去噪自编码器(denoising autoencoder, DAE)是一类接受损坏数据作为输入,并训练来预测原始未被损坏数据作为输出的自编码器。
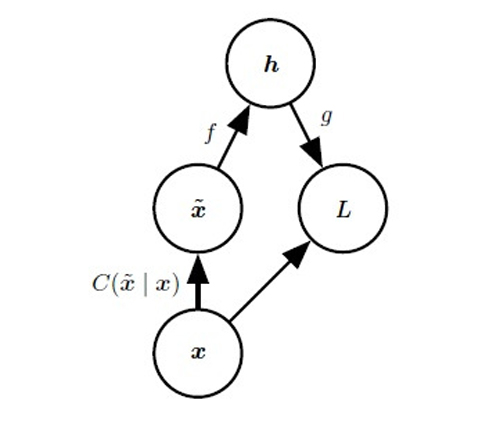
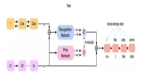
去噪自编码器代价函数的计算图。去噪自编码器被训练为从损坏的版本~x 重构干净数据点x。这可以通过最小化损失L = -log pdecoder(x|h = f(~x)) 实现,其中~x 是样本x 经过损坏过程C(~x| x) 后得到的损坏版本。
得分匹配是***似然的代替。它提供了概率分布的一致估计,促使模型在各个数据点x 上获得与数据分布相同的得分(score)。
对一类采用高斯噪声和均方误差作为重构误差的特定去噪自编码器(具有sig-moid 隐藏单元和线性重构单元)的去噪训练过程,与训练一类特定的被称为RBM 的无向概率模型是等价的。
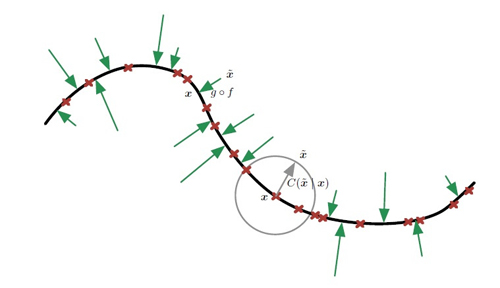
将训练样本x 表示为位于低维流形(粗黑线)附近的红叉。我们用灰色圆圈表示等概率的损坏过程C(~x|x)。灰色箭头演示了如何将一个训练样本转换为经过此损坏过程的样本。
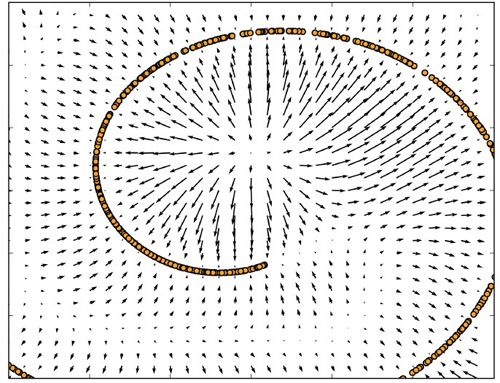
由去噪自编码器围绕1 维弯曲流形学习的向量场,其中数据集中在2 维空间中。每个箭头与重构向量减去自编码器的输入向量后的向量成比例,并且根据隐式估计的概率分布指向较高的概率。向量场在估计的密度函数的***值处(在数据流形上)和密度函数的最小值处都为零。例如,螺旋臂形成局部***值彼此连接的1维流形。局部最小值出现在两个臂间隙的中间附近。当重构误差的范数(由箭头的长度示出)很大时,在箭头的方向上移动可以显著增加概率,并且在低概率的地方大多也是如此。自编码器将这些低概率点映射到较高的概率重构。在概率***的情况下,重构变得更准确,因此箭头会收缩。
目前仅限于去噪自编码器如何学习表示一个概率分布。更一般的,我们可能希望使用自编码器作为生成模型,并从其分布中进行采样。