不是有词典匹配的方法了吗?怎么还搞多个机器学习方法。
因为词典方法和机器学习方法各有千秋。
机器学习的方法精确度更高,因为词典匹配会由于语义表达的丰富性而出现很大误差,而机器学习方法不会。而且它可使用的场景更多样。无论是主客观分类还是正负面情感分类,机器学习都可以完成任务。而无需像词典匹配那样要深入到词语、句子、语法这些层面。
而词典方法适用的语料范围更广,无论是手机、电脑这些商品,还是书评、影评这些语料,都可以适用。但机器学习则极度依赖语料,把手机语料训练出来的的分类器拿去给书评分类,那是注定要失败的。
使用机器学习进行情感分析,可以换一个相同意思的说法,就是用有监督的(需要人工标注类别)机器学习方法来对文本进行分类。
这点与词典匹配有着本质的区别。词典匹配是直接计算文本中的情感词,得出它们的情感倾向分值。而机器学习方法的思路是先选出一部分表达积极情感的文本和一部分表达消极情感的文本,用机器学习方法进行训练,获得一个情感分类器。再通过这个情感分类器对所有文本进行积极和消极的二分分类。最终的分类可以为文本给出0或1这样的类别,也可以给出一个概率值,比如”这个文本的积极概率是90%,消极概率是10%“。
Python 有良好的程序包可以进行情感分类,那就是Python 自然语言处理包,Natural Language Toolkit ,简称NLTK 。
NLTK 当然不只是处理情感分析,NLTK 有着整套自然语言处理的工具,从分词到实体识别,从情感分类到句法分析,完整而丰富,功能强大。实乃居家旅行,越货杀人之必备良药。
两本NLTK 的参考书,非常好用。一本是《Python 自然语言处理》,这是《Natural Language Processing with Python》的中文翻译版,是志愿者翻译没有出版社出版的,开源精神万岁!另一本是《Python Text Processing with NLTK 2.0 Cookbook》,这本书写得清晰明了,虽然是英文版的,看起来也很舒服。特别值得一提的是,该书作者Jacob 就是NLTK 包的主要贡献者之一。而且他的博客中有一系列的文章是关于使用机器学习进行情感分类的,我的代码可以说是完全基于他的,在此表示我的感谢。
其实还有国外作者也被他启发,用Python 来处理情感分类。比如这篇文章,写得特别详细认真,也是我重点参考的文章,他的代码我也有所借用。
Jacob 在文章中也有提到,近段时间NLTK 新增的scikit-learn 的接口,使得它的分类功能更为强大好用了,可以用很多高端冷艳的分类算法了。于是我又滚过去看scikit-learn 。简直是天赐我好工具,妈妈再也不用担心我用不了机器学习啦!
有了scikit-learn 的接口,NLTK 做分类变得比之前更简单快捷,但是相关的结合NLTK 和 sciki-learn 的文章实在少,这篇文章是仅有的讲得比较详细的把两者结合的,在此也表示感谢。
但对于我而言还是有点不够的,因为中文和英文有一定的差别,而且上面提到的一些博客里面的代码也是需要改动的。终于把一份代码啃完之后,能写出一个跑得通的中文情感分类代码了。接下来会介绍它的实现思路和具体代码。
在这个系列的文章里面,机器学习都可以认为是有监督的分类方法。
总体流程如图:
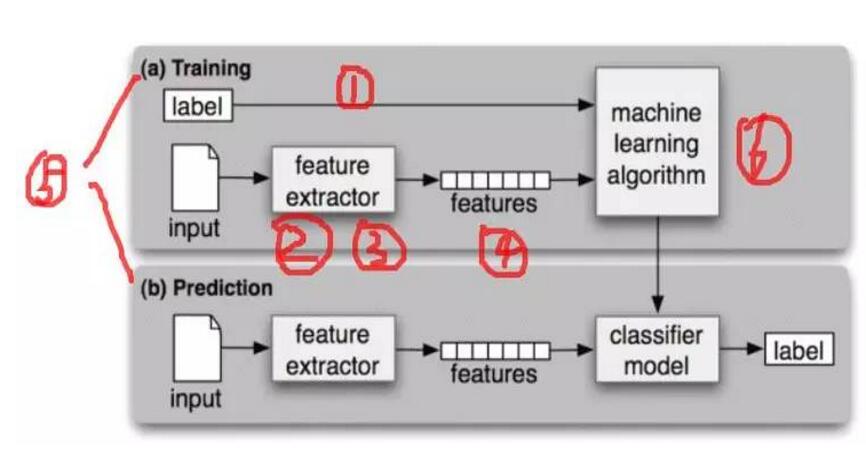
图1:机器学习的流程和结构(摘自《Natural Language Processing with Python》)
