社交网络一路走来,先是文字 +表情,接着是图片 +短视频,现在是音视频社交强势崛起并成为潮流的时代。音视频社交将是社交网络的发展趋势,毕竟音视频才是人类最自然的社交方式。在自然的社交环境中,回声是十分影响沟通体验的。而回声消除一直是音视频技术的难点。
游戏语音就是音视频社交在游戏领域的一个典型的应用。如果你不希望讨厌戴耳机的用户放弃你的游戏,那么在游戏实时语音中实现回声消除是必须的。
无论是竞技类还是休闲类的游戏,游戏实时语音都成了标配。竞技类的游戏,包括 MMORPG、MOBA、和 FPS,需要快节奏和高频率的团队协同,游戏语音就像战时通讯装备一样必不可少。休闲类的游戏,包括棋牌和狼人杀,需要慢节奏但是零距离的在线社交,玩家在通过游戏建立的社交纽带中进行多人实时聊天,游戏实时语音让玩家们像坐在同一个房间玩牌一样。
在业界,回声消除技术是公认难啃的硬骨头。它本质上是一个复杂的数学问题的工程化。音频工程师往往是数学或者物理专业而不是计算机专业出身的,没有过相关经验的工程师根本就无从下手。回声消除技术做得比较好的产品有 TencentQQ和MicrosoftSkype,开源的项目有WebRTC和Speex。在这些开源项目之前,回声消除技术是大厂的独门武艺,其它团队只能靠自己一点一滴地摸索积累。在这些开源项目之后,WebRTC和Speex提供开源的AEC模块,成为业界不错的教材。
AEC的原理
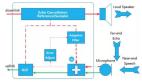
回声消除的原理很多文章介绍过,这里只简单介绍笔者在工作中的实践。简单地来说,远端的声音信号首先通过扬声器播放出来,然后在房间中经过多个传播和反射路径,最后和近端的声音一起被麦克风采集进去。如果没有做回声消除处理,那么远端就会把重新采集进去的远端声音信号播放出来,而且和原始的远端声音有一定的延迟时间。这就是回声产生的原理。
要消除回声,其实真的很难。这有点像把红墨水倒进蓝墨水里,混合在一起,然后要求把红墨水从蓝墨水中分离出来。对于采集端来说,无论是近端的声音,还是扬声器播放出来的声音,都是从空气中无差别地采集到的声音。对机器来说,远端信号播放出来的声音和近端的声音是没有任何区别的,就像对水来说红墨水和蓝墨水没有区别一样。回声消除的工作就是要把没有任何区别的远端回声和近端声音分离。这项工作其实比想象中要难得多。
幸运的是,我们并非没有任何办法可以找到远端回声和近端声音的边界。
远端的声音信号和回声是相关的。也许有朋友会一拍脑袋焕然大悟地说:那就直接把远端声音从采集到的声音中减掉就可以了。然而事情并没有那么简单。
远端的声音信号并非等同于回声。远端的声音从扬声器播放出来,到被采集端采集,经历过扬声器 -房间 -麦克风(Loudspeaker-Room-Microphone,LRM)这样的回声馈路。在 LRM回声馈路中传播的时候,远端声音一方面经过多次反射,另外一方面经过多次叠加,最后变得和远端声音信号有差别了。我们把这个差别用一个函数来表示:
- ffe=f(fs)
其中,
- fs=far-end signal(远端信号);
- fe=far-end echo (远端回声)
如果能够对这个函数求解,那么就可以根据远端声音信号和远端回声之间的相关性进行建模。这个模型是对回声馈路 LRM的模拟,会高度逼近回声馈路 LRM。
等到这个模型稳定时,输入远端声音信号 fs,就可以输出高度接近远端回声的信号 fe。通过滤波器生成反相的信号,和采集到的声音信号进行叠加,就可以把回声信号消除掉。这就是回声消除 AEC的基本原理。
这个函数求出来的解不大可能和远端回声完全一致,只能高度逼近。该函数求出来的解和远端回声越逼近,回声消除的效果就越好。
静音、单讲和双讲
