背景
一月中旬,ZDI宣布了2017年比赛的规则,其中包括了攻破VMware,完成虚拟机逃逸的队伍会获得相当高额的奖金。VMware已经不是一个新目标了。在2016年,VMware就被确定为攻击目标。
作为攻击目标,VMware已经经历过各种各样的攻击,攻击点很多。
有趣的是,早在2006-2009年间,就有针对D&D和C&P的漏洞而完成虚拟机逃逸了。然而在2015年Kostya Kortchinsky和lokihardt又在D&D和C&P中发现了类似的漏洞。从此,研究员们开始对这些代码更加深入的研究。
从我们旁观者的角度,这一现象是令人深思的。我们在想,VMware的漏洞一共有多少?其中又有哪些能被我们发现?
虽然一系列的漏洞被曝光,但是在2016年的Pwn2Own上,没有一支队伍能够成功完成虚拟机逃逸。虽然像VMware这样的传统桌面软件不是我们的研究领域。但我们还是对寻找VMware中的漏洞非常感兴趣。
我们决定面对这个挑战,看看挖掘VMware中的漏洞到底有多困难。我们定了一个计划,用一个月的业余时间来寻找漏洞。虽然我们没能在Pwn2Own前完成,但我们确实发现了一些高危漏洞,并且尝试通过这些漏洞找到VMware中可利用的攻击点。
攻击面
之前并不了解VMware的细节,我们开始不清楚实施攻击应该从何处着手。关注指令模拟的内部细节会有帮助么?有些CPU支持VT,又有多少指令是被模拟的?为了避免与他人撞洞,除了打印和像D&D或C&P的主机客户机交互外,还剩下什么呢?
下文是我们的研究成果,正如Pwn2Own规定的,所有的漏洞都要能被虚拟机里的普通用户所利用。
VMWare模块
在VMware的各种模块中,GUI是最不受关注的部分。VMware在主机和虚拟机端都有内核模块(至少有vmnet/VMCI),thnuclnt(负责虚拟打印),vmnet-dhcpd,vmnet-natd,vmnet-netifup,vmware-authdlaucher,vmnet-bridge,vmware-usbarbitrator,vmware-hostd,还有虚拟机端最重要的vmware-tools。
几乎所有的这些模块都是作为特权进程运行,这使得他们成为被研究者分析的对象。虚拟打印已经被攻击多次了。
vmnet-dhcpd吸引了我们的注意,因为他以root模式运行并且是从ISC-DHCPD演变而来。更令人感兴趣的是,vmware-dhcpd基于isc-dhcp2。我们开始把它作为攻击目标。
然而,当我们发现公开的漏洞后(CVE-2011-2749,CVE-2011-2748)我们就放弃了这一想法。VMware为了防止漏洞,已经在最新的isc-dhcp中修补了漏洞。
于是我们决定在QEMU和AFL对vmware-dhcpd的一些小补丁进行fuzz测试。一个月的fuzzing并没有显示出任何漏洞。vmware-hostd也是一个令人感兴趣的进程,它作为一个web服务器,用于虚拟机共享,而且可以从虚拟机内部访问到。然而,我们还是决定把精力投入研究VMware的核心组件。
vmware-vmx是最主要的虚拟机监管模块,在主机上作为root/系统进程运行,拥有一些令人感兴趣的特性。事实上,它有两个版本,vmware-vmx和vmware-vmx-debug。
如果VMware的设置中调试选项被启用,那么使用的就是后者。这一点很重要,因为当我们进行逆向工程时,从拥有很多调试信息的版本开始总会简单许多。或许这不是最适合的方法,但却很有效。后面我们会讲到。
RPC/RPCI
你可曾经想过VM和主机之间的文件拖放功能是如何实现的?RPC在其中发挥了重要的作用。VMware内部在0x5658端口上提供了一个接口作为“后门”。通过这个端口,虚拟机可以通过I/O指令来和主机进行通信。
通过寄存器传递一个VMware可识别的魔数,VMware会自动解析附加的参数。I/O指令通常都是特权指令,但这个“后门”接口是个例外。这种例外是很少的。当执行一个后门I/O指令时,VMware会进行一系列的判断,判断该I/O指令是否来自拥有特权的虚拟机。
在这个“后门”接口的上层,VMware使用了RPC服务在主机和客户机之间交换数据。在客户机端,vmware-toolsd执行“后门”命令的同时,使用了RPC服务。
这就是为什么之后在安装了vmware-toolsd的客户机上,你才能使用像拖放文件这样的功能。内核驱动和用户空间功能的结合利用实现了这一功能。
在最初的“后门”接口中只能通过寄存器来传递数据,面临大量数据的传输时,速度会变得很慢。为了解决这个问题,VMware引入了另一个端口(0x5659)来实现高带宽的“后门”。实际上这个端口是被RPC使用。
通过传递一个数据指针,vmware-vmx不用重复的调用IN指令,直接调用read/write API就可以完成数据的传输,Derek曾经就在这个功能里发现了一个非常有趣的漏洞。
RPC接口提供了以下的功能:
- 打开通道
- 发送命令长度
