













本文主要介绍腾讯 SNG 开发全链路日志监控平台所经历的挑战及解决方案。
背景
全链路日志监控在现在盛行的微服务和分布式环境下,能有效地提高问题定位分析效率,成为开发和运维利器。
当前已有开源解决方案和成熟的厂商提供,比如 Twitter 的 zipkin,基于 Google 的 Dapper 论文设计开发了分布式跟踪系统,用于采集各处理节点间的日志和耗时信息,帮助用户排查请求链路的异常环节。
在有统一 RPC 中间件框架的业务部门比较容易接入 zipkin,但织云全链路日志监控平台(后成全链路)面对的实际业务场景更为复杂。
全链路日志监控实现遇到了更多的挑战,全链路技术选型经历了从开源组件到自研的变化。
当前织云全链路日志监控平台已接入空间和视频云业务日志数据,每日数据存储量 10TB,可做到 1/10 的压缩比,峰值流量 30GB/s。
我们先分享一个案例场景:
2017 年 8 月 31 日 21:40~21:50,X 业务模块指标异常,成功率由 99.988% 降为 97.325%,如下图所示:
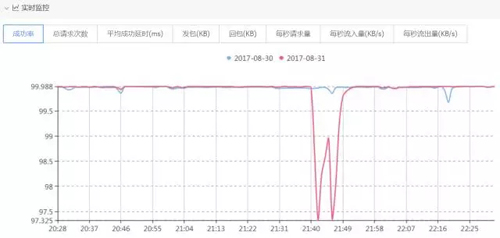
收到成功率异常告警后,在多维监控系统上通过画像下钻发现是空间点播业务的 iPhone 客户端成功率下降,返回码为-310110004。如下图:
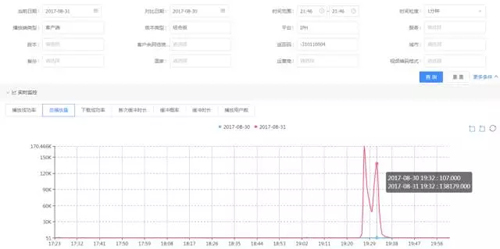
通过大盘多维数据分析发现异常原因后,因涉及 APP 问题,还需要进一步分析用户出现异常的上下文。
因而需要查看出现异常的用户在异常时间点的全链路日志数据。在全链路视图上,可以展示查询出来符合异常条件的用户日志和操作过程。
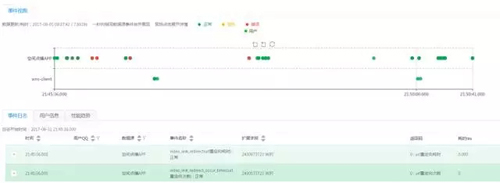
以上是从面到点的异常分析案例。
使用场景
全链路日志监控的使用场景主要有三大类:
- 个例分析,主要有处理用户投诉和从面到点的异常分析。
- 开发调试,主要用于开发过程中查看关联模块的日志和作为测试提单线索。
- 监控告警,主要是从日志数据中提取维度,统计为多维数据用于异常检测和原因分析。
遇到的挑战
在构建织云全链路日志监控平台时,织云监控模块经历了从传统监控和质量统计到大数据多维监控平台的转型。我们踩过了大数据套件的坑,也遇到过业务场景的挑战。
业务多样性挑战
QQ 体系内有丰富多样的业务,例如:手 Q、空间、直播、点播、会员等。
这些业务产生不同样式的日志格式,并且没有一致的 RPC 中间件框架。这个背景决定系统需要支持灵活的日志格式和多种采集方式。
海量数据挑战
同时在线超 2 亿用户上报的状态数据,日存储量超 10T,带宽超过 30GB/s,需要稳定和高效的数据处理、高性能和低成本的数据存储服务。
在使用开源组件完成原型开发后,逐渐遇到性能瓶颈和稳定性挑战,驱使我们通过自研逐渐替换开源组件。
应对挑战
日志多样化
日志的价值除提供查询检索外,还可做统计分析和异常检测告警。为此我们将日志数据规范化后分流到多维监控平台,复用监控平台已有的能力。
基于前面积累的监控平台开发经验,我们在织云全链路日志监控平台设计时取长补短,通过自研日志存储平台解决开源存储组件遇到的成本、性能和稳定性瓶颈。
织云全链路日志监控平台提供了 4 种数据格式支持,分别是:
- 分隔符
- 正则解析
- json 格式
- api 上报
分隔符、正则解析和 json 格式用于非侵入式的数据采集,灵活性好。但是服务端的日志解析性能较低,分隔符的数据解析只能做到 4W/s 的处理性能。
而 api 方式则能达到 10W/s 处理性能,对于内部业务,我们推荐采用统一的日志组件,并嵌入 api 上报数据。
系统自动容灾和扩缩容
对于海量的日志监控系统设计,***步是将模块做无状态化设计。比如系统的接入模块、解析模块和处理模块,这类无需状态同步的模块,可单独部署提供服务。