一、有监督意味着需要人工标注,需要人为的给文本一个类标签。
比如我有5000条商品评论,如果我要把这些评论分成积极和消极两类。那我就可以先从里面选2000条评论,然后对这2000条数据进行人工标注,把这2000条评论标为“积极”或“消极”。这“积极”和“消极”就是类标签。
假设有1000条评论被标为“积极”,有1000条评论被标为“消极”。(两者数量相同对训练分类器是有用的,如果实际中数量不相同,应该减少和增加数据以使得它们数量相同)
二、之后就要选择特征。
特征就是分类对象所展现的部分特点,是实现分类的依据。我们经常会做出分类的行为,那我们依据些什么进行分类呢?
举个例子,如果我看到一个年轻人,穿着新的正装,提着崭新的公文包,快步行走,那我就会觉得他是一个刚入职的职场新人。在这里面,“崭新”,“正装”,“公文包”,“快步行走”都是这个人所展现出的特点,也是我用来判断这个人属于哪一类的依据。这些特点和依据就是特征。可能有些特征对我判断更有用,有些对我判断没什么用,有些可能会让我判断错误,但这些都是我分类的依据。
我们没办法发现一个人的所有特点,所以我们没办法客观的选择所有特点,我们只能主观的选择一部分特点来作为我分类的依据。这也是特征选择的特点,需要人为的进行一定选择。
而在情感分类中,一般从“词”这个层次来选择特征。
比如这句话“手机非常好用!”,我给了它一个类标签“Positive”。里面有四个词(把感叹号也算上),“手机”,“非常”,“好用”,“!”。我可以认为这4个词都对分类产生了影响,都是分类的依据。也就是无论什么地方出现了这四个词的其中之一,文本都可以被分类为“积极”。这个是把所有词都作为分类特征。
同样的,对这句话,我也可以选择它的双词搭配(Bigrams)作为特征。比如“手机 非常”,“非常 好用”,“好用 !”这三个搭配作为分类的特征。以此类推,三词搭配(Trigrams),四词搭配都是可以被作为特征的。
三、再之后特征要降维。
特征降维说白了就是减少特征的数量。这有两个意义,一个是特征数量减少了之后可以加快算法计算的速度(数量少了当然计算就快了),另一个是如果用一定的方法选择信息量丰富的特征,可以减少噪音,有效提高分类的准确率。
所谓信息量丰富,可以看回上面这个例子“手机非常好用!”,很明显,其实不需要把“手机”,“非常”,“好用”,“!”这4个都当做特征,因为“好用”这么一个词,或者“非常 好用”这么一个双词搭配就已经决定了这个句子是“积极”的。这就是说,“好用”这个词的信息量非常丰富。
那要用什么方法来减少特征数量呢?答案是通过一定的统计方法找到信息量丰富的特征。
统计方法包括:词频(Term Frequency)、文档频率(Document Frequency)、互信息(Pointwise Mutual Information)、信息熵(Information Entropy)、卡方统计(Chi-Square)等等。
在情感分类中,用词频选择特征,也就是选在语料库中出现频率高的词。比如我可以选择语料库中词频最高的2000个词作为特征。用文档频率选特征,是选在语料库的不同文档中出现频率最高的词。而其它三个,太高端冷艳,表示理解得还不清楚,暂且不表。。。
不过意思都是一样的,都是要通过某个统计方法选择信息量丰富的特征。特征可以是词,可以是词组合。
四、把语料文本变成使用特征表示。
在使用分类算法进行分类之前,***步是要把所有原始的语料文本转化为特征表示的形式。
还是以上面那句话做例子,“手机非常好用!”
