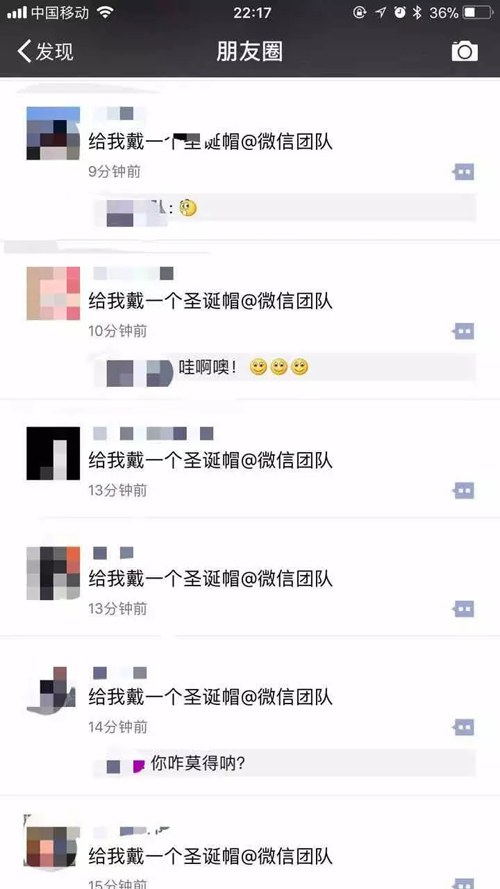
这几天,你的朋友圈一定被“请给我一顶圣诞帽@微信官方”刷屏了……很多不知真相的网友也纷纷求问如何给自己的头像加上圣诞帽。
圣诞帽火了,上亿人疯狂@微信官方
圣诞节到了,朋友圈悄悄地掀起一股加帽风,大家纷纷@微信官方,申请给自己的头像加圣诞帽。
圣诞帽搜索指数随之在 24 小时内狂飙:
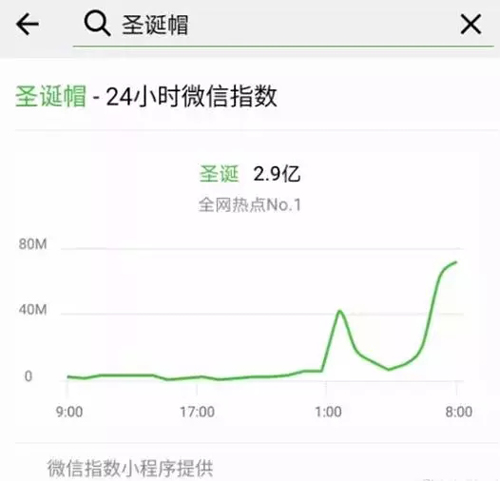
然后,一场花式求圣诞帽的仪式开始刷屏了,还混入了各种奇怪的东西。不料却发现@微信官方并不能带上圣诞帽,才知道“被骗”了。
一大波知道真相的网友随后开始把@微信官方变成了许愿池:

