最近线上执行备份的从库时出现复制卡死现象,分析以后发现是两个死锁,show full processlist的状态如图1所示,其中,数据库版本是官方5.7.18版本,我们内部做了些许修改,但与此次死锁无关。
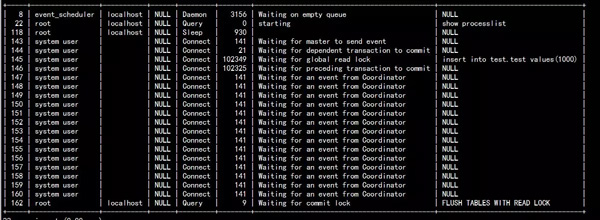
图一
先说一下结论,图一中:
- 162线程是执行innobackup执行的flush tables with read lock;
- 144是SQL线程,并行复制中的Coordinator线程;
- 145/146是并行复制的worker线程,145/146worker线程队列中的事务可以并行执行。
144Coordinator线程分发relaylog中事务时发现这个事务不能执行,要等待前面的事务完成提交,所以处于waiting for dependent transaction to commit的状态。145/146线程和备份线程162形成死锁,145线程等待162线程 global read lock 释放,162线程占有MDL::global read lock 全局读锁,申请全局commit lock的时候阻塞等待146线程,146线程占有MDL:: commit lock,因为从库设置slave_preserve_commit_order=1,保证从库binlog提交顺序,而146线程执行事务对应的binlog靠后面,所以等待145的事务提交。最终形成了145->162->146->145的死循环,形成死锁。
同样的,图二中:
- 183是备份程序执行的flush tables with read lock;
- 165是SQL线程,并行复制的Coordinator线程;
- 166/167是并行复制的worker线程。
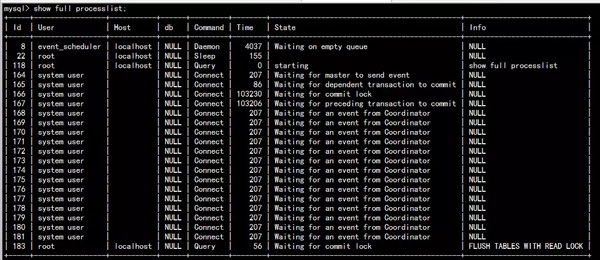
图二
165Coordinator线程分发的事务还不能执行,进入waiting for dependent transaction to commit的状态,183、166、167三个线程形成死锁,183占有全局读锁,获取全局commit锁的时候进入阻塞,等待167释放事务涉及到表的commit锁;166,167的事务可以并行复制,167占有表级commit锁,但是事务对应的binlog在后面,阻塞等待166先提交进入waiting for preceding transaction to commit的状态;166线程事务执行时提交要获得表级commit锁,但已经被183占有,所以阻塞等待。这样形成了183->167->166->183的死锁。
三个线程相互形成死锁,在我的经验中还是很少见的,又因为涉及的MDL锁是服务层的锁,死锁检测也不会起作用。
死锁原因分析
1、MDL锁
参考:http://mysql.taobao.org/monthly/2015/11/04/
2、flush tables with read lock获取两个锁
MDL::global read lock 和MDL::global commit lock,而且是显示的MDL_SHARED锁。
- //Global_read_lock::lock_global_read_lock
- MDL_REQUEST_INIT(&mdl_request,MDL_key::GLOBAL, "", "", MDL_SHARED, MDL_EXPLICIT);
- //Global_read_lock::make_global_read_lock_block_commit
- MDL_REQUEST_INIT(&mdl_request,MDL_key::COMMIT, "", "", MDL_SHARED, MDL_EXPLICIT);
3、事务执行中涉及两个锁
在所有更新数据的代码路径里,除了必须的锁外,还会额外请求MDL_key::GLOBAL锁的MDL_INTENTION_EXCLUSIVE锁;在事务提交前,会先请求MDL_key::COMMIT锁的MDL_INTENTION_EXCLUSIVE锁。对于scope锁来说,IX锁和S锁是不兼容的。
4、--slave_preserve_commit_order
- For multi-threaded slaves, enabling this variable ensures that
- transactions are externalized on theslave in the same order as they appear
- in the slave's relay log.
slave_preserve_commit_order=1时,relay-log中事务的提交顺序会严格按照在relay-log中出现的顺序提交。
所以,事务的执行和flush tables with read lock语句获得两个锁都不是原子的,并行复制时模式下按以下的顺序就会出现死锁。
- 事务A、B可以并行复制,relay-log中A在前,slave_preserve_commit_order=1
- 从库回放时B事务执行较快,先执行到commit,获得commit锁,并进入waiting for preceding transaction to commit的状态
- 执行flush tables with read lock,进入waiting for commit的状态
- 事务A执行。事务A如果在FTWRL语句获得global read lock锁之后执行,那么事务A就进入waiting for global read lock的状态,即第一种死锁;如果事务A在FTWRL获得global read lock之前执行,同时FTWRL获得global commit锁之后应用Xid_event提交事务,则进入 waiting for the commit lock的状态,即第二种死锁。
复现
理解了死锁出现的原因后,重现就简单多了。重现这个死锁步骤主要是2步:
1、在主库构造并行复制的事务,利用debug_sync
- session 1
- SET DEBUG_SYNC='waiting_in_the_middle_of_flush_stage SIGNAL s1 WAIT_FOR f';
- insert into test.test values(13);//事务A
- //session 2
- SET DEBUG_SYNC= 'now WAIT_FOR s1';
- SET DEBUG_SYNC= 'bgc_after_enrolling_for_flush_stage SIGNAL f';
- insert into test.test values(16);//事务B
2、从库执行,修改源代码,在关键地方sleep若干时间,控制并行复制的worker的执行并留出足够时间执行flush tables with read lock
修改点如下:
- //Xid_apply_log_event::do_apply_event_worker
- if(w->id==0)
- {
- std::cout<<"before commit"<<std::endl;
- sleep(20);
- }
- //pop_jobs_item
- if(worker->id==0)
- sleep(20);
开启slave以后,观察show full processlist和输出日志,在其中一个worker出现wait for preceding transaction to commit以后,执行 ftwrl,出现图1的死锁;wait for preceding transaction to commit以后,出现日志before commit之后,执行 ftwrl,出现图2的死锁。
如何解决?