- 如果在NLTK 中,如果选择所有词作为特征,其形式是这样的:[ {“手机”: True, “非常”: True, “好用”: True, “!”: True} , positive]
- 如果选择双词作为特征,其形式是这样的:[ {“手机 非常”: True, “非常 好用”: True, “好用 !”: True} , positive ]
- 如果选择信息量丰富的词作为特征,其形式是这样的:[ {“好用”: True} , positive ]
(NLTK需要使用字典和数组两个数据类型,True 表示对应的元素是特征。至于为什么要用True 这样的方式,我也不知道。。。反正见到的例子都是这样的。。。有空再研究看是不是可以不这样的吧)
无论使用什么特征选择方法,其形式都是一样的。都是[ {“特征1”: True, “特征2”: True, “特征N”: True, }, 类标签 ]
五、把用特征表示之后的文本分成开发集和测试集,把开发集分成训练集和开发测试集。
机器学习分类必须有数据给分类算法训练,这样才能得到一个(基于训练数据的)分类器。
有了分类器之后,就需要检测这个分类器的准确度。
根据《Python 自然语言处理》的方法,数据可以分为开发集合测试集。开发集专门用于不断调整和发现***的分类算法和特征维度(数量),测试集应该一直保持“不被污染”。在开发集开发完毕之后,再使用测试集检验由开发集确定的***算法和特征维度的效果。具体如图:
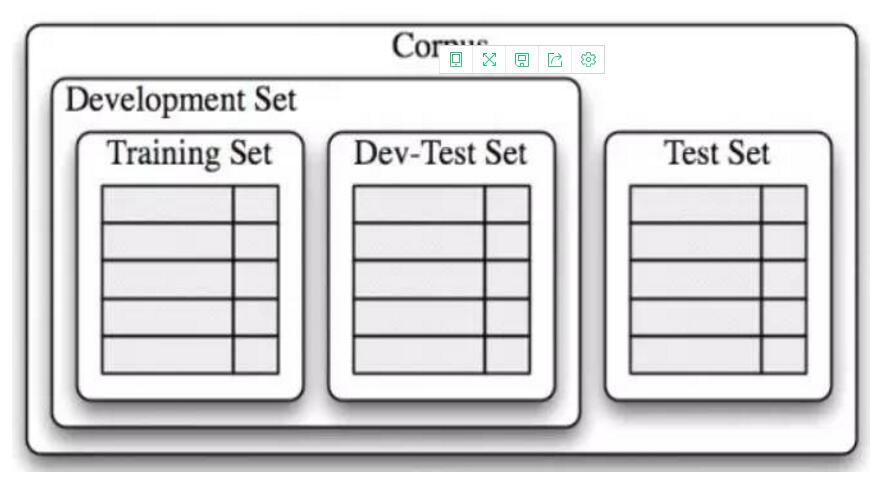
图2:开发集和测试集(摘自《Natural Language Processing with Python》)
一般来说,训练集的数量应该远大于测试集,这样分类算法才能找出里面的规律,构建出高效的分类器。
用回前面的例子。假设2000条已经标注了积极和消极的评论数据,开发集可以是随机的1600条,测试集是剩余的随机400条。然后开发集中,训练集可以是随机的1400条,开发测试集是200条。
六、用不同的分类算法给训练集构建分类器,用开发测试集检验分类器的准确度(选出***算法后可以调整特征的数量来测试准确度)。
这个时候终于可以使用各种高端冷艳的机器学习算法啦!