要钱和礼物的

讨房子的

要明星的
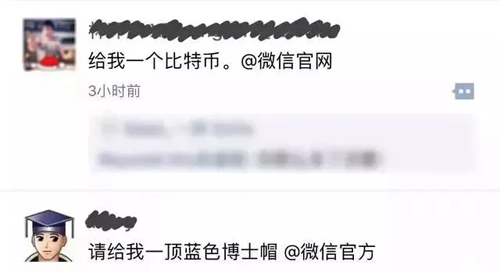
要博士帽的

求减肥的

还有送绿帽子的
网友们一边@微信官方许愿,一边默默的自己 P 上圣诞帽……戏精这波操作我给满分!
如何从技术上实现@微信官方头像添加圣诞帽?
那么,身为程序员,从技术的角度思考一下,这事儿到底能不能成呢?
首先看一下网上某猿的分析:
这体现了腾讯强大的人工智能实力,首先微信收到用户发送的朋友圈后,便获取用户头像上传至服务器云端,然后借助云计算和人脸识别,猪脸识别(来自友商京东的技术)和物体识别,根据头像角度、人脸大小,不断调整圣诞帽的尺寸和位置,***生成圣诞帽头像。
网友 @IT大智表示:
这个功能目前几乎是不可能实现的。首先要明确一点,所有 APP 或者网站都是由代码程序实现的。
假设微信想给用户添加圣诞帽,必须要再引用一次圣诞帽的图片地址,直接添加的话肯定要覆盖用户原来的头像,退一步腾讯可以做到图片叠加,那么也一定要定义图片的大小和位置。
所以微信最多做到在固定位置添加一个大小一定的帽子,大家想象一下微信用户的头像千差万别,人头位置也很不确定,圣诞帽怎么会正好加在头像头顶呢?
所以这是个谣言,类似于“明天是马化腾生日,转发本条信息到三个群会得到 200Q 币”等等。
不少好友都发布了请求添加圣诞帽的朋友圈并@了微信官方,但实际上微信只能@自己的好友,微信并没有推出自己的官方号,所以你在朋友圈@微信官方,微信的人能收到你的@信息吗?当然不能。
然而还有更厉害的:
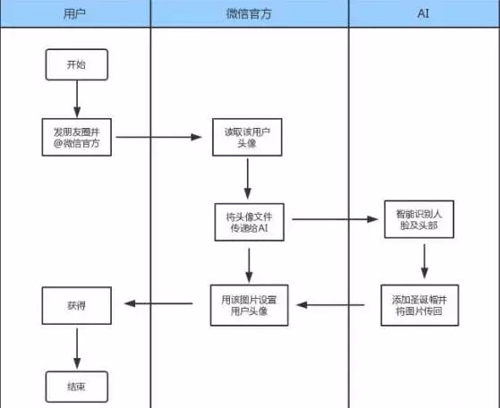
大致来说,当用户在朋友圈发布这样的文字消息:请给我头像一顶圣诞帽@微信官方。
微信官方会收到这个艾特,并通过该用户的 openid(微信用户的唯一标志 ID)获取到该用户的微信头像文件,将该图片和文本传至后台 AI。
所谓“自然语言”,就是我们人类平常说的话,一般情况下,计算机只能理解编程语言,不能理解人类说的话。
但是,腾讯 AI 可以进行“自然语言处理”,将“请给我头像一顶圣诞帽”这句话进行分解,并解读其中的意思。
至此,腾讯 AI 理解了该段文本的内容,通过智能图像处理技术,识别到人脸及头部,选择好合适的大小及方向,将提前准备好的圣诞帽图片与头像叠加,这样就生成了一张带圣诞帽的新头像,并将头像传至前端。
微信官方收到图片后,还是通过读取 openid 找到该用户,将该图片应用到该用户的头像,并提醒到该用户,整个过程不到五分钟。
当然,有些情形会难倒 AI,比如你的头像图片中有很多人,AI 就没法判断你到底要给哪个人添加圣诞帽,只能给所有人头上都添加一顶圣诞帽。
所以,大家还是不要调戏 AI,用一张美美的图片@微信官方就好!
当然啦,这只是对@微信官方求帽子的调侃,但是还真的有人站出来说,这事儿能成。
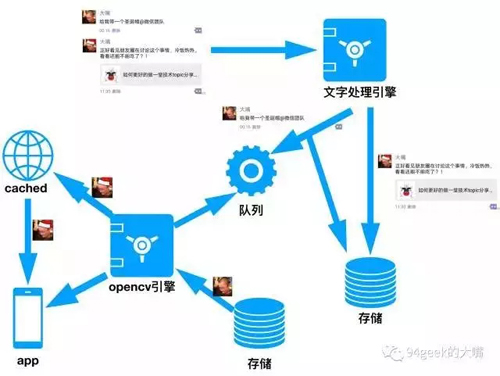
阅文集团***架构师徐海峰老师:
他表示使用大数据分析+AI+图片动态处理能够实现,架构图如下:
虽然微信暂时没有这个功能,但并不代表程序员们实现不了!在人工智能火爆的今天,看程序员如何用 Python 给自己戴上圣诞帽?
用 Python 给头像加上圣诞帽
大家纷纷@官方微信给自己的头像加上一顶圣诞帽,当然这种事情用很多 P 图软件都可以做到。
但是作为一个学习图像处理的技术人,还是觉得我们有必要写一个程序来做这件事情。
用到的工具
- OpenCV
- dlib(dlib 的人脸检测比 OpenCV 更好用,而且 dlib 有 OpenCV 没有的关键点检测。)
用到的语言为 Python,但是完全可以改成 C++ 版本。
操作的流程
素材准备
首先我们需要准备一个圣诞帽的素材,格式***为 PNG,因为 PNG 我们可以直接用 Alpha 通道作为掩膜使用,用到的圣诞帽如下图:

我们通过通道分离可以得到圣诞帽图像的 Alpha 通道,代码如下:
- r,g,b,a = cv2.split(hat_img)
- rgb_hat = cv2.merge((r,g,b))
- cv2.imwrite("hat_alpha.jpg",a)
为了能够与 rgb 通道的头像图片进行运算,我们把 rgb 三通道合成一张 rgb 的彩色帽子图,Alpha 通道的图像如下图所示:

人脸检测与人脸关键点检测
我们用下面这张图作为我们的测试图片:

下面我们用 dlib 的正脸检测器进行人脸检测,用 dlib 提供的模型提取人脸的五个关键点,代码如下:
- # dlib人脸关键点检测器
- predictor_path = "shape_predictor_5_face_landmarks.dat"
- predictor = dlib.shape_predictor(predictor_path)
- # dlib正脸检测器
- detector = dlib.get_frontal_face_detector()
- # 正脸检测
- dets = detector(img, 1)
- # 如果检测到人脸
- if len(dets)>0:
- for d in dets:
- x,y,w,h = d.left(),d.top(), d.right()-d.left(), d.bottom()-d.top()
- # x,y,w,h = faceRect
- cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2,8,0)
- # 关键点检测,5个关键点
- shape = predictor(img, d)
- for point in shape.parts():
- cv2.circle(img,(point.x,point.y),3,color=(0,255,0))
- cv2.imshow("image",img)
- cv2.waitKey()
这部分效果如下图:

调整帽子大小
我们选取两个眼角的点,求中心作为放置帽子的 x 方向的参考坐标,y 方向的坐标用人脸框上线的y坐标表示。
然后我们根据人脸检测得到的人脸的大小调整帽子的大小,使得帽子大小合适。
- # 选取左右眼眼角的点
- point1 = shape.part(0)
- point2 = shape.part(2)
- # 求两点中心
- eyes_center = ((point1.x+point2.x)//2,(point1.y+point2.y)//2)
- # cv2.circle(img,eyes_center,3,color=(0,255,0))
- # cv2.imshow("image",img)
- # cv2.waitKey()
- # 根据人脸大小调整帽子大小
- factor = 1.5
- resized_hat_h = int(round(rgb_hat.shape[0]*w/rgb_hat.shape[1]*factor))
- resized_hat_w = int(round(rgb_hat.shape[1]*w/rgb_hat.shape[1]*factor))
- if resized_hat_h > y:
- resized_hat_h = y-1
- # 根据人脸大小调整帽子大小
- resized_hat = cv2.resize(rgb_hat,(resized_hat_w,resized_hat_h))
提取帽子和需要添加帽子的区域
按照之前所述,去 Alpha 通道作为 mask,并求反。这两个 mask 一个用于把帽子图中的帽子区域取出来;一个用于把人物图中需要填帽子的区域空出来。
- # 用alpha通道作为mask
- mask = cv2.resize(a,(resized_hat_w,resized_hat_h))
- mask_inv = cv2.bitwise_not(mask)
后面你将会看到:
从原图中取出需要添加帽子的区域,这里我们用的是位运算操作:
- # 帽子相对与人脸框上线的偏移量
- dh = 0
- dw = 0
- # 原图ROI
- # bg_roi = img[y+dh-resized_hat_h:y+dh, x+dw:x+dw+resized_hat_w]
- bg_roi = img[y+dh-resized_hat_h:y+dh,(eyes_center[0]-resized_hat_w//3):(eyes_center[0]+resized_hat_w//3*2)]
- # 原图ROI中提取放帽子的区域
- bg_roi = bg_roi.astype(float)
- mask_inv = cv2.merge((mask_inv,mask_inv,mask_inv))
- alpha = mask_inv.astype(float)/255
- # 相乘之前保证两者大小一致(可能会由于四舍五入原因不一致)
- alpha = cv2.resize(alpha,(bg_roi.shape[1],bg_roi.shape[0]))
- # print("alpha size: ",alpha.shape)
- # print("bg_roi size: ",bg_roi.shape)
- bg = cv2.multiply(alpha, bg_roi)
- bg = bg.astype('uint8')
这是背景区域(bg),如下图所示,可以看到,刚好是需要填充帽子的区域缺失了。

然后我们提取帽子区域。
- # 提取帽子区域
- hat = cv2.bitwise_and(resized_hat,resized_hat,mask = mask)
提取得到的帽子区域如下图,帽子区域正好与上一个背景区域互补。

添加圣诞帽
***我们把两个区域相加,再放回到原图中去,就可以得到我们想要的圣诞帽图了。
这里需要注意的就是,相加之前 resize 一下保证两者大小一致,因为可能会由于四舍五入原因不一致。
- # 相加之前保证两者大小一致(可能会由于四舍五入原因不一致)
- hat = cv2.resize(hat,(bg_roi.shape[1],bg_roi.shape[0]))
- # 两个ROI区域相加
- add_hat = cv2.add(bg,hat)
- # cv2.imshow("add_hat",add_hat)
- # 把添加好帽子的区域放回原图
- img[y+dh-resized_hat_h:y+dh,(eyes_center[0]-resized_hat_w//3):(eyes_center[0]+resized_hat_w//3*2)] = add_hat
***我们得到的效果图如下所示: