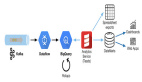
虽然现在最火的是AI,但是大数据和计算能力仍然是机器学习/AI算法的重要支撑,我们的业务场景大部分是通过手机终端、服务器日志不断产生日志数据,通过消息通道发送到大数据平台进行存储、加工和统计,然后在统计数据之上提供算法挖掘用户偏好行为和画像,为此,我们的关键任务是需要从海量数据里统计分析每项产品的去重用户、新增用户、pv、uv、dau(日活)、mau(月活)等指标,这个过程存储占用越少,计算时间越快越好。Fourinone(CoolHash)拥有原创数据库引擎设计能力和知识产权,能够在引擎层面灵活扩充各种功能支持,为了提供大数据统计计算的***解决方案,4.17在引擎上增强了以下特性:
一、增加了自加和存在新增两个原子操作
1. Object putPlus(String key, T plusValue)
如果key对应的value是数字类型(int、long、double、float),自增加plusValue(数字类型),如plusValue=1,表示每次自增1,plusValue也可以是小数。如果key对应的value是字符串类型,自增加plusValue(字符串),会累加到原字符串后面,可以用分隔符隔开。putPlus的返回值为该key的上一个值。
2. Object putNx(String key, T value)
如果key存在,则不操作,如不存在写入value。putNx返回值为key操作前值,为null表示不存在,否则返回已有值。
利用putPlus和putNx可以完成很多原子操作,如count类计数统计,在开源包指南附带的CountDemo.java里的countTest方法演示了putPlus的使用,在ThreadClient.java的putPlusTest方法和putNxTest方法演示了多线程下的使用。
pvTest方法演示了计算pv,如果id不存在则写入,并将pv数自加1,其他线程发现id存在,则无法更新pv数
- Object nx = chc.putNx("v0_"+i, i);
- if(nx==null)
- chc.putPlus("pv_v0",1);
二、增加了客户端本地和存储引擎端强大的bitmap支持
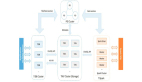
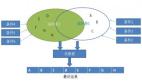
上面通过putPlus和putNx原子操作可以计算pv,但并不是***效的方案,使用bitmap有两个非常显著的优势:位存储占用空间低,位计算效率高。将需要做统计计算的id转换成数字序号,每个只占1个bit,对于20亿的用户id,只需要20亿bit约238m大小,压缩后占用空间更小,最少只要200k;通过单个bitmap可以完成去重操作,通过多个bitmap的且、或、异或、反等位操作可以完成日活、月活、小时分钟活跃、重度用户、新增用户、用户流向等绝大部分的统计计算,而且能在单机毫秒级完成,真正做到实时计算出结果,同比hadoop/hive离线计算执行“select distinct count…from…groupby join…”类似sql的方式统计,往往需要几百台机器,耗用30分钟才能完成,对比非常悬殊,而且容易形成大量sql任务调度和大表join给集群带来繁重压力。(图)

- 去重用户:求1的总数
- 活跃用户:取或bitmap1 | bitmap2
- 非活跃用户:取反:~bitmap1
- 重度用户:取且:Bitmap1 & bitmap2
- 新增用户:取或加异或:(Bitmap1 | bitmap2)^bitmap1
- 多种指标组合:Bitmap1 & bitmap2 & bitmap3 &…
- 等等
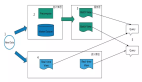
同时提供bitmap本地和引擎端互通实现,能够进行更灵活的架构设计,可以将bitmap压缩存储到任何数据库上,客户端拉回后完成聚合计算,计算完成的结果再写回数据库。也可以多个客户端同时连接到CoolHash存储引擎上,通过引擎的bitmap操作支持完成去重、聚合、解压缩等支持。BitMap结合存储引擎如下图:

1. 本地内存实现,CoolBitSet实现了以下bitmap功能:
CoolBitSet(int maxSize),可指定大小限制,默认1000万大小,本地没有***限制,可以使用多个分区的bitmap表示整型范围或长整型范围的数据,每个1000万的bitmap压缩后在2m以内,很适合放入kv存储。
(1)基本操作:CoolBitSet提供基本的get(int n)、set(int n)、put(int n)操作,其中put为存在返回get,不存在set,除外还提供批量操作:int set(CoolBitSet cbs): 将另外一个bitmap对象合并到当前bitmap,并返回新增的数量。
(2)聚合操作:求且、求或、异或、求反、求新增
- CoolBitSet and(CoolBitSet cbs):两个CoolBitSet求且,更新到当前对象,并返回该对象引用
