













一、什么是数据自服务
数据在企业中的处理过程,能清晰地映射出康威定律对IT系统的影响。在各个部门分别建设IT系统、组织内部大量存在信息筒仓(silo)的年代,数据的操作由OLTP应用系统的开发团队同步开发,那时几乎每个政府信息化、企业信息化系统都会有一块“报表需求”。随后众多组织认识到筒仓系统导致信息在组织内不能拉通,不能产生对整体业务流程的洞察,于是开始建设以数据仓库为代表的OLAP系统。
这些系统在支撑更高级、更复杂的数据分析的同时,也对应地在组织中造就了一支专业的“数据团队”。这些人使用非常专业的技术和工具对数据进行提取、转换、装载、建立数据立方、多维钻取、生成报表。这些专业的技术和工具,普通的软件开发人员并没有掌握,因此对数据处理、分析和呈现的变更都必须归集到这个数据团队来完成。结果是,数据团队的backlog里累积了来自各个部门的需求,需求的响应能力下降,IT系统从上线到获得市场洞察的周期变长。
微服务架构鼓励小型的、全功能的团队拥有一个完整的服务(及其对应的业务)。这样的全功能团队不光要开发和运维IT系统,还要能从数据中获得洞察——而且要快,不然就会跟不上市场变化,甚至使一些重要的业务场景无法得到支撑。因此他们不能坐等一支集中式的、缓慢的数据团队来响应他们的需求,他们需要数据自服务能力。 要赋能数据自服务,企业的数字化平台要考虑“两个披萨团队”的下列诉求:
- 需要定义数据流水线,使数据能够顺畅地流过收集、转换、存储、探索/预测、可视化等阶段,产生业务价值。
- 需要用实时的架构和API在短时间内处理大量、非结构化的数据,从中获得洞见,并实时影响决策。
- 为了提高应变能力,系统中的数据不做ETL预处理,而是以“生数据”的形式首先存入数据湖,等有了具体的问题要回答时,再去组织和筛选数据,从中找出答案。
- 更进一步把数据包装成能供外人使用的数据产品,让第三方从数据中获得新的洞见与价值。
- 为了支持数据产品的运营,需要实现细粒度授权,针对不同的用户身份,授权访问不同范围的数据。
二、数据自服务解读
下面是ThoughtWorks的数字平台战略第三个支柱“数据自服务”中所蕴涵的具体内容。

1. 数据流水线设计
所谓流水线,是指用大数据创造价值的整个数据流。流水线从数据采集开始,随后是数据的清洗或过滤,再然后是将数据结构化到存储仓库中以便访问和查询,这之后就可以通过探索或预测的方式从数据中找到业务问题的答案,并可视化呈现出来。

