尽管AI、物联网以及GDPR(一般数据保护条例)持续占据头条,但也不要忘记在大数据的实现性应用方面,云迁移与流分析所产生的划时代影响。
诚然,AI所产生的影响已然无法忽视,其影响所覆盖的范围从地缘政治到市井琐事,甚至还参与了一些举世闻名的事件。此外,物联网在当今社会中日益增长的影响也是不容忽视的,具体包括家庭、医院提供医疗服务的方式、自动驾驶汽车的驱动、工厂的运营以及智能化城市管理等方面。尔后,GDPR将在2018年生效,这将迫使各组织着力解决将涉及隐私与国家主权影响的数据从现有数据库转移到数据湖与云存储的过程中所要面临的问题。

透过表面看本质,我们发现构造性转变已经开始,具体包括企业在云领域的管理方式、流数据分析与数据湖战略等。
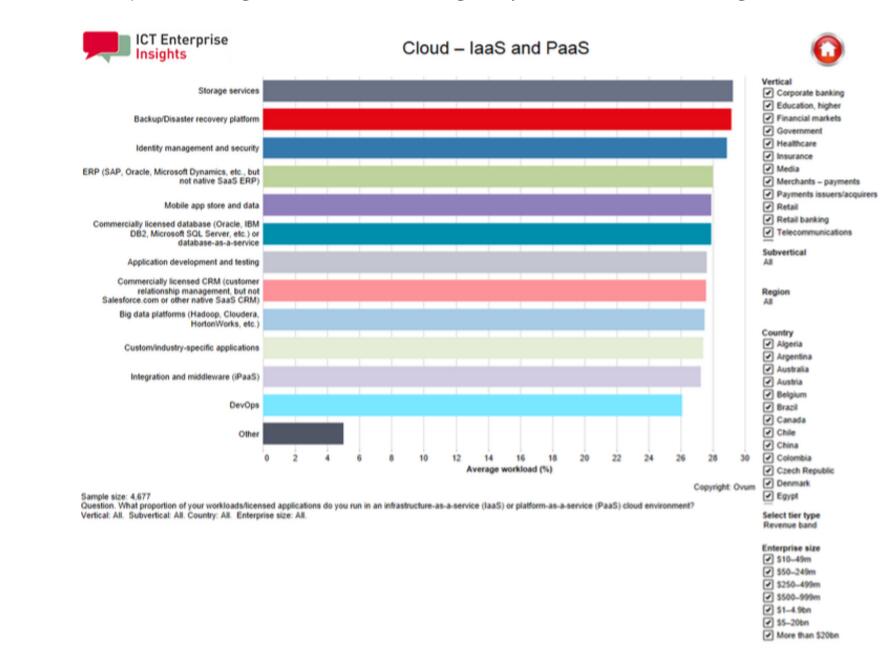
目前,已有27.5%的大数据工作负载运行在云端(来源:Ovum ICT Enterprise Insights)
关于未来展望,我们将着眼于数据的管理方式。回顾过去的一年,我们曾表示“大数据——无论其来自于物联网还是更为传统的资源——将会逐步实现在云中完成存储与处理。”去年,我们预计会有35—40%的新生大数据工作负载将在云端完成部署,而到2018年底,新的部署将超过50%。
我们的预测并非不切实际;Ovum针对所有大数据工作负载的***全球调查研究显示,在此之中的27.5%已经完成了云端部署。另外,根据Ovum的报告,企业云应用很难将大数据拒之门外,而在各式各样的工作负载中,企业云应用所占据的比例在26—30%之间。
由于惯性使然,大多数组织已经不再坚持立足云环境复制与其自有数据中心相关的种种功能特性。此外,大多数组织会选择使用多个家云供应商,这看似是为了取各家之所长。然而,正如以往的类似教训一样,这其实只是自上而下的企业标准政策与部门针对相关政策权衡之后所做出的妥协性决策产物。
因此,如同您所在的组织可能面临SAP的使用成本一样,不同部门可能同样面临着与人力资源相关的日常开销或CRM销售压力,抑或拥有多种尚未与企业遗留方案相融合的ERP系统。在云端,企业电子邮件系统可能通过Office 365实现,而部门IT团队则将使用AWS进行开发与测试; 与此同时,企业营销团队使用的则是Google Analytics。
随着云从运行独立工作负载的目标发展至企业关键型应用,我们预计在2018年初期,大多数公司将开始正式实施多云策略——正如在2017年,我们将云端部署视为大数据的隐患一般——多云也因此将成为2018年亟待解决的问题。也正因为如此,甲骨文方面决定将运行在亚马逊RDS服务上的数据库产品的使用价格进行翻倍; 这也是为何Aurora OLTP数据库目前能够成为亚马逊公司中增长速度最快的服务(在此之前的冠军为Redshift)。
这不仅仅是云供应商对于此类担忧的反应性决策,多云的决策将影响有关平台的选择。当您选择在EC 2上运行一套甲骨文的数据库或Hadoop集群时——若Azure或Google Cloud调整其定价——这同时也成为了一项值得重新审视的抉择。
当您选择在IBM云端运行Aurora、Cosmos DB、谷歌BigQuery、甲骨文Autonomous数据库18c或IBM分析系统时,这不仅意味着需要选择云,还需要选择数据平台。现在,您对于这一选择是否能够让运行一套特定云的数据平台增值的关注度已经远胜于是否选择依赖一家特定的云供应商——这就如同让您再一次面对甲骨文公司或SQL Server平台做出决策。