出现死锁以后如果不人工干预,IO线程正常,但是SQL线程一直卡住,一般需要等待lock-wait-timeout时间,这个值我们线上设置1800秒,所以这个死锁会产生很大影响。
那么如何解决呢?kill !kill哪个线程呢?
- 对图1的死锁,146处于wait for preceding transaction状态的worker线程实际处于mysql_cond_wait的状态,kill不起作用,所以只能kill 145线程或者备份线程,如果kill145worker线程,整个并行复制就报错结束,show slave status显示SQL异常退出,之后需要手动重新开启sql线程,所以最好的办法就是kill执行flush tables with read lock的线程,代价最小。
- 至于图2的死锁,则只能kill掉执行flush tables with read lock的线程。所以出现上述死锁时,kill执行flush tables with read lock的备份线程就恢复正常,之后择机重新执行备份即可。
如何避免?
设置xtrabackup的kill-long-queries-timeout参数可以避免第一种死锁的出现,其实不算避免,只是出现以后xtrabackup会杀掉阻塞的执行语句的线程;但是这个参数对第二种死锁状态则无能为力了,因为xtrabackup选择杀掉的线程时,会过滤Info!=NULL。
另外还有个参数safe-slave-backup,执行备份的时候加上这个参数会停掉SQL线程,这样也肯定不会出现这个死锁,只是停掉SQL未免太暴力了,个人不提倡这样做。
可以设置slave_preserve_commit_order=0关闭从库binlog的顺序提交,关闭这个参数只是影响并行复制的事务在从库的提交顺序,对最终的数据一致性并无影响,所以如果无特别要求从库的binlog顺序必须与主库保持一致,可以设置slave_preserve_commit_order=0避免这个死锁的出现。
关于xtrabackup kill-long-query-type参数
首先说下```kill-long-queries-timeout,kill-long-query-type```参数,文档介绍如下
- --KILL-LONG-QUERY-TYPE=ALL|SELECT
- This option specifies which types of queries should be killed to
- unblock the global lock. Default is “all”.
- --KILL-LONG-QUERIES-TIMEOUT=SECONDS**
- This option specifies the number of seconds innobackupex waits
- between starting FLUSH TABLES WITH READ LOCK and killing those queries
- that block it. Default is 0 seconds, which means innobackupex will not
- attempt to kill any queries. In order to use this option xtrabackup
- user should have PROCESS and SUPER privileges.Where supported (Percona
- Server 5.6+) xtrabackup will automatically use Backup Locks as a
- lightweight alternative to FLUSH TABLES WITH READ LOCK to copy non-
- InnoDB data to avoid blocking DML queries that modify InnoDB tables.
参数的作用的就是在Xtrabackup执行FLUSH TABLES WITH READ LOCK以后,获得全局读锁时,如果有正在执行的事务会阻塞等待,kill-long-queries-timeout参数不为0时,xtrabackup内部创建一个线程,连接到数据库执行show full processlist,如果TIME超过kill-long-queries-timeout,会kill掉线程,kill-long-query-type设置可以kill掉的SQL类型。
官方文档介绍kill-long-query-type默认值时all,也就是所有语句都会kill掉。但在使用中发现,只设置kill-long-queries-timeout,未设置kill-long-query-type时,参数没起作用!最后查阅xtrabackup代码,如下:
- {"kill-long-query-type", OPT_KILL_LONG_QUERY_TYPE,
- "This option specifies which types of queries should be killed to "
- "unblock the global lock. Default is \"all\".",
- (uchar*) &opt_ibx_kill_long_query_type,
- (uchar*) &opt_ibx_kill_long_query_type, &query_type_typelib,
- GET_ENUM, REQUIRED_ARG, QUERY_TYPE_SELECT, 0, 0, 0, 0, 0}
心中一万头草泥马,也许只是笔误,但也太坑爹了!所以使用kill-long-query-type时一定要自己指定好类型!
总结
回顾这次执行备份的从库复制卡死故障,根本原因在于flush tables with read lock语句和事务执行的过程都涉及到连个锁,而且不是原子的,再加上并行复制以及设置了从库binlog的顺序提交,最终导致三个线程形成死锁。在寻找问题的解决方案中,意外发现了Xtrabackup kill-long-query-type的“秘密”,告诫我们在使用中尽量显示指定参数,一方面更准确,另一方面也便于查看。
另外,我们知道set global read_only=1语句执行中涉及到的锁和flush tables with read lock涉及的锁时一样的,也是两个MDL锁,所以理论上在并行复制的从库执行set global read_only=1语句也可能会出现上述的两个死锁,有兴趣的可以验证下。