- 发送数据
- 接受回复的长度
- 接受数据
- 结束互动
- 关闭通道
你可能会想如何防止进程扰乱RPC的交互,建立一个通道时,VMware会生产两个cookie值,用它们来发送和接受数据。显然,这两个cookie是以安全的方式生成的。由于这两个cookie就是两个32位的无符号整数,不能用memcmp和其他方式来比较它们。
在上层,VMware还用RPC命令来处理DnD,CnP,Unity和其他的事件。有些命令只能在虚拟机特权用户下执行。在虚拟机端。vmware-tool或open-vm-tools提供了rpctool用来和API交互。保存和获取虚拟机信息的一个简单的例子如下:
- rpctool 'info-set guestinfo.foobar baz'
- rpctool 'info-get guestinfo.foobar' -> baz
在vmware-vmx中保存信息并随后提取出来。数据的储存方式的细节不在本文的讨论范围内。VMware内部使用了VMDB,这是一个关键词存储的数据库,有为特定数据提供回调函数的功能。
然而,能在非特权虚拟机中调用的RPC命令数量有限。我们并不能提供一个完整的RPC命令列表,因为这和版本以及操作系统相关。最简单获取命令列表的方式是从内存中把命令列表dump下来。
令人欣慰的是,Linux版本的vmware-vmx提供了符号,我们可以轻松的获取到它。
最令人感兴趣的攻击点就是D&D,C&P和Unity了。然而我们并没有研究它,原因有二。第一,lokihardt已经在Pwnfest中成功利用它了。更重要的是,在Pwn2Own2016中,不允许使用Unity和虚拟打印中的漏洞。
由于这潜在的风险,我们预计2017年VMware和ZDI会对与隔离设置无关的虚拟机逃逸更感兴趣。虽然Pwn2Own 2017并没给出比赛规则的细节,但我们不愿意承担着潜在的风险。最终,我们决定不挖RPC中的漏洞。
尽管如此,值得一提的是RPC中可以被攻击利用的点很多,因为它提供了操控堆内存的功能。
外围设备的虚拟化
还有没有其他的攻击点呢?VMware的核心代码实现了指令的虚拟化,同时也要为客户机提供各种各样的虚拟的外围设备。这些设备包括了网络、USB、蓝牙、硬盘、图像接口等等。
用户空间服务,虚拟机内核驱动,和vmware-vmx一起来给虚拟化设备提供服务。例如,VMware在虚拟机内部提供了SVGA图形卡适配器,作为PCI显示设备驱动。
在Linux上,修改vmwgfx内核模块的X代码,来建立一个vmware-vmx中SVGA3D/2D的接口层。我们认为,在现代操作系统中,默认开启的虚拟化的外围设备是一个范围很大的攻击面。所以我们在寻找默认启用的,具有广大攻击面,并且能够fuzz的模块。最后我们选择了图形接口。
寻找渲染器中的漏洞
由于比赛平台是Windows10上的VMware Workstation,我们决定在Windows而不是Linux上研究图形接口。值得一提的是,Gallium的svga代码中关于VMware图形驱动的开源实现给了我们很大帮助,帮助我们分析vmware-vmx的相关部分。同样的,微软的图形设备驱动例程也对我们理解Windows驱动的工作方式有很大帮助。
其他人曾经攻击过SVGA命令,我们决定深入研究,在这复杂的模块的特定的功能中寻找漏洞:GPU渲染器的翻译模块。选择渲染器字节码而不是SVGA命令的一个重要原因是:渲染器字节码可以从虚拟机内部提供。
在linux和Mac上,渲染器是以OpenGL实现。在Windows上,以Direct3D实现。因为VMware要支持不同的虚拟机操作系统,各种渲染器的代码都要被翻译成主机上的渲染器行为。我们认为,在这样高度复杂的模块中,随之而来的是各种各样的漏洞。
我们最初的分析是基于VMware Workstation 12.5.3的。
架构
VMware中有两种GPU的实现。一种是VGPU9(对应DirectX 9.0),在Linux虚拟机和旧版本Windows虚拟机上使用。另一种是VGPU 10,在Windows10上使用。
对于3D加速图形接口,VMware在Windows10虚拟机上使用WDDM(微软显示驱动模型)驱动。这个驱动由用户部分和内核部分组成。用户部分是vm3dum64_10.dll,内核部分是vm3dp.sys。当使用Direct 3D渲染器时,字节码要经历多次的翻译。
由于VMware提供了虚拟3D支持,这些字节码不能直接使用。它们会被进一步的翻译,Direct 3D API需要使用对应的渲染器实现。因此,用户空间驱动实现了保存在D3D10DDI_DEVICEFUNC结构中回调函数。它们把字节码翻译成对应的API。
在这种情况下,VMWare SVGA3D定义了API,设置了渲染器。处理渲染器字节码时,用户空间驱动会调用内核驱动提供的pfnRenderCB回调函数。