虽然实时语音的通话是双工模式,但是可以分为不同的情形:静音、单讲和双讲。针对不同的情形要采取不同的回声消除策略。
1. 静音
即没有人说话的情形。
在语音段才需要做回声消除,在非语音段不会有回声,不需要做回声消除,甚至不需要发送语音信息,从而可以降低码率,节约带宽成本。
因此,准确探测语音活动十分重要。语音的探测算法叫 VAD(Voice Activity Detection)。不同的厂商有不同的 VAD实现方法。我们是利用基音周期实现 VAD,有效地提高 VAD判断的准确性,避免将非语音段误判为语音段。
2. 单讲
即只有远端说话的情形。
由于只有远端说话,从麦克风采集进来的语音信号只包含远端的回声,而不包含近端的语音。单讲情形下的回声消除相对比较容易处理,可以采取比较激进的处理策略。
如果确定单讲是高概率事件的情况下,可以直接地把所有语音信号都干掉,然后适当地填充舒适噪音。一般来说,在单讲情形下,用线性自适应滤波器跟踪回声馈路,可以很好地消除回声,大概能够抑制掉 18dB的回声。
3. 双讲
有多方同时说话的情形。
由于有多方同时说话,从麦克风采集进来的语音信号就包含了远端的回声和近端的语音,两者混合在一起。双讲情形下的回声消除就十分困难:一方面要保护近端的语音信号不被损伤,另外一方面还要尽量地把回声消除干净。
这里不但有“红墨水蓝墨水分离”的难题,而且还有“投鼠忌器”的困境。一般来说,在远端回声比近端语音要高大概 6dB~8dB的情况下,如果要把远端回声消除干净,那么肯定会或多或少地损伤到近端语音。
另外,如果远端回声比近端语音要高出 18dB以上,比如说扬声器离麦克风太近,远端回声把近端语音完全掩盖掉了,那么回声消除的效果肯定是不好的。这种情形下,可以采取比较激进的策略,把远端回声和近端语音一起干掉,然后适当地填充舒适噪音。
因此,回声消除模块要有能力区分这三种情形,才能针对各种情形采取不同的算法。通过 VAD可以区分非语音段和语音段。如何区分单讲和双讲的方法将在下面讨论。
AEC的实现
回声消除主要包含两个步骤:线性自适应滤波和非线性处理。
线性自适应滤波就是对 fe=f(fs)求解,建立远端回声的语音模型,进行第一轮回声消除。
非线性处理又分为两个步骤:残留回声处理和非线性剪切处理。残留回声处理进行第二轮回声消除,处理残留回声;非线性剪切处理就是对衰减量达到阈值的语音信号进行比较激进的剪切处理。
线性自适应滤波和非线性剪切处理在学术论文和开源项目中能找到东西学习。残留回声处理就很难,一般都是要靠团队自行摸索、积累和创新。正是因为如此,语音技术的门槛才如此的高。

回声消除的原理与实现线性自适应滤波
以远端声音信号和远端回声的相关性为基础,建立远端回声的语音模型,利用它对远端回声进行估计,目的是获得对远端回声尽量逼近的估计。我们可以把回声馈路 LRM看作一个“环境滤波器”。
经过它的处理,远端声音信号被变成远端回声。回声消除就是要构建一个“算法滤波器”,基于对远端回声的语音模型,不断地调整该滤波器的系数,使得估计值更加逼近真实的回声。估计值越逼近真实回声,回声消除效果就越好。
自适应滤波器收敛后得到的就是需要求解的回声馈路函数fe=f(fs)。当滤波器收敛稳定之后,输入远端声音信号 fs,就可以输出相对准确的对远端回声信号的估计值 fe。把采集到的信号减去远端回声信号的估计值 fe,就得到实际要发送的语音信号。
实现线性自适应滤波器有两个难点
1. 快速收敛
在收敛阶段,采集到声音信号要求只有远端的回声信号,不能混有近端的语音信号。近端的语音信号和远端的参考语音信号没有相关性,会对自适应滤波器的收敛过程造成扰乱。
因此,我们的策略是让自适应滤波器收敛的时间尽量地短,短到收敛过程的时间段里采集进来的信号只有远端的回声信号,这样自适应滤波器收敛的效果就会很好。在收敛好之后,滤波器就稳定下来了,就可以用来过滤远端的回声信号了。
