近日,工信部印发《促进新一代人工智能产业发展三年行动计划(2018-2020年)》,意在加快人工智能从战略到落地,推动人工智能和实体经济深度融合。在新工业革命的背景下,大数据、计力、算法等快速迭代,正驱动人工智能进入新阶段。2017年Q3,全球AI公司融资金额突破77亿美元,是2012年的70余倍。可能会有人说这是“泡沫”,而我更愿意相信这是人工智能发展的必然结果。
在AI技术的应用过程中,各个企业都在寻找能够更好支撑高性能计算的基础网络解决方案。在《数据中心基础网络架构***实践及未来发展趋势》这篇文章中,我分享了如何设计一个稳定可靠的数据中心网络,下面我们再来探讨支撑AI应用的高性能无损网络应该如何设计。
前面提到大数据、计算力、算法等快速迭代,正驱动人工智能进入新阶段,而这些技术的实现对网络的低时延、无丢包、高性能这三个方面提出更高要求。
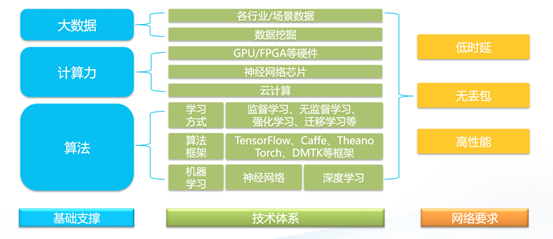
▲ AI应用的技术体系及对数据中心网络的要求
高性能和无丢包比较好理解,就是指网络带宽性能的提升以及网络中不存在拥塞导致的丢包。产生时延的环节较多,要实现端到端的低时延,需要多角度分析:

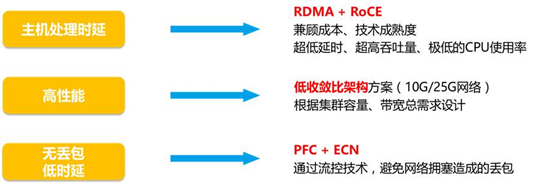
其中,光电传输时延和数据串行时延相对较小,且很难通过架构设计来优化,我们应重点关注主机处理时延和设备转发时延。在各大企业积极寻求的高性能计算方案中,基于以太网的RDMA(Remote Direct Memory Access)凭借其高性能和低成本优势逐渐取代InfiniBand而成为主流技术。RoCEv2(RDMA over Converged Ethernet)技术基于UDP协议,对于建设支撑AI应用的高性能无损以网络变得尤为重要。
结合设备转发层面的时延优化手段,高性能无损网络的实现取决于两个要素:
· 无带宽收敛(1:1)的网络架构设计
· 基于PFC(Priority-Based Flow Control)和ECN(explicit congestion notification)功能的优先队列管理和拥塞管理
综上,AI集群高性能计算和网络方案实践思路如下图所示:
▲ AI集群高性能方案关键技术组合
在这里,我以25G网络为例,结合业界主流产品形态,分享AI网络架构设计和实现思路。
主要设计理念:
l 核心设备全线速高性能转发,核心之间不互联,采用Fabric架构,隔离核心故障,***程度降低核心故障的影响;
l 三层路由组网,通过ECMP提高冗余度,降低故障风险;
l TOR上下行收敛比严格实现1:1,通过提高核心设备接口密度扩展单集群服务器规模;
l 应用PFC+ECN功能,实现低延时无损网络。
网络架构设计:
1.中小型(集群规模1000台)

▲ 架构设计
架构特性:
l 每台TOR采用8*100GE上联8台32口100G BOX交换机,OSPF/BGP组网
l 适用集群规模1000台
l 每台TOR下联32台Servers,IDC内收敛比1:1 ,集群带宽25Tbps
2.中型(集群规模2000台)

▲ 架构设计
架构特性:
l 每台TOR采用8*100GE上联8台64口100G BOX,OSPF/BGP组网
l 适用集群规模2000台
l 每台TOR下联32台Servers,IDC内收敛比1:1 ,集群带宽50Tbps
3.大型(集群规模2000-18000台)
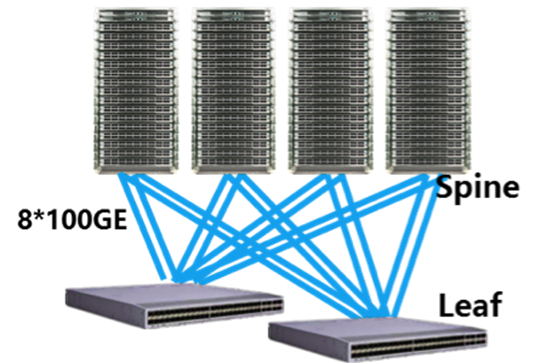
▲ 架构设计
架构特性:
l 每台TOR采用8*100GE上联4~8台核心(机框式),BGP组网
l 适用集群规模2000~18000台
l 每台TOR下联32台Servers,IDC内收敛比1:1 ,集群带宽50~450Tbps
4.超大型(集群规模20000+台)
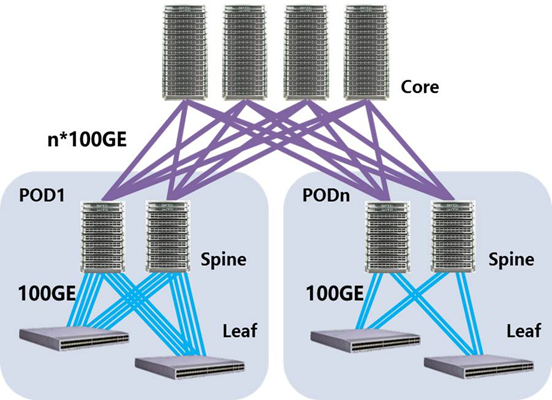
▲ 架构设计
架构特性:
l 单POD集群规模1000~2000台,数据中心集群规模20000+,BGP组网
l POD内收敛比1:1,单POD集群带宽25Tbps,总集群带宽500Tbps+
l POD内收敛比和上行带宽根据集群带宽需求灵活配置,适用与非AI应用混合部署
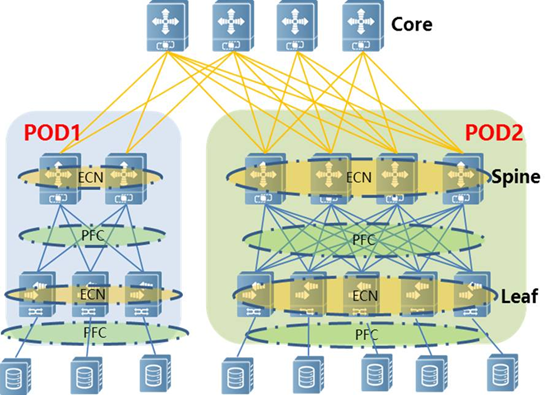
在数据中心网络中,PFC和ECN功能将部署在Leaf和Spine设备上。PFC作用于设备互联端口,通过反压影响上游端口队列的发送速率,而ECN是作用在设备转发过程,最终影响的是数据流的发送方,通过降低某条数据流发送速率规避数据丢包。
l PFC 机制将以太链路上的流量区分为不同的等级,基于每条流量单独发送“不许可证”。相对于PAUSE帧而言,PFC可以将链路虚拟出8条不同等级的虚拟通道,当某条通道出现拥塞后不会影响其它通道。
l RoCEv2 定义了 RoCEv2 Congestion Management ( RCM ),其中拥塞管理用的特性ECN(RFC 3168)是在交换机出口(egress port)发起的拥塞控制机制。当交换机的出口buffer达到设定的阈值时,交换机会改变数据包头中的ECN位来给数据打上ECN标签,当带ECN标签的数据到达接收端以后,接收端会生成CNP(Congestion Notification Packet)并将它发送给发送端。CNP包含了导致拥塞的flow或QP的信息,当发送端收到CNP后,会采取措施降低发送速度。
l 由于PFC作用于整个队列,而ECN只针对产生拥塞的具体会话,在设置PFC和ECN相关水线时,应做到先触发ECN
近日,工信部印发《促进新一代人工智能产业发展三年行动计划(2018-2020年)》,意在加快人工智能从战略到落地,推动人工智能和实体经济深度融合。在新工业革命的背景下,大数据、计力、算法等快速迭代,正驱动人工智能进入新阶段。2017年Q3,全球AI公司融资金额突破77亿美元,是2012年的70余倍。可能会有人说这是“泡沫”,而我更愿意相信这是人工智能发展的必然结果。
在AI技术的应用过程中,各个企业都在寻找能够更好支撑高性能计算的基础网络解决方案。在《数据中心基础网络架构***实践及未来发展趋势》这篇文章中,我分享了如何设计一个稳定可靠的数据中心网络,下面我们再来探讨支撑AI应用的高性能无损网络应该如何设计。
前面提到大数据、计算力、算法等快速迭代,正驱动人工智能进入新阶段,而这些技术的实现对网络的低时延、无丢包、高性能这三个方面提出更高要求。
▲ AI应用的技术体系及对数据中心网络的要求
高性能和无丢包比较好理解,就是指网络带宽性能的提升以及网络中不存在拥塞导致的丢包。产生时延的环节较多,要实现端到端的低时延,需要多角度分析:
其中,光电传输时延和数据串行时延相对较小,且很难通过架构设计来优化,我们应重点关注主机处理时延和设备转发时延。在各大企业积极寻求的高性能计算方案中,基于以太网的RDMA(Remote Direct Memory Access)凭借其高性能和低成本优势逐渐取代InfiniBand而成为主流技术。RoCEv2(RDMA over Converged Ethernet)技术基于UDP协议,对于建设支撑AI应用的高性能无损以网络变得尤为重要。
结合设备转发层面的时延优化手段,高性能无损网络的实现取决于两个要素:
· 无带宽收敛(1:1)的网络架构设计
· 基于PFC(Priority-Based Flow Control)和ECN(explicit congestion notification)功能的优先队列管理和拥塞管理
综上,AI集群高性能计算和网络方案实践思路如下图所示:
▲ AI集群高性能方案关键技术组合
在这里,我以25G网络为例,结合业界主流产品形态,分享AI网络架构设计和实现思路。
主要设计理念:
l 核心设备全线速高性能转发,核心之间不互联,采用Fabric架构,隔离核心故障,***程度降低核心故障的影响;
l 三层路由组网,通过ECMP提高冗余度,降低故障风险;
l TOR上下行收敛比严格实现1:1,通过提高核心设备接口密度扩展单集群服务器规模;
l 应用PFC+ECN功能,实现低延时无损网络。
网络架构设计:
1.中小型(集群规模1000台)
▲ 架构设计
架构特性:
l 每台TOR采用8*100GE上联8台32口100G BOX交换机,OSPF/BGP组网
l 适用集群规模1000台
l 每台TOR下联32台Servers,IDC内收敛比1:1 ,集群带宽25Tbps
2.中型(集群规模2000台)
▲ 架构设计
架构特性:
l 每台TOR采用8*100GE上联8台64口100G BOX,OSPF/BGP组网
l 适用集群规模2000台
l 每台TOR下联32台Servers,IDC内收敛比1:1 ,集群带宽50Tbps
3.大型(集群规模2000-18000台)
▲ 架构设计
架构特性:
l 每台TOR采用8*100GE上联4~8台核心(机框式),BGP组网
l 适用集群规模2000~18000台
l 每台TOR下联32台Servers,IDC内收敛比1:1 ,集群带宽50~450Tbps
4.超大型(集群规模20000+台)
▲ 架构设计
架构特性:
l 单POD集群规模1000~2000台,数据中心集群规模20000+,BGP组网
l POD内收敛比1:1,单POD集群带宽25Tbps,总集群带宽500Tbps+
l POD内收敛比和上行带宽根据集群带宽需求灵活配置,适用与非AI应用混合部署
在数据中心网络中,PFC和ECN功能将部署在Leaf和Spine设备上。PFC作用于设备互联端口,通过反压影响上游端口队列的发送速率,而ECN是作用在设备转发过程,最终影响的是数据流的发送方,通过降低某条数据流发送速率规避数据丢包。
l PFC 机制将以太链路上的流量区分为不同的等级,基于每条流量单独发送“不许可证”。相对于PAUSE帧而言,PFC可以将链路虚拟出8条不同等级的虚拟通道,当某条通道出现拥塞后不会影响其它通道。
l RoCEv2 定义了 RoCEv2 Congestion Management ( RCM ),其中拥塞管理用的特性ECN(RFC 3168)是在交换机出口(egress port)发起的拥塞控制机制。当交换机的出口buffer达到设定的阈值时,交换机会改变数据包头中的ECN位来给数据打上ECN标签,当带ECN标签的数据到达接收端以后,接收端会生成CNP(Congestion Notification Packet)并将它发送给发送端。CNP包含了导致拥塞的flow或QP的信息,当发送端收到CNP后,会采取措施降低发送速度。
l 由于PFC作用于整个队列,而ECN只针对产生拥塞的具体会话,在设置PFC和ECN相关水线时,应做到先触发ECN后再触发PFC。
从外卖订单和叫车订单的智能调度,到电商平台的智能推荐,再到人脸识别支付以及即将实现的全自动无人驾驶汽车量产,AI技术的应用已在方方面面影响着人们的生活和工作,让大家的生活越来越便捷、时间利用越来越合理。但是,这都离不开基础设施的支撑。锐捷网络将凭借在数据通信领域近20年的技术积累和行业经验,创新出更好的产品和解决方案,助力AI技术的蓬勃发展。
后再触发PFC。
从外卖订单和叫车订单的智能调度,到电商平台的智能推荐,再到人脸识别支付以及即将实现的全自动无人驾驶汽车量产,AI技术的应用已在方方面面影响着人们的生活和工作,让大家的生活越来越便捷、时间利用越来越合理。但是,这都离不开基础设施的支撑。锐捷网络将凭借在数据通信领域近20年的技术积累和行业经验,创新出更好的产品和解决方案,助力AI技术的蓬勃发展。