任何需要GPU渲染器的Windows程序都要使用Windows D3D11 API。这些API负责翻译文件中的渲染器字节码,设置为不同种类的渲染器。大致的翻译过程如下图。
这个过程包含了很多其他的细节,涉及到的D3D11 API数量也很多。有兴趣的读者可以查看微软提供的Direct3D11实例,并用Windbg来跟踪调试它。(使用Windbg的wt命令)
- 0:000> x /D /f Tutorial03!i*
- A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
- 00000000`00da1900 Tutorial03!InitDevice (void)
- 00000000`00da28f0 Tutorial03!InitWindow (struct HINSTANCE__ *, int)
- 00000000`00da3630 Tutorial03!invoke_main (void)
- 00000000`00da3620 Tutorial03!initialize_environment (void)
- 00000000`00da4680 Tutorial03!is_potentially_valid_image_base (void *)
- 00000000`00da637a Tutorial03!IsDebuggerPresent (<no parameter info>)
- 00000000`00da63c8 Tutorial03!InitializeSListHead (<no parameter info>)
- 00000000`00da63aa Tutorial03!IsProcessorFeaturePresent (<no parameter info>)
- 0:000> bp Tutorial03!InitDevice
- 0:000> g
- Breakpoint 0 hit
- Tutorial03!InitDevice:
- 00da1900 55 push ebp
- 0:000:x86> wt -l 8
- Tracing Tutorial03!InitDevice to return address 00da2dfe
- 259 0 [ 0] Tutorial03!InitDevice
- 100 0 [ 1] USER32!GetClientRect
- ...
构造渲染器的输入数据
在和VMware的渲染器交互时,了解渲染器的原理是很重要的。
编写DirectX的渲染器,需要使用高层渲染语言(HLSL)。用D3D11 API或者fxc.exe程序把它编译成字节码。根据渲染器模型的不同,HLSL提供了不同种类的渲染器特征。
HLSL编译结果是以渲染器模型的汇编字节码的形式给出的。VMware目前在内部支持SM3和SM4,但不支持SM5和SM6。这对我们在逆向vmware-vmx中的翻译单元是很重要的。
不幸的是,在windows平台上,除了用HLSL外没有其他生成渲染器字节码的工具了。因此,构造精确的输入来触发漏洞就显得很有难度了。CSO文件还需要修复校验值。检查校验值的函数是D3D11_3SDKLayers!DXBCVerifyHash
为了能给VMware提供任意的渲染器字节码输入,我们使用了强大的Frida工具来hook和修改渲染器字节码。当vm3dum64_10.dll把编译好的字节码放入内存后,我们就改变成我们想输入的任意字节码。通过逆向工程,我们确定了相应的memmove()位置并且hook了它。
下面是我们Frida代码的一部分。
- var vm3d_base = Module.findBaseAddress("vm3dum64_10.dll");
- console.log("base address: " + vm3d_base);
- function ida2win(addr) {
- var idaBase = ptr('0x180000000');
- var off = ptr(addr).sub(idaBase);
- var res = vm3d_base.add(off);
- console.log("translated " + ptr(addr) + " -> " + res);
- return res;
- }
- function start() {
- var memmove_addr = ida2win(0x180012840);
- var setShader_return = ida2win(0x180009bf4);
- Interceptor.attach(memmove_addr, {
- onLeave : function (retval) {
- if (!this.hit) {
- return;
- }
- Memory.writeU32(this.dest_addr.add(...), ...);
- ....