- CoolBitSet or(CoolBitSet cbs):两个CoolBitSet求或,同上
- CoolBitSet xor(CoolBitSet cbs):两个CoolBitSet求异或,同上
- CoolBitSet andnot():将该CoolBitSet对象求反,同上
- CoolBitSet setNew(CoolBitSet cbs):求当前CoolBitSet的新增用户,并返回新增用户结果的对象引用
(3)求总数:int getTotal()返回该CoolBitSet的用户总数,bit位是1的总数量
(4)求容量:int getSize()返回该CoolBitSet的容量大小
(5)调试查看:String toString(int num)返回该CoolBitSet的二进制字符串,为了减少长度,参数num为需要查看的byte数,如num=5表示查看前5个byte的二进制串
和java的bitmap的实现区别:jdk自带的BitSet类是以long数组实现,而且只能初始化大小,无法限制大小,每个bitset要耗用几百m的内存,多个bitmap容易造成空间大量浪费,BitSet类只是本地内存实现,没有分布式存储引擎持久化支持。
2. 引擎端持久化实现,CoolHashClient提供了以下接口用来操作存储引擎:
(1)int putBitSet(String key, int index):
- 单项操作,类似CoolBitSet的put,***个参数为bitmap的key,第二个参数将该bitmap的index位置设为1。
(2)boolean getBitSet(String key, int index):
- 单项操作,类似CoolBitSet的get,***个参数为bitmap的key,第二个参数需要获取的index位置的值。
(3)int putBitSet(String key, CoolBitSet cbs):
- 批量操作,类似CoolBitSet的批量set,将另外一个bitmap对象合并到指定key的bitmap,并返回新增的数量。获取CoolBitSet对象仍然使用get接口Object get(String key)
(4)Object putBitSet(String key, CoolBitSet cbs, String logical):
- 聚合操作,参数logical可以设置为“and”,“or”,“xor”,“andnot”,”new”之一,对于“andnot”,参数cbs并不起作用,可以传入任意不为空的CoolBitSet对象。聚合操作会作用到该key指定的bitmap上,返回值为聚合后的CoolBitSet对象。
以上操作遵循CoolHash的k/v存储约束,k为字符串,v不超过2m(可修改默认配置大小)。
注意CoolBitSet对象可以用三种方式进行k/v存储和压缩:
- 存储为bitSet格式,合并数据:putBitSet(String key, CoolBitSet cbs)
- 存储为bitSet格式,直接覆盖:put(String key, CoolBitSet cbs)
- 普通kv存储格式,非bitSet格式:put(String key, cbs.getBytes());
由于是对象存储,三种put方式都会对value数据进行压缩,采用压缩率和耗时比较平衡的gzip压缩。
前两种bitSet格式存储方式,会验证CoolBitSet大小不能超过1亿,否则不能提交。
第三种普通kv存储格式,没有1亿的限制,只要压缩后大小不超过2m,可以正常提交,但由于不是CoolBitSet格式,存储引擎无法识别做聚合等操作。
和redis的bitmap的实现区别:redis实现了bitmap的单项操作和聚合操作,但是没有批量操作,也没有压缩,通过offset指定偏移量的方式分配空间容易造成浪费。
开源包指南附带CountDemo.java里的演示:
bitSetTest方法:先演示了全量存储,写入10亿数据到1个bitmap,耗时不到1秒;再演示了分区存储,将1亿大小的数据分成10个1000万大小的bitmap存储。
realtimeStatistics方法:演示基于bitmap做用户去重、活跃用户、非活跃用户、重度用户、新增用户等实时计算。
retainLocal方法和retainServer方法:
分别演示了如何使用本地内存和存储引擎计算用户留存。
3. 增加String类型的bitmap支持:
StringBitMap实现了String类型的bitMap,通过对hash算法的改进,能够做到1亿字符串数据只有200多的碰撞率,5000万内数据几乎没有碰撞率,对于不超过1亿的数据是很合适的,但1亿以上的字符串数量仍然不合适,碰撞率会大幅上升。开源包指南附带CountDemo.java里的stringBitMapTest方法演示了模拟1000万随机生成的15位IMEI设备号,并返回碰撞个数。
4. 17.10版本同时提供jdk1.8.0_151编译下”fourinone.jar”包和jdk1.7.0_80编译下”fourinone-jdk7.jar”包。4.17.10版本更新github code和gitee code,本版本所有开源内容已经进行了公司报备,感谢对开源的支持。