我们的目标是:找到***的机器学习算法。
可以使用朴素贝叶斯(NaiveBayes),决策树(Decision Tree)等NLTK 自带的机器学习方法。也可以更进一步,使用NLTK 的scikit-learn 接口,这样就可以调用scikit-learn 里面的所有,对,是所有机器学习算法了。我已经忍不住的泪流满面。
其实方法很容易。只要以下五步。
- 仅仅使用开发集(Development Set)。
- 用分类算法训练里面的训练集(Training Set),得出分类器。
- 用分类器给开发测试集分类(Dev-Test Set),得出分类结果。
- 对比分类器给出的分类结果和人工标注的正确结果,给出分类器的准确度。
- 使用另一个分类算法,重复以上三步。
在检验完所有算法的分类准确度之后,就可以选出***的一个分类算法了。
在选出***的分类算法之后,就可以测试不同的特征维度对分类准确度的影响了。一般来说,特征太少则不足以反映分类的所有特点,使得分类准确率低;特征太多则会引入噪音,干扰分类,也会降低分类准确度。所以,需要不断的测试特征的数量,这样才可以得到***的分类效果。
七、选择出开发集中***的分类算法和特征维度,使用测试集检验得出情感分类的准确度。
在终于得到***分类算法和特征维度(数量)之后,就可以动用测试集。
直接用***的分类算法对测试集进行分类,得出分类结果。对比分类器的分类结果和人工标注的正确结果,给出分类器的最终准确度。
用Python 进行机器学习及情感分析,需要用到两个主要的程序包:nltk 和 scikit-learn
nltk 主要负责处理特征提取(双词或多词搭配需要使用nltk 来做)和特征选择(需要nltk 提供的统计方法)。
scikit-learn 主要负责分类算法,评价分类效果,进行分类等任务。
接下来会有四篇文章按照以下步骤来实现机器学习的情感分析。
- 特征提取和特征选择(选择***特征)
- 赋予类标签,分割开发集和测试集
- 构建分类器,检验分类准确度,选择***分类算法
- 存储和使用***分类器进行分类,分类结果为概率值
首先是特征提取和选择
一、特征提取方法
1. 把所有词作为特征
- def bag_of_words(words):
- return dict([(word, True) for word in words])
返回的是字典类型,这是nltk 处理情感分类的一个标准形式。
2. 把双词搭配(bigrams)作为特征
- mport nltk
- from nltk.collocations import BigramCollocationFinder
- from nltk.metrics import BigramAssocMeasures
- def bigram(words, score_fn=BigramAssocMeasures.chi_sq, n=1000):
- bigram_finder = BigramCollocationFinder.from_words(words) #把文本变成双词搭配的形式
- bigrams = bigram_finder.nbest(score_fn, n) #使用了卡方统计的方法,选择排名前1000的双词
- return bag_of_words(bigrams)
除了可以使用卡方统计来选择信息量丰富的双词搭配,还可以使用其它的方法,比如互信息(PMI)。而排名前1000也只是人工选择的阈值,可以随意选择其它值,可经过测试一步步找到***值。
3. 把所有词和双词搭配一起作为特征
- def bigram_words(words, score_fn=BigramAssocMeasures.chi_sq, n=1000):
- bigram_finder = BigramCollocationFinder.from_words(words)
- bigrams = bigram_finder.nbest(score_fn, n)
- return bag_of_words(words + bigrams) #所有词和(信息量大的)双词搭配一起作为特征
二、特征选择方法
有了提取特征的方法后,我们就可以提取特征来进行分类学习了。但一般来说,太多的特征会降低分类的准确度,所以需要使用一定的方法,来“选择”出信息量最丰富的特征,再使用这些特征来分类。
特征选择遵循如下步骤:
- 计算出整个语料里面每个词的信息量
- 根据信息量进行倒序排序,选择排名靠前的信息量的词
- 把这些词作为特征
1. 计算出整个语料里面每个词的信息量
1.1 计算整个语料里面每个词的信息量
- from nltk.probability import FreqDist, ConditionalFreqDist
- def create_word_scores(): posWords = pickle.load(open('D:/code/sentiment_test/pos_review.pkl','r')) ..... return word_scores #包括了每个词和这个词的信息量
1.2 计算整个语料里面每个词和双词搭配的信息量
- def create_word_bigram_scores():
- posdata = pickle.load(open('D:/code/sentiment_test/pos_review.pkl','r')) negdata = pickle.load(open('D:/code/sentiment_test/neg_review.pkl','r')) ..... return word_scores