- },
- onEnter : function (args) {
- var shaderType = Memory.readU8(args[1].add(2));
- if (!this.returnAddress.compare(setShader_return)) {
- if (shaderType != 1) { return; }
- this.dest_addr = args[0];
- this.src_addr = args[1];
- this.len = args[2].toInt32();
- this.hit = 1;
- ...
- });
- }
上面的代码使用了Frida的劫持了vm3dum64_10中的memmove()的控制流。每当代码进入memmove()时,返回值和setShader()进行比较。相同的话,就在退出memmove()前修改内存中的字节码。
在我们的研究过程中,值得注意的是,我们了解到Marco Grassi和Peter Hlavaty展示过渲染器的fuzzing。其中提到VMware提供了一个渲染器的工具包和一些实例。这就是他们进行fuzzing的基础,他们的研究成果可以在这里找到。
寻找漏洞
VMware是一个巨大的软件,我们不知道如何从vmware-vmx中识别出渲染器的翻译函数。只有两种途径:一种是直接识别渲染器的翻译单元。第二种是通过SVGA3D命令处理函数,通常是下面几种:DXDDefine,DXBindShader,DefineSurface。
二进制文件中查找字符串是相对简单的,下图就是SVGA3d命令中使用的字符串。
用这些字符串并不直接找到对应的处理函数,但是,通过X引用可以找到内存中另一张表。

用字符串表中的偏移把他们标注出来,就能找到直接的处理函数。由于它们最终用来控制渲染器的操作,跟着这些函数就能找到解析和翻译的代码。在内部的实现中,内核驱动和vmware-vmx是以先进先出的数据结构实现的,用来把SVGA3D命令压入堆中传递给监管器。然后这些模块取出数据并进一步处理。
有两种办法能直接找到渲染器的代码。第一种,使用vmware-vmx-debug中的字符串,能直接找到解析和翻译的代码。我们开始跟随了字符串“shaderParseSM4.c”和“shaderTransSM4.c”的交叉引用。但是审计debug版本的代码漏洞有一个巨大的缺陷,debug版本有很多检查函数,这在发行版中是没有的。
我们不清楚这是不是VMware设计上的缺陷,在审计vmware-vmx的代码的过程中。在debug版本中,解析模块和翻译模块中有着大量的严格的安全检查。在发行版本中就没有。
于是,我们利用在debug版本中搜索到的立即数参数来在非debug版本中定位,这大大的增强了IDA代码的可读性。多亏了mesa驱动程序的帮助,我们才能知道我们需要搜索的是什么。
比如,mesa驱动程序中关于VGPU10的定义对我们的分析有着很大的帮助。
当vmware-vmx需要把虚拟机的渲染器代码转化为主机的渲染器代码,它会首先解析虚拟机内部库函数打包好的渲染器字节码。由于缺少底层的渲染器字节码的资料,逆向这个解析函数,并且构造各种输入,花费了我们大量的时间。
最初的解析过程比较简单,ParserSM4()函数只是保存了参数。
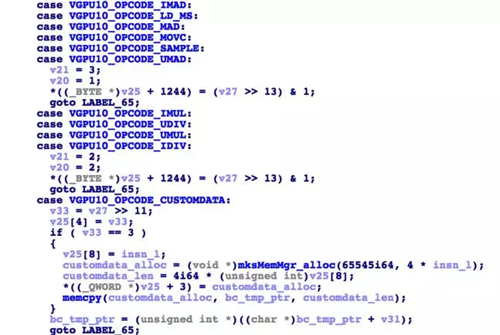
parser解析字节码时,和其他的parser相似。渲染器代码的长度告诉parser应该何时停止解析。每个字节码都有一个种类,一个指令长度,和一个值。具体的说,每个字节码头部的0:10位确定字节码的种类,11:23位来编码字节码的数据,30:24位来记录字节码的数据长度,第31位记录字节码是否扩展(通常情况下没有)
由于大部分的字节码包括的值都是一个字节长度,parser都是把这个字节的值复制到未知的数据结构中,上图中的VGPU10_OPCODE_CUSTOMDATA是一个例外。因为它包含了一个缓冲区,dcl_immediateConstantBuffer有描述。