一条运转良好的数据流水线,能有效处理移动/物联网等新技术制造出的极其大量的数据,缩短数据从获取到产生洞见的反馈周期,并以开发者友好的方式完成数据各个环节的处理,赋能一体化团队。
数据流水线的实现有两种可能的方式。一种方式是在各个环节采用各种特定的工具,例如前面介绍的数据流水线,各个环节都可以用开源的工具来实现。当然,选择这种方式也并非没有挑战:组织必须自己编写和维护“胶水代码”,把各种专用工具组合成一个内聚的整体。对组织的技术能力有较高的要求。
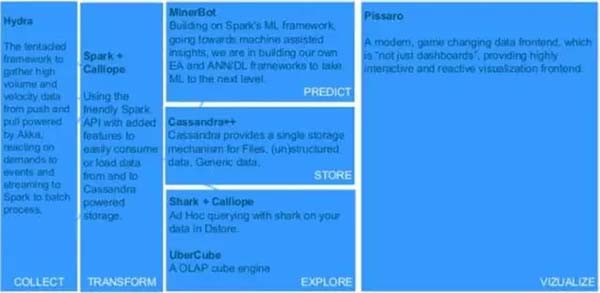
除了基于开源软件实现自己的数据流水线,也可以考虑采用云上的数据流水线PaaS服务,例如Databricks、AWS Data Pipeline、Azure Data Factory等。这个方式的优点是对技术能力要求较低,缺点则是造成对特定云平台/PaaS提供商的依赖。
2. 实时架构和API
实时的数据架构和API支持短时间内处理大量、非结构化的数据,从中获得洞见,并“实时”影响决策。正如Mike Barlow所说:“这是关于在正确时间做出更好决定并采取行动的能力,例如在顾客刷卡的时候识别信用卡欺诈,或者当顾客在排队结账的时候给个优惠,或者当用户在阅读某篇文章的时候推送某个广告。”
在Cloudera的一篇文章中介绍了实时数据处理的4个架构模式,整个流水线架构在Flume/Kafka基础上:
- 数据流吸收:低延迟将事件持久化到HDFS、HBase、Solr等存储机制
- 近实时(100毫秒以下)的事件处理:数据到达时立即采取警告、标记、转换、过滤等初步行动
- 近实时的事件分片处理:与前一个模式类似,但是先对数据分片
- 复杂而灵活的聚合或机器学习拓扑,使用Spark
3. 数据湖设计
数据湖概念最初提出是在2014年Forbes的一篇文章中。它的概念是:不对数据做提前的“优化”处理,而是直接把生数据存储在容易获得的、便宜的存储环境中;等有了具体的问题要回答时,再去组织和筛选数据,从中找出答案。按照ThoughtWorks技术雷达的定义,数据湖中的数据应该是不可修改(immutable)的。
数据湖试图解决数据仓库几方面的问题:
- 预先的ETL处理终归会损失信息,如果事后才发现需要生数据中的某些信息、但是这些信息又没有通过ETL进入数据仓库,那么信息就无法寻回了。
- ETL的编写相当麻烦。数据仓库的schema发生改变,ETL也要跟着改变;应用程序的schema发生改变,ETL也要跟着改变。因此数据仓库通常由一个单独的团队负责,于是形成一个功能团队,响应速度慢。
- 数据仓库的分析需要专门的技能,大部分应用程序开发者不掌握,再度强化了数据仓库专门团队;而数据仓库团队其实离业务很远,并不能快速准确地响应业务对数据分析的需求。
在数据湖概念背后是康威法则的体现:数据能力与业务需求对齐。它要解决的核心问题是专门的数据仓库团队成为响应力瓶颈。当IT能力与业务需求组合形成一体化团队以后,数据的产生方不再假设未来要解决什么问题,因此也不对数据做预处理,只是直接存储生数据;数据的使用方以通用编程语言(例如Java或Python)来操作数据,从而无需依赖专门的、集中式的数据团队。
数据湖实施的***步是把生数据存储在廉价的存储介质(可能是HDFS,也可能是S3,或者FTP等)。对于每份生数据,应该有一份元数据描述其来源、用途、和哪些数据相关等等。元数据允许整个组织查看和搜索,让每个一体化团队能够自助式寻找自己需要的数据。任何团队都可以在生数据的基础上开发自己的微服务,微服务处理之后的数据可以作为另一份生数据回到数据湖。维护数据湖的团队只做很少的基础设施工作,生数据的输入和使用都由与业务强关联的开发团队来进行。传统数据仓库的多维分析、报表等功能同样可以作为一个服务接入数据湖。
在实施数据湖的时候,有一种常见的反模式:企业有了一个名义上的数据湖(例如一个非常大的HDFS),但是数据只进不出,成了“数据泥沼”(或数据墓地)。在这种情况下,尽管数据湖的存储做得很棒,但是组织并没有很好地消化这些数据(可能是因为数据科学家不具备分析生数据的技术能力,而是更习惯于传统的、基于数据仓库的分析方式),从而不能很好地兑现数据湖的价值。
4. 数据即产品
数据产品是指将企业已经拥有或能够采集的数据资产,转变成能帮助用户解决具体问题的产品。Forbes列举了几类值得关注的数据产品:
- 用于benchmark的数据
- 用于推荐系统的数据
- 用于预测的数据
数据产品是数据资产变现的快速途径。因为数据产品有几个优势:开发快,不需要开发出完整的模型,只要做好数据整理就可以对外提供;顾客面宽,一份数据可以产生多种用途;数据可以再度加工。数据产品给企业创造的收益既可以是直接的(用户想要访问数据或分析时收费)也可以是间接的(提升顾客忠诚度、节省成本、或增加渠道转化率)。
在实现数据产品的时候,不仅要把数据打包,更重要的是提供数据之间的关联。数据产品的供应者需要提出洞见、指导用户做决策,而不仅仅是提供数据点。数据产品需要考虑用户的场景和体验,并在使用过程中不断演进。
5. 细粒度授权
当数据以产品或服务的形式对外提供,企业可能需要针对不同的用户身份,授权访问不同范围的数据,对应不同的服务水平和不同的安全级别。
一些典型的细粒度授权的场景可能包括:
- 企业内部和外部用户能够访问的数据范围不同;
- 供应链上不同环节的合作伙伴能够访问的数据范围不同;
- 付费与免费的用户能够访问的数据范围不同;
- 不同会员级别能够访问的数据范围不同等等。
允许访问的数据范围属于数据产品/服务自身的业务规则。《微服务设计》的第9章建议,“[服务]网关可以提供相当有效的粗粒度的身份验证……不过,比允许(或禁止)的特定资源或端点更细粒度的访问控制,可以留给微服务本身来处理”。
三、小结
为了加速“构建-度量-学习”的精益创业循环,业务与IT共同组成的一体化团队不能依赖于集中式的数据团队来获得对业务的洞察。他们需要规划适宜自己的数据流水线,在必要时引入实时数据架构和API,用数据湖来支撑自服务的数据操作,从而更快、更准确地从数据中获得洞察,影响业务决策。更进一步,数据本身也可以作为产品对内部用户乃至外部用户提供服务,并通过细粒度授权体现服务的差异化和安全性需求。通过建设“数据自服务”这个支柱,企业将真正能够盘活数据资产,使其在创新的数字化业务中发挥更大的价值,这是企业数字化旅程的第三步。
【本文是51CTO专栏作者“ThoughtWorks”的原创稿件,微信公众号:思特沃克,转载请联系原作者】





