2. 根据信息量进行倒序排序,选择排名靠前的信息量的词
- def find_best_words(word_scores, number):
- best_vals = sorted(word_scores.iteritems(), key=lambda (w, s): s, reverse=True)[:number] #把词按信息量倒序排序。number是特征的维度,是可以不断调整直至***的
- best_words = set([w for w, s in best_vals])
- return best_words
然后需要对find_best_words 赋值,如下:
- word_scores_1 = create_word_scores()
- word_scores_2 = create_word_bigram_scores()
3. 把选出的这些词作为特征(这就是选择了信息量丰富的特征)
- def best_word_features(words): return dict([(word, True) for word in words if word in best_words])
三、检测哪中特征选择方法更优
见构建分类器,检验分类准确度,选择***分类算法
***步,载入数据。
要做情感分析,首要的是要有数据。
数据是人工已经标注好的文本,有一部分积极的文本,一部分是消极的文本。
文本是已经分词去停用词的商品评论,形式大致如下:[[word11, word12, ... word1n], [word21, word22, ... , word2n], ... , [wordn1, wordn2, ... , wordnn]]
这是一个多维数组,每一维是一条评论,每条评论是已经又该评论的分词组成。
- #! /usr/bin/env python2.7
- #coding=utf-8
- pos_review = pickle.load(open('D:/code/sentiment_test/pos_review.pkl','r'))
- neg_review = pickle.load(open('D:/code/sentiment_test/neg_review.pkl','r'))
我用pickle 存储了相应的数据,这里直接载入即可。
第二步,使积极文本的数量和消极文本的数量一样。
- from random import shuffle
- shuffle(pos_review) #把积极文本的排列随机化
- size = int(len(pos_review)/2 - 18)
- pos = pos_review[:size]
- neg = neg_review
我这里积极文本的数据恰好是消极文本的2倍还多18个,所以为了平衡两者数量才这样做。
第三步,赋予类标签。
- def pos_features(feature_extraction_method):
- posFeatures = []
- ....
- negFeatures.append(negWords)
- return negFeatures
这个需要用特征选择方法把文本特征化之后再赋予类标签。
第四步、把特征化之后的数据数据分割为开发集和测试集
- train = posFeatures[174:]+negFeatures[174:]
- devtest = posFeatures[124:174]+negFeatures[124:174]
- test = posFeatures[:124]+negFeatures[:124]
这里把前124个数据作为测试集,中间50个数据作为开发测试集,***剩下的大部分数据作为训练集。
在把文本转化为特征表示,并且分割为开发集和测试集之后,我们就需要针对开发集进行情感分类器的开发。测试集就放在一边暂时不管。
开发集分为训练集(Training Set)和开发测试集(Dev-Test Set)。训练集用于训练分类器,而开发测试集用于检验分类器的准确度。
为了检验分类器准确度,必须对比“分类器的分类结果”和“人工标注的正确结果”之间的差异。
所以:
- ***步,是要把开发测试集中,人工标注的标签和数据分割开来。
- 第二步是使用训练集训练分类器;
- 第三步是用分类器对开发测试集里面的数据进行分类,给出分类预测的标签;第四步是对比分类标签和人工标注的差异,计算出准确度。
一、分割人工标注的标签和数据
dev, tag_dev = zip(*devtest) #把开发测试集(已经经过特征化和赋予标签了)分为数据和标签
二到四、可以用一个函数来做
- def score(classifier):
- classifier = SklearnClassifier(classifier) #在nltk 中使用scikit-learn 的接口
- classifier.train(train) #训练分类器
- pred = classifier.batch_classify(testSet) #对开发测试集的数据进行分类,给出预测的标签
- return accuracy_score(tag_test, pred) #对比分类预测结果和人工标注的正确结果,给出分类器准确度
之后我们就可以简单的检验不同分类器和不同的特征选择的结果。
- import sklearn
- .....