但对这类无状态业务模块,需要增加剔除异常链路机制。也就是数据处理链路中如果中间一个节点异常,则该节点往后的其他节点提供的服务是无效的,需要中断当前的链路,异常链路剔除机制有多种,如通过 zk 的心跳机制剔除。
为避免依赖过多的组件,我们做了一个带状态的心跳机制。上游节点 A 定时向下游节点 B 发送心跳探测请求,时间间隔为 6s,B 回复心跳请求时带上自身的服务可用状态和链路状态。
上游节点 A 收到 B 心跳带上的不可用状态后,如果 A 下游无其他可用节点,则 A 的下游链路状态也置为不可用状态,心跳状态依次传递,最终自动禁用整条链路。
有状态的服务通常是存储类服务,这类服务通过主备机制做容灾。如果同一时间只允许一个 master 提供服务则可采用 zk 的选举机制实现主备切换。
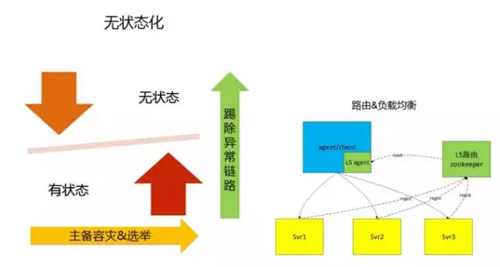
做到系统自动容灾和扩缩容的第二步是实现通过路由机制实现名字服务和负载均衡。
使用开源组件 zookeeper 能快速实现名字服务功能,要求在服务端实现注册逻辑,在客户端实现路由重载逻辑。
数据通道的容灾
我们采用两种机制:
- 双写方式,对于数据质量要求高的监控数据,采用双写方式实现。这种方式要求后端有足够的资源应对峰值请求,提供的能力是低延时和高效的数据处理能力。
- 消息队列,对于日志数据采用具备数据容灾能力的消息队列实现。使用过的选型方案有 kafka 和 rabbitmq+mongodb。
采用消息队列能应对高吞吐量的日志数据,并带有削峰作用,其副作用是在高峰期数据延时大,不能满足实时监控告警需求。
采用消息队列还需要注意规避消息积压导致的队列异常问题,例如使用 kafka 集群,如果消息量累积量超过磁盘容量,会造成整个队列吞吐量下降,影响数据质量。
我们后来采用 rabbitmq+mongodb 方案:数据在接入层按 1 万条或累积 30s 形成一个数据块,将数据库随机写入由多个 mongodb 实例构成的集群。再将 mongodb 的 ip 和 key 写入 rabbitmq 中。
后端处理集群从 rabbitmq 获取待消费的信息后,从对应的 mongodb 节点读取数据并删除。通过定时统计 rabbitmq 和 mongodb 的消息积压量,如何超过阈值则实施自动清理策略。
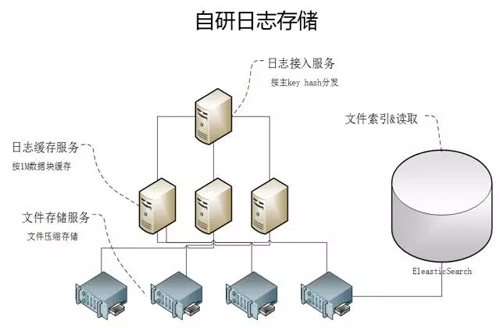
查询
日志的存储方案为应对高效和低成本查询,我们采用自研的方式实现。全链路上报的数据按用户 ID 或请求 ID 作为主 key 进行 hash 分片。
分片后的数据在缓存模块累积 1min 或 1M 大小,然后写入文件服务器集群;文件写入集群后,将 hash 值与文件路径的映射关系写入 Elastic Search。
查询数据提供两类能力:
- 按主 key 查询。查询方式是对待查询 key 计算 hash 值,从 ES 中检索出文件路径后送入查询模块过滤查找。
- 非主 key 的关键字查找。根据业务场景,提供的查询策略是查询到含关键字的日志即可,该策略的出发点是平衡查询性能,避免检索全量文本。
也就是***次查询 1000 个文件,如果有查询结果则停止后续的查询;如果无查询结果返回,则递增查找 2000 个文件,直到查询 10 万个文件终止。
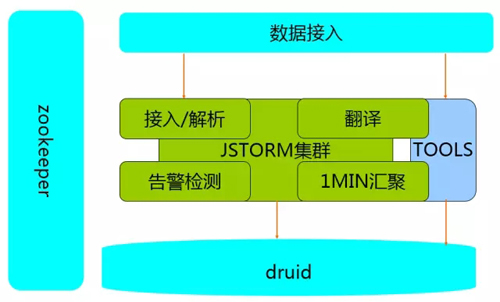
为满足多样的业务场景,我们在数据处理模块抽象了 ETL 能力,做到插件化扩展和可配置实现,并提供统一的任务管理和集群管理能力。
总结
全链路日志监控的开发过程有以下经验可借鉴:
- 使用成熟的开源组件构建初级业务功能。
- 在业务运行过程中,通过修改开源组件或自研提升系统处理能力和稳定性,降低运营成本和提升运维效率。
- 采用无状态化和路由负载均衡能力实现标准化。
- 抽象提炼功能模型,建立平台化能力,满足多样业务需求。
