就像上面提到的,我们并不清楚内部使用的数据结构。但是,这对寻找翻译单元中的漏洞无关紧要,因为数据结构中使用的偏移是一样的。因此,如果我们知道了输入的字节码是什么,再来审计TransSM4的二进制代码就很方便了。
总体来说,这还是一个很耗费时间的步骤。第一,我们开始不了解渲染器和VMware的图形接口虚拟化的知识,寻找关键点就花了不少时间。第二,缺少直接生成sm4字节码的工具,我们只能用Frida来动态hook函数中的字节码。
最后,了解SM4指令的细节和原理也是个巨大的工程。除了调试器外,还有一些能帮助我们进行逆向工程的。vmware-vmx的debug版本中的ASSERT断言能帮我们了解运行错误。
ParseSM4()函数提供了一个渲染器的反汇编函数,能够用来提取渲染器字节码,记录在VMware的log日志中。
成果
现在我们来看看在人工逆向后我们发现的一些成果,2017年3月17号,在Pwn2Own,我们把这些漏洞和Poc提交给了ZDI。
1、翻译dcl_immediateConstantBuffer字节码时存在堆溢出
解析一个名为 VGPU10_OPCODE_CUSTOMDATA 的 token时(定义了一个缓冲区),执行了下面的伪代码:
- case VGPU10_OPCODE_CUSTOMDATA:
- v41 = v23 >> 11;
- *(_DWORD *)(_out_p_16_ptr + op_idx + 16) = v41;
- if ( (_DWORD)v41 == VGPU10_CUSTOMDATA_DCL_IMMEDIATE_CONSTANT_BUFFER )
- {
- *(_DWORD *)(_out_p_16_ptr + op_idx + 32) = insn_l;
- custom_data_alloc = (void *)mksMemMgr_alloc(v41, 0x10009u, 4LL * (unsigned int)insn_l);// int overflow safe
- *(_QWORD *)(_out_p_16_ptr + op_idx + 24) = custom_data_alloc;
- memcpy(custom_data_alloc, bc_tmp_ptr, 4LL * *(unsigned int *)(_out_p_16_ptr + op_idx + 32));
- v37 = 0;
- insn_start = (int *)bc_tmp_ptr;
- }
这时insn_l表示一个在用户数据指令中编码的32位的常数,一般渲染器指令不会用到32位长度的值,所以这是一个比较特殊的情况。这个数表示了用户数据块长度。代码中没有对这个长度做任何限制。
mksMemMgr_alloc在内部调用了calloc,分配了一个长度为159384的堆。calloc函数是由msvcr90.dll提供的。我们发现msvcr90.dll总是被映射到4G内存的最底端。
Windows 10上的calloc函数通过RtlAllocateHeap在NT堆中分配内存。我们会在outbuf中使用这块内存,这块内存是完全被攻击者控制的。
分配完这块内存后,翻译阶段就结束了。遇到VGPU10_OPCODE_COSTOMDATA这个token。memcpy会被调用,而没有经过进一步的安全检查。
- result = memcpy(outbuf + 106228, custom_data_alloc, 4 * len);
custom_data_alloc是我们在上面的parsing步骤中分配的缓冲区。这使我们能够把精心设计好的数据写入到相邻堆块的头部中。这些相邻的堆块是之前解析过的字节码,它们也被分配这一个内存区域。
2、翻译dcl_indexableTemp字节码时存在堆越界写入漏洞
在处理dcl_indexabletemp指令时,渲染器解析模块会调用下面的伪代码
