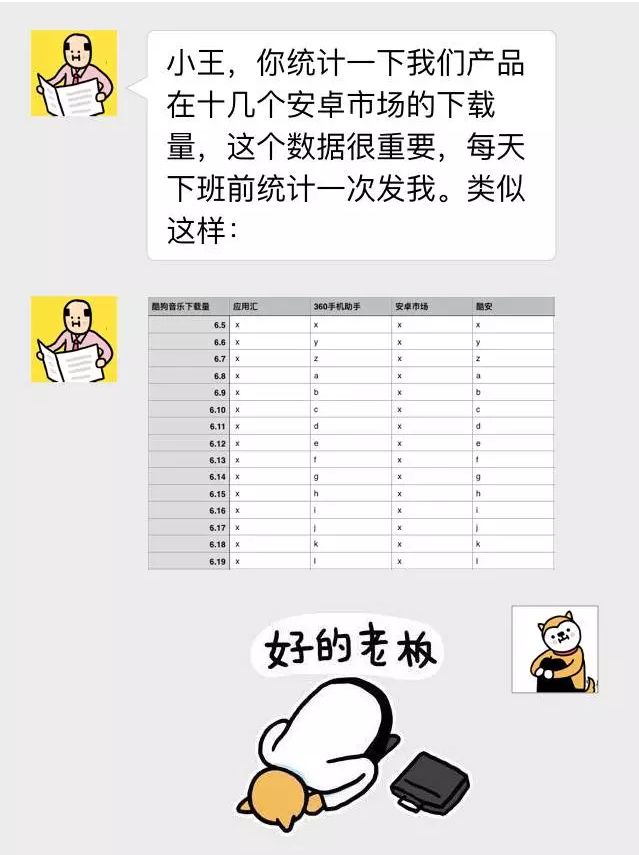
一个个统计,也不是不行,但实在太累……
有没有一个方法,5秒内自动统计整理好呢?
今天教你一招,用 Python 爬取各个页面的下载量,三分钟学会,节省两小时。
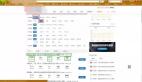
成果是这样的:只需要输入应用名字,然后,就可以获得各市场的下载量了。

想做出来的话,只需要这样几步:
1 设计一个函数
首先,我们需要定义一个爬虫的函数:

如果你是零基础小白,还不明白什么是函数的话,下面是一些讲解:
Python的函数主要有两大部分:内建函数和自定义函数。内建函数就是Python本身固有的函数,如print(),input(),而自定义函数是我们自己设计的,方便重复调用的代码块。
函数是这样的结构:
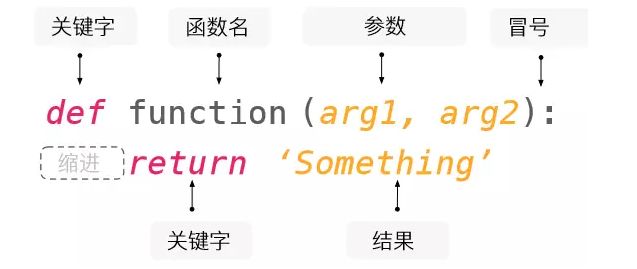
需要注意的是,
- def和return是关键字,Python就是靠识别这些关键字来明白用户的意图。
- 在闭合括号后的冒号必不可少。
- 如果在IDE中冒号后回车,你会得到一个缩进,缩进后面的语句被称作语句块,缩进是为了表明语句和逻辑的从属关系
2 构造要爬取的网址
这个爬虫需要爬取什么样的网址呢?需要程序告诉它:
我们要爬的应用下载量,在详情页上。而这个详情页是有规律可循的。
以应用汇这个安卓市场为例,可以看到我们在搜索“网易云课堂”时,网址是:
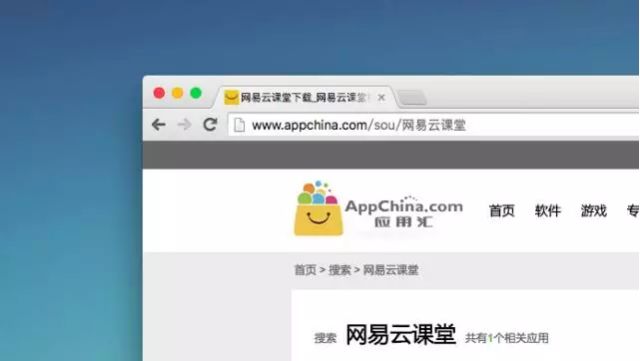
所以我们可以用 url+搜索内容的方式来构造供我们爬取的网址。
3 确定要爬取的内容的位置
我们要爬取的是下载量,要把这个元素的位置在哪里告诉程序。
在Chrome浏览器中,在想爬取的内容上点右键,选“检查”。
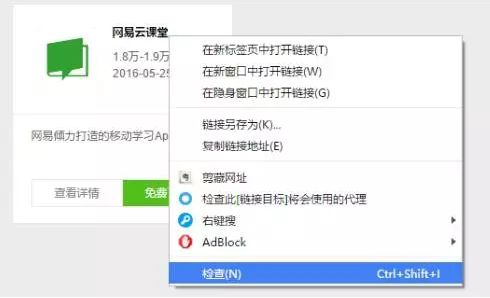
接着在出现的检查框中邮件选择加深的部分,选择copy中的copy selecter。
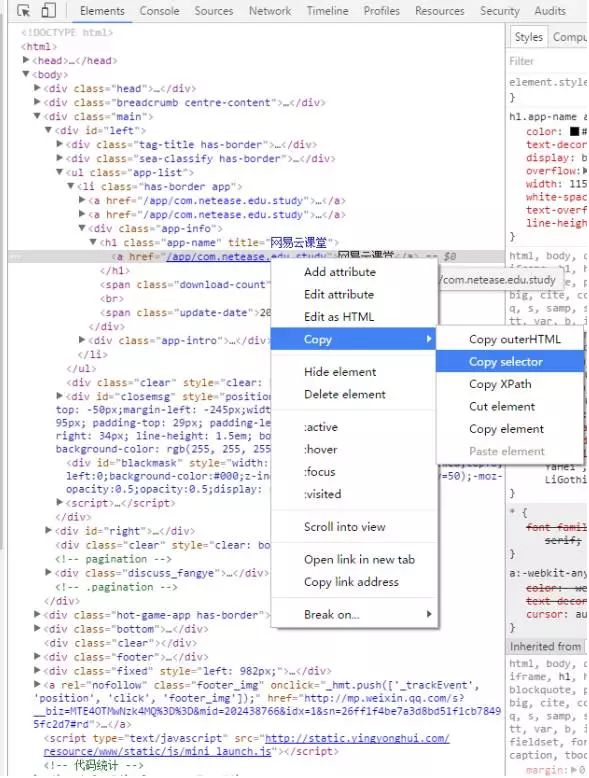
粘贴出来我们复制的部分:

我们称之为CSS元素选择器,通过它可以准确定位到我们想要爬取的部分。
以上三步,我们已经构造出了一个函数的整体结构:

4 构建输入和调用部分
在这里我们使用input函数,格式如下:

调用函数直接输入函数名并且输入参数就好,所以我们需要的是:

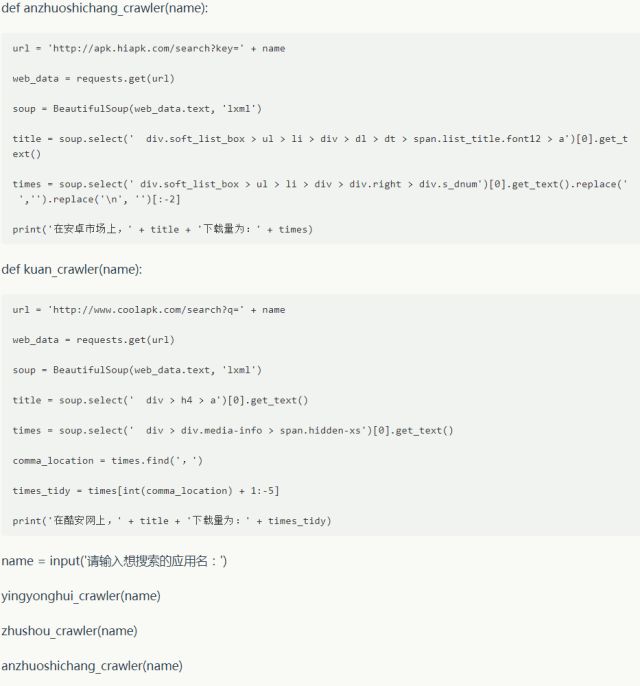
5 程序完整代码
因为我们要同时抓取多个网站的结果,所以我们根据上文的例子自定义多个函数并统一调用。

现在,把你用30秒完成的数据日报发出去吧!