- print 'NuSVC`s accuracy is %f' %score(NuSVC())
1. 我选择了六个分类算法,可以先看到它们在使用所有词作特征时的效果:
- BernoulliNB`s accuracy is 0.790000
- MultinomiaNB`s accuracy is 0.810000
- LogisticRegression`s accuracy is 0.710000
- SVC`s accuracy is 0.650000
- LinearSVC`s accuracy is 0.680000
- NuSVC`s accuracy is 0.740000
2. 再看使用双词搭配作特征时的效果(代码改动如下地方即可)
- posFeatures = pos_features(bigrams)
- negFeatures = neg_features(bigrams)
结果如下:
- BernoulliNB`s accuracy is 0.710000 MultinomiaNB`s accuracy is 0.750000 LogisticRegression`s accuracy is 0.790000 SVC`s accuracy is 0.750000 LinearSVC`s accuracy is 0.770000 NuSVC`s accuracy is 0.780000
3. 再看使用所有词加上双词搭配作特征的效果
posFeatures = pos_features(bigram_words) negFeatures = neg_features(bigram_words)
结果如下:
- BernoulliNB`s accuracy is 0.710000
- MultinomiaNB`s accuracy is 0.750000
- LogisticRegression`s accuracy is 0.790000
- SVC`s accuracy is 0.750000
- LinearSVC`s accuracy is 0.770000
- NuSVC`s accuracy is 0.780000
可以看到在不选择信息量丰富的特征时,仅仅使用全部的词或双词搭配作为特征,分类器的效果并不理想。
接下来将使用卡方统计量(Chi-square)来选择信息量丰富的特征,再用这些特征来训练分类器。
4. 计算信息量丰富的词,并以此作为分类特征
- word_scores = create_word_scores()
- best_words = find_best_words(word_scores, 1500) #选择信息量最丰富的1500个的特征
- posFeatures = pos_features(best_word_features)
- negFeatures = neg_features(best_word_features)
结果如下:
- BernoulliNB`s accuracy is 0.870000
- MultinomiaNB`s accuracy is 0.860000
- LogisticRegression`s accuracy is 0.730000
- SVC`s accuracy is 0.770000
- LinearSVC`s accuracy is 0.720000
- NuSVC`s accuracy is 0.780000
可见贝叶斯分类器的分类效果有了很大提升。
5. 计算信息量丰富的词和双词搭配,并以此作为特征
- word_scores = create_word_bigram_scores()
- best_words = find_best_words(word_scores, 1500) #选择信息量最丰富的1500个的特征
- posFeatures = pos_features(best_word_features)
- negFeatures = neg_features(best_word_features)
结果如下:
- BernoulliNB`s accuracy is 0.910000
- MultinomiaNB`s accuracy is 0.860000
- LogisticRegression`s accuracy is 0.800000
- SVC`s accuracy is 0.800000
- LinearSVC`s accuracy is 0.750000
- NuSVC`s accuracy is 0.860000
可以发现贝努利的贝叶斯分类器效果继续提升,同时NuSVC 也有很大的提升。
此时,我们选用BernoulliNB、MultinomiaNB、NuSVC 作为候选分类器,使用词和双词搭配作为特征提取方式,测试不同的特征维度的效果。
- dimension = ['500','1000','1500','2000','2500','3000']
- for d in dimension:
- word_scores = create_word_scores_bigram()
- best_words = find_best_words(word_scores, int(d))