- case VGPU10_OPCODE_DCL_INDEXABLE_TEMP:
- *(_DWORD *)(_out_p_16_ptr + op_idx + 16) = *insn_start;// index
- *(_DWORD *)(_out_p_16_ptr + op_idx + 20) = insn_start[1];// index + value for array write operation in Trans
- bc_tmp_ptr = insn_start + 3;
- *(_DWORD *)(_out_p_16_ptr + op_idx + 24) = insn_start[2];
在上面的伪代码中,指令的一部分被写到了op_idx中,这些值会在后面的翻译模块中用到。在解析过程中,没有对这些值的任何限制。
下面的代码表示了翻译过程
- case VGPU10_OPCODE_DCL_INDEXABLE_TEMP:
- v87 = *(_DWORD *)(bytecode_ptr + op_idx + 24);
- svga3d_dcl_indexable_temp((__int64)__out,
- *(_DWORD *)(bytecode_ptr + op_idx + 16),// idx
- *(_DWORD *)(bytecode_ptr + op_idx + 20),// val
- (1 << v87) - 1); // val2
我们可以看到,在调用svga3d_dcl_indexable_temp()时,使用了相同的偏移值(20,16,24)。idx和val是被攻击者直接控制的。第4个参数是由上面的第三个双字运算得出((1<<val2)-1)
进入svga3d_dcl_indexable_temp()函数
- __int64 __fastcall svga3d_dcl_indexable_temp(__int64 a1, unsigned int idx, int val, char val2)
- {
- __int64 result; // rax@5
- const char *v5; // rcx@7
- const char *v6; // rsi@7
- signed __int64 v7; // rdx@7
- *(_DWORD *)(a1 + 8LL * idx + 0x1ED80) = val;
- *(_BYTE *)(a1 + 8LL * idx + 0x1ED84) = val2;
- *(_BYTE *)(a1 + 8LL * idx + 0x1ED85) = 1;
- result = idx;
- return result;
在上面的代码中,a1是翻译过程中使用的堆块,和我们前面讨论过的用户数据块是一样的。以0x1ed80为基址,我们可以向任意偏移写入一个32位的dword值。
综上,这个漏洞能让我们在先前提到的堆结构中向任意地址写入一个双字值。还能够写入两个字节,由val来控制(剩下的两个字节为0)。
3、翻译dcl_resource字节码时存在栈越界写入漏洞
翻译过程中处理dcl_resource指令时,下述代码会被执行:
- int hitme[128]; // [rsp+1620h] [rbp-258h]@196
- int v144; // [rsp+1820h] [rbp-58h]@204
- char v145; // [rsp+1824h] [rbp-54h]@303
- bool v146; // [rsp+1830h] [rbp-48h]@14
- char v147; // [rsp+1831h] [rbp-47h]@14
- int v148; // [rsp+1880h] [rbp+8h]@1
- __int64 v149; // [rsp+1890h] [rbp+18h]@1
- __int64 v150; // [rsp+1898h] [rbp+20h]@14
- ...