2. 动态自适应
在收敛好稳定下来以后,自适应滤波器还要随时自动适应回声馈路的变化。自适应滤波器要能够判断回声馈路是否发生变化,并且能够重新学习和对其进行建模,不断地调整该滤波器的系数,进入一个新的收敛过程,最后快速地逼近新的回声馈路。
这种情况在手游的场景中是十分常见的,用户拿着手机边走边玩游戏,游戏语音周遭的回声馈路时刻发生着变化,自适应滤波器就要时刻自动重新收敛来适应新的回声馈路。
这两个难点是一对矛盾的特征,要求自适应滤波器一方面要能够快速收敛后保持系数高度稳定,另外一方面要能够随时保持更新状态跟踪回声馈路的变化。
非线性处理
1. 残留回声处理
通过自适应滤波器来消除回声,并不能百分之一百把回声消除干净,还需要进一步消除残留的回声。
一般来说,残留回声消除的策略是利用自适应滤波器处理后的残留回声与远端参考语音信号的相关性,进一步消除残留回声。相关性越大,说明残留回声越多,需要对残留回声进一步消除的程度越大;反之,相关性越小,说明残留回声较少,需要对残留回声进一步消除的程度越小。
因此,首先要通过计算残留回声与参考信号的相关矩阵,得到一个反映消除程度的衰减因子;然后将残留回声乘以衰减因子,从而进一步消除残留回声。
在线性自适应滤波做完了以后,可以利用残留回声和麦克风采集到的远端回声信号的相关性来检测是处于单讲还是双讲状态。根据单讲还是双讲状态,可以进一步调整衰减因子。
如果处于远端单讲状态,因为近端没有声音信号(没人说话),可以尽量多地抑制回声,让衰减因子尽量地小;如果处于双讲状态,因为线性自适应滤波器是在尽量不损伤近端语音音质的前提下消除回声,回声抑制量不会太大,所以衰减因子相对较大。
消除残留回声的算法难度甚高。在论文或者开源项目中甚少有可参考的东西,各家厂商都是通过私有的算法来实现的,甚至很多厂商都选择不实现。
2. 非线性剪切处理
在完成了上述处理以后,其实剩下的回声一般都比较小了,但不排除仍有一些残留的可以感知的小回声。为了进一步消除这些小回声,要根据前面处理得到的衰减量来做进一步的抑制处理。
在这里要为衰减量设定一个阈值。一般来说,这个衰减量阈值要设定得比较保守(比较高)。
如果衰减量达到或者超过设定的阈值,就表明回声消除量比较大,采集进来的语音信号很可能全部都是回声信号,那么就直接将语音信号全部消除掉,并填充舒适噪声,防止声音听感起伏。能达到那么大的衰减量,一般是处于远端单讲状态,或者远端回声信号要远远大于近端语音信号的双讲状态。
正常的双讲状态下,为了保护近端语音的音质,自适应滤波器是不会做大幅的回声消除的。因此,只要衰减量达到或者超过设定阈值,把采集到的语音信号全部消除掉是不会影响正常听音效果的。
如果衰减量没有超过设定的阈值,那么就不要进一步做回声消除了。这种情形可能是双讲状态,要保护本地语音的音质,避免本地语音被当成回声误杀。
业界一般有两种做法:一种是允许对近端声音有些许损伤也要把远端回声消除干净,另外一种是允许保留些许远端回声也不要对近端声音造成损伤。如果过分消除回声,就会造成断续的听音感觉。回声消除就是要在这两种做法之间找平衡点。
笔者在工作中的实践表明,在音视频社交行业,回声消除是客户高度关注的一个技术特征。与此同时,回声消除也是音视频社交中最有难度的技术,没有之一。即使是王者荣耀这种顶级的游戏,也十分重视回声消除的效果。在以用户体验为生命线的游戏行业,特别在手游做得越来越重的今天,回声消除技术做得好不好,往往决定了用户是否继续玩你的游戏。
作者简介:冼牛,即构科技资深语音视频专家,北京邮电大学计算机硕士,香港大学工商管理硕士,多年从事语音视频云服务技术研究,专注互动直播技术、语音视频社交和实时游戏语音。
【本文为51CTO专栏作者“冼牛”原创稿件,转载请联系原作者(微信号:xianniu1216)】