- posFeatures = pos_features(best_word_features)
- negFeatures = neg_features(best_word_features)
- train = posFeatures[174:]+negFeatures[174:]
- devtest = posFeatures[124:174]+negFeatures[124:174]
- test = posFeatures[:124]+negFeatures[:124]
- dev, tag_dev = zip(*devtest)
- print 'Feature number %f' %d
- print 'BernoulliNB`s accuracy is %f' %score(BernoulliNB())
- print 'MultinomiaNB`s accuracy is %f' %score(MultinomialNB())
- print 'LogisticRegression`s accuracy is %f' %score(LogisticRegression())
- print 'SVC`s accuracy is %f' %score(SVC())
- print 'LinearSVC`s accuracy is %f' %score(LinearSVC())
- print 'NuSVC`s accuracy is %f' %score(NuSVC())
结果如下(很长。。):
- Feature number 500
- BernoulliNB`s accuracy is 0.880000
- MultinomiaNB`s accuracy is 0.850000
- LogisticRegression`s accuracy is 0.740000
- SVC`s accuracy is 0.840000
- LinearSVC`s accuracy is 0.700000
- NuSVC`s accuracy is 0.810000
- Feature number 1000
- BernoulliNB`s accuracy is 0.860000
- MultinomiaNB`s accuracy is 0.850000
- LogisticRegression`s accuracy is 0.750000
- SVC`s accuracy is 0.800000
- LinearSVC`s accuracy is 0.720000
- NuSVC`s accuracy is 0.760000
- Feature number 1500
- BernoulliNB`s accuracy is 0.870000
- MultinomiaNB`s accuracy is 0.860000
- LogisticRegression`s accuracy is 0.770000
- SVC`s accuracy is 0.770000
- LinearSVC`s accuracy is 0.750000
- NuSVC`s accuracy is 0.790000
- Feature number 2000
- BernoulliNB`s accuracy is 0.870000
- MultinomiaNB`s accuracy is 0.850000
- LogisticRegression`s accuracy is 0.770000
- SVC`s accuracy is 0.690000
- LinearSVC`s accuracy is 0.700000
- NuSVC`s accuracy is 0.800000
- Feature number 2500
- BernoulliNB`s accuracy is 0.850000
- MultinomiaNB`s accuracy is 0.830000
- LogisticRegression`s accuracy is 0.780000
- SVC`s accuracy is 0.700000
- LinearSVC`s accuracy is 0.730000
- NuSVC`s accuracy is 0.800000
- Feature number 3000
- BernoulliNB`s accuracy is 0.850000
- MultinomiaNB`s accuracy is 0.830000
- LogisticRegression`s accuracy is 0.780000
- SVC`s accuracy is 0.690000
- LinearSVC`s accuracy is 0.710000
- NuSVC`s accuracy is 0.800000
把上面的所有测试结果进行综合可汇总如下:
不同分类器的不同特征选择方法效果
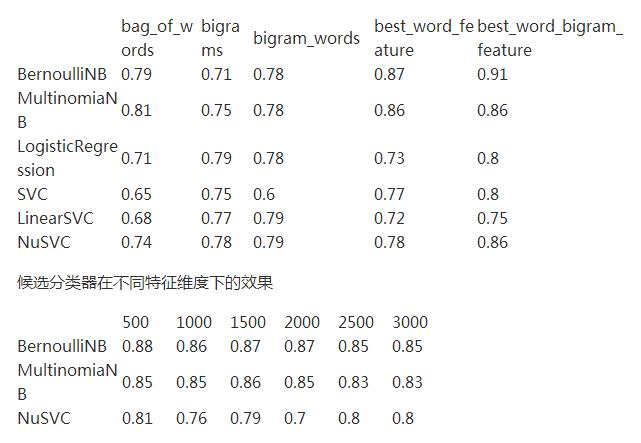
综合来看,可以看出特征维数在500 或 1500的时候,分类器的效果是***的。
所以在经过上面一系列的分析之后,可以得出如下的结论:
- Bernoulli 朴素贝叶斯分类器效果***
- 词和双词搭配作为特征时效果***