- case VGPU10_OPCODE_DCL_RESOURCE:
- v87 = sub_1403C2200(*(_DWORD *)(v14 + 32));
- v88 = sub_1403C2200(*(_DWORD *)(v14 + 28));
- v89 = sub_1403C2200(*(_DWORD *)(v14 + 24));
- v90 = sub_1403C2200(*(_DWORD *)(v14 + 20));
- sub_1402FCF10(&v107, (__int64)outptr, *(_DWORD *)(v14 + 80), v86, v90, v89, v88, v87);
- v11 = 0i64;
- hitme[(unsigned __int64)*(unsigned int *)(v14 + 80)] = *(_DWORD *)(v14 + 16);
我们没有跟入研究sub_1403c2200()函数的细节,这个函数无关紧要,因为它对栈的结构没有影响。偏移(v14+80)又是完全受输入的渲染器字节码控制的。但是被写入的值是受到一定的限制。只能是0-31。
这意味着我们可以写入很多对齐的双字。这里我们用了复数形式,因为这个漏洞可以被触发多次,向hitme开始到4G的地址写入0-31。
这个漏洞的可利用性跟VMware的版本和操作系统有关。很明显,在不同的版本或操作系统中,栈的布局是不一样的。
4、不安全的内存映射导致绕过DEP
在vmware-vmx监管进程启动时,创建了一些内存映射。令人惊讶的时,其中一块内存映射是以读,写,可执行的权限创建的。在整个进程的生命周期中都是如此。这样的内存映射只有一块。这里创建的内存映射是vmware-vmx进程data区段的第一个页。
- 7ff7`36b53000 7ff7`36b54000 0`00001000 MEM_IMAGE MEM_COMMIT PAGE_EXECUTE_READWRITE Image [vmware_vmx; "C:\Program Files (x86)\VMware\VMware Workstation\x64\vmware-vmx.exe"]
- 0:018> dq 7ff7`36b53000 L 0n1000/8
- 00007ff7`36b53000 ffffffff`ffffffff 00000001`fffffffe
- 00007ff7`36b53010 00009f56`1b68b8ce ffff60a9`e4974731
- 00007ff7`36b53020 00007ff7`36780a18 00007ff7`36780a08
- 00007ff7`36b53030 00007ff7`367809f8 00007ff7`367809e8
- 00007ff7`36b53040 00007ff7`367809d8 00000000`00000000
- 00007ff7`36b53050 00007ff7`36780990 00007ff7`36780940
- 00007ff7`36b53060 00007ff7`367808f0 00007ff7`367808a0
- 00007ff7`36b53070 00007ff7`36780860 00007ff7`36780820
- 00007ff7`36b53080 00007ff7`367807f0 00007ff7`367807a0
- 00007ff7`36b53090 00007ff7`36780750 00007ff7`36780700
显然,这大大的降低了虚拟机逃逸的漏洞,因为它提供了一个完美的执行shellcode的区域。
- data:0000000140B33000 _data segment para public 'DATA' use64
- ...
- 0000000140B33000 FF FF FF FF FF FF FF FF FE FF FF FF 01 00 00 00 ................
- 0000000140B33010 32 A2 DF 2D 99 2B 00 00 CD 5D 20 D2 66 D4 FF FF 2..-.+...] .f...
- 0000000140B33020 18 0A 76 40 01 00 00 00 08 0A 76 40 01 00 00 00 ..v@......v@....
- 0000000140B33030 F8 09 76 40 01 00 00 00 E8 09 76 40 01 00 00 00 ..v@......v@....
- 0000000140B33040 D8 09 76 40 01 00 00 00 00 00 00 00 00 00 00 00 ..v@............
- 0000000140B33050 90 09 76 40 01 00 00 00 40 09 76 40 01 00 00 00 ..v@....@.v@....
- 0000000140B33060 F0 08 76 40 01 00 00 00 A0 08 76 40 01 00 00 00 ..v@......v@....
- 0000000140B33070 60 08 76 40 01 00 00 00 20 08 76 40 01 00 00 00 `.v@.... .v@....
- 0000000140B33080 F0 07 76 40 01 00 00 00 A0 07 76 40 01 00 00 00 ..v@......v@....
- 0000000140B33090 50 07 76 40 01 00 00 00 00 07 76 40 01 00 00 00 P.v@......v@....