诚然,这也是亚马逊公司与微软方面正在以几乎免费的方式提供数据库迁移服务的原因——毫无疑问的是这两家公司想要占领您的企业数据库。同样,我们预计Google Cloud、甲骨文与IBM将会在2018年积极以亏损方式抢占数据库迁移服务份额,并且越来越多的企业会在这一领域拼尽全力。
多云战略也将在混合云的管理方面发挥至关重要的作用。正如鲜有组织——无论其规模如何——倾向于依赖单一云供应商一般,也很少有组织(除了初创企业之外)会将全部的工作负载转移至云端。在云计算平台运行分析时,无论是在设计抑或是数据主权的问题上,维护敏感客户记录的透明度将会成为影响云计算平台选择的主要因素。
数据管道改变了实时处理的重心
去年,我们预测“物联网将成为把实时流数据推向前端的应用实例。”今年,谷歌方面的Anadiotis预测,不仅流数据将成为主流,“并且还将逐步实现即时分析。”
流数据分析并非是新鲜术语;在此之前,我们已经投入了大量精力以让其重拾关注。在进行数据存储之前,流数据处理可被用于数据的解析与过滤以及模式或事件的检测。物联网数据的爆炸式增长自然催生了难题——所有数据是否都需要存储以及在哪里完成数据的处理。
随着我们日益增长的技术需求,我们希望能够在数据运行的同时完成更多的工作负载。这不仅解释了用于队列处理的Kafka与分发数据技术的萌生,还表明了数据平台供应商——诸如SAP、 Hortonworks、MapR与 Teradata——正在采取相关行动的原因。 Amazon Kinesis、 Azure Data Factory以及 Google Cloud Dataflow的崛起亦是这类即时需求的直接产物。数据管道能够将实时处理从基础过滤与转换扩展为协调进程,从而支持高级预测分析与机器学习。因此,我们预计数据管道将在2018年成为流式分析的关键性支柱。此外,我们还将在这个领域听到来自于IBM与甲骨文等供应商所带来的更多消息。
云存储已在客观层面扮演数据湖角色
因为数据湖是专为保存那些不适合于其它位置且易丢失的数据而设计,所以当您想到数据湖时,您可能自然就会想到Hadoop。我们已经将数据湖定义为受管理的存储库,并致力于让其成为数据的默认提取点。但是,我们现在发现数据湖的安装启用超过了Hadoop。或者正如Mike Olson在2014年所预言的一般——Hadoop终将消失。
数据湖以联动查询工具作为起点,现已成为每个分析数据库的配套项目。我们已经见证了JSON数据库通过Spark进行扩展,从而实现分析查询。此外,我们还目睹了各Hadoop供应商(例如Cloudera 与 Hortonworks)将其数据管理服务与HDFS分离。所以,现在数据湖即是数据存储的位置所在。
毫无疑问,云供应商享有***的发言权:在云端,云存储显然已成为数据的默认摄取点。所以,云供应商正在致力于让其云对象存储配备直接查询功能。亚马逊方面现在已可通过S3直接访问配有Athena 的SQL 实际查询,并可作为Redshift Spectrum数据仓库的扩展。Google Cloud早已将其云存储作为BigQuery的默认来源,而Snowflake——第三方云数据仓库——也是如此。
此外,颇为讽刺的是,云存储最初其实专为存储需求而设计。然而,在云对象存储占据了大部分数据的世界里,催生了企业要优化访问需求。所以在2018年,我们预计几乎所有的数据仓库与分析数据库都将对接当下流行的云对象存储方案,具体包括S3、Azure BLOB Storage与Google Cloud Storage等支持目标。