- 当特征维数为1500时效果***
为了不用每次分类之前都要训练一次数据,所以可以在用开发集找出***分类器后,把***分类器存储下来以便以后使用。然后再使用这个分类器对文本进行分类。
一、使用测试集测试分类器的最终效果
- word_scores = create_word_bigram_scores() #使用词和双词搭配作为特征
- best_words = find_best_words(word_scores, 1500) #特征维度1500
- posFeatures = pos_features(best_word_features)
- negFeatures = neg_features(best_word_features)
- trainSet = posFeatures[:500] + negFeatures[:500] #使用了更多数据
- testSet = posFeatures[500:] + negFeatures[500:]
- test, tag_test = zip(*testSet)
- def final_score(classifier):
- classifier = SklearnClassifier(classifier)
- classifier.train(trainSet)
- pred = classifier.batch_classify(test)
- return accuracy_score(tag_test, pred)
- print final_score(BernoulliNB()) #使用开发集中得出的***分类器
其结果是很给力的:
- 0.979166666667
二、把分类器存储下来
(存储分类器和前面没有区别,只是使用了更多的训练数据以便分类器更为准确)
- word_scores = create_word_bigram_scores()
- best_words = find_best_words(word_scores, 1500)
- posFeatures = pos_features(best_word_features)
- negFeatures = neg_features(best_word_features)
- trainSet = posFeatures + negFeatures
- BernoulliNB_classifier = SklearnClassifier(BernoulliNB())
- BernoulliNB_classifier.train(trainSet)
- pickle.dump(BernoulliNB_classifier, open('D:/code/sentiment_test/classifier.pkl','w'))
在存储了分类器之后,就可以使用该分类器来进行分类了。
三、使用分类器进行分类,并给出概率值
给出概率值的意思是用分类器判断一条评论文本的积极概率和消极概率。给出类别也是可以的,也就是可以直接用分类器判断一条评论文本是积极的还是消极的,但概率可以提供更多的参考信息,对以后判断评论的效用也是比单纯给出类别更有帮助。
1. 把文本变为特征表示的形式
要对文本进行分类,首先要把文本变成特征表示的形式。而且要选择和分类器一样的特征提取方法。
- #! /usr/bin/env python2.7
- #coding=utf-8
- moto = pickle.load(open('D:/code/review_set/senti_review_pkl/moto_senti_seg.pkl','r')) #载入文本数据
- def extract_features(data):
- feat = []
- for i in data:
- feat.append(best_word_features(i))
- return feat
- moto_features = extract_features(moto) #把文本转化为特征表示的形式
注:载入的文本数据已经经过分词和去停用词处理。
2. 对文本进行分类,给出概率值
- import pickle
- import sklearn
- clf = pickle.load(open('D:/code/sentiment_test/classifier.pkl')) #载入分类器
- pred = clf.batch_prob_classify(moto_features) #该方法是计算分类概率值的
- p_file = open('D:/code/sentiment_test/score/Motorala/moto_ml_socre.txt','w') #把结果写入文档
- for i in pred:
- p_file.write(str(i.prob('pos')) + ' ' + str(i.prob('neg')) + '\n')
- p_file.close()
***分类结果如下图:
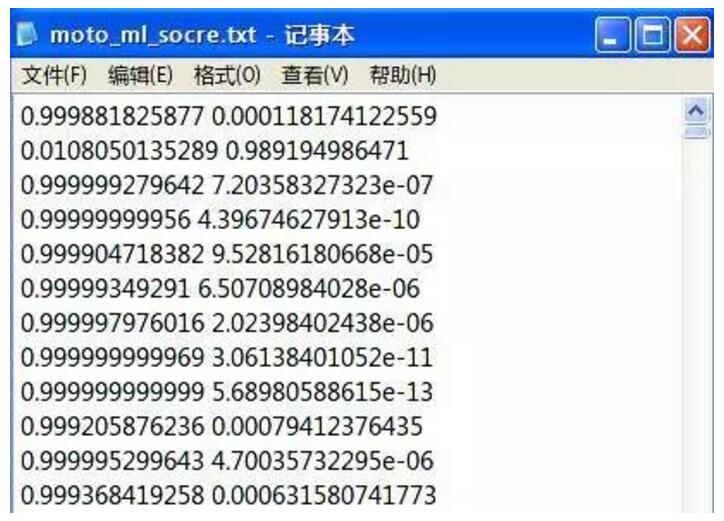
前面是积极概率,后面是消极概率
折腾了这么久就为了搞这么一个文件出来。。。这伤不起的节奏已经无人阻挡了吗。。。
不过这个结果确实比词典匹配准确很多,也算欣慰了。。。