如图所示,内存是以读,写,可执行的方式分配的。Windbg中的dump只是想说明它是和IDA中的data区段是相符的。
总结
前两个漏洞是12.5.3版本中的0day漏洞,即使在比赛后,12.5.4版本还没有修复这些漏洞。
在12.5.4版本发布后不久,VMWare又发布了VMSA-2017-0006修补了这两个堆相关的漏洞。版本更新中的细节描述很模糊,我们并不知道这些漏洞是否被真正修补上了。
同样的,vmware-vmx的调试版本有着产品版本中没有的错误检查机制。根据ZDI的说法,这和其他人提交的漏洞并不冲突,VMSA-2017-006只提及了ZDI的报告。
结果就是,我们不知道这些漏洞有没有CVE ID,有没有其他的研究员发现了这些漏洞。
值得注意的是,ASSERT断言同样影响了其他的SM4指令。我们确信,直到12.5.5版本,至少dcl_indexRange和dcl_constantBuffer有着相似的堆越界写入漏洞。
dcl_resource漏洞在12.5.5版本中没有被修补。
目前我们认为最初补丁是针对内部代码的重构,而不是针对我们提交的漏洞的。因为在debug版本中的修补和发行版一样。使用了assert断言而不是错误处理函数。因此,我们依旧可以用这些漏洞来攻破VMware。
文中涉及的漏洞的PoC可以在https://github.com/comsecuris/vgpu_shader_pocs上找到。
其他
在这篇文章结束之前,我们还想说说我们工作中的一些发现,希望对你们有帮助。有以下几点:
不同环境下逆向工程的难度
当我们逆向分析vmware-vmx时,Linux版本中一些奇怪的内嵌函数特性使得逆向的难度大大提高(相比Windows和Mac)。比较后,我们发现竟然是Windows中的vwmare-vmx最适合逆向分析。
Linux版本中vmware-vmx的符号信息对逆向帮助很大。
设置
VMware为和渲染器的交互功能提供了很有用的设置选项。我们发现了mks.dx11.dumpShaders,mks.shim.dumpShaders和mks.gl.dumpShaders很有用。类似的设置还有很多。
PIE
在linux中,如果去掉vmware-vmx ELF文件中的PIE选项,vmware-vmx就不能正常工作了。在Mac中,使用change_macho_flage.py脚本可以成功处理vmware-vmx的重定位。这会让调试变得更加方便。
二进制翻译模块
完成上述的分析后,我们还在思考vmware-vmx中模拟x86指令的代码在哪里。我们开始认为会很容易发现这部分代码,然而,到目前为止,我们还找到相关的代码。一种可能是硬件的虚拟化。然而,根据设置和架构,VMware是可以运行在多种模式下的。这部分代码肯定在某个位置。
- binwalk vmware-vmx.exe
- DECIMAL HEXADECIMAL DESCRIPTION
- --------------------------------------------------------------------------------
- 0 0x0 Microsoft executable, portable (PE)
- ...
- 13126548 0xC84B94 ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)
- 13126612 0xC84BD4 ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)
- 14073118 0xD6BD1E Unix path: /build/mts/release/bora-4638234/bora/vmcore/lock/semaVMM.c
- 14256073 0xD987C9 Sega MegaDrive/Genesis raw ROM dump, Name: "tSBASE", "E_TABLE_VA",
- 14283364 0xD9F264 Sega MegaDrive/Genesis raw ROM dump, Name: "ncCRC32B64", "FromMPN",
- 14942628 0xE401A4 ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)
- 14949876 0xE41DF4 ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)
- 14954108 0xE42E7C ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)
- 14960892 0xE448FC ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)
- 14991124 0xE4BF14 ELF, 64-bit LSB relocatable, AMD x86-64, version 1 (SYSV)
binwalk分析ELF的结果看起来很奇怪,肯定有一些错误。我们暂时忽略这些错误。我们注意到内存中有个ELF头。使用binwalk工具(通常不会用binwalk来分析PE或ELF文件),我们发现了一些有趣的事情。
一个最大ELF文件看起来很有意思,因为他包含了一个巨大的函数,更重要的事,它还带有符号。
出乎我们的意料,这个内嵌的ELF带有x86反汇编的翻译单元。我们对他的工作方式很好奇,但我们并没有深入研究,毕竟这不是我们的目标,但这是一个很有趣的研究方向。
结语
很遗憾,在Pwn2Own上,我们没能完成最初设定好的目标,实现完整的虚拟机逃逸。但是,能在我们计划的时间内完成,我们还是很满意的。我们相信VMware不仅是一个漏洞挖掘的有趣的目标,而且VMware虽然实现了虚拟机的监视功能,它与传统的桌面程序差别并不大。
基于我们对攻击点的发掘和探测,我们相信VMware作为一个高度复杂且被广泛使用的软件,其中还有很多没被挖掘利用的攻击点。例如,我们仅仅分析了渲染器翻译单元的表面结构。
渲染器功能的内部的复杂实现还有待分析。与此类似,VMware的其他组件也被攻击过。看完我们分析完的代码和过去VMware提出的安全建议,最近的安全防御由被动变成了主动。
除了核心组件之外,还有很多值得研究的组件。比如vmware-hostd(支持SSL的web服务器)。我们希望能进一步研究虚拟机的安全问题,也欢迎其他人也来研究。