古代,人们用牛来拉重物,当一头牛拉不动一根圆木时,他们不曾想过培育更大更壮的牛。同样,在面对计算能力不足时,我们也应尝试着结合使用更多的计算机系统。
Hadoop就是基于这样的理念设计。Hadoop是一个由Apache基金会所开发的分布式系统基础架构,计算分析处理所涉及的框架,允许多台设备一起工作,充分利用集群的威力进行高速运算和存储,共同完成一项任务,而对于用户来说这些设备是感知不到了,Hadoop技术屏蔽了底层的细节。

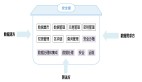
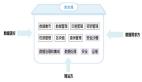
Hadoop***层是HDFS,也就是Hadoop文件系统,这个是分布式文件系统,由多台设备提供统一的存储空间,而用户感觉不到多台设备,只看到一个统一的存储空间,这也是云存储技术的基础。构建于HDFS的Hbase是天然的分布式数据库;MapReduce提供了云计算框架,它的数据来源也是分布式的,可以是HDFS,也可以是Hbase。
HBase是分布式数据产品,多台设备共同提供类似数据库的服务,但是这种服务是分布式,由多台设备来提供的,用户也完全感觉不到设备的存在,只知道有一个数据库给他们服务。这个也就是大数据库的基础。
在HBase之上,有MapReduce服务框架,也就是并行分析计算服务框架,可以支持各种分析应用并发的在多台设备上执行,完成一个共同的任务,原来1个人需要10天完成的任务,现在可以10个人1天完成,大大提升了数据分析的效率,这个也就是分布式计算的基础。
Pig、Hive等是数据分析的引擎,提供快速的数据分析接口和能力。
Hadoop主要有以下几个优点:
一是高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
二是高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
三是高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
四是高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
五是低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。