













LevelDB是Google传奇工程师Jeff Dean和Sanjay Ghemawat开源的KV存储引擎,无论从设计还是代码上都可以用精致优雅来形容,非常值得细细品味。本文将从设计思路、整体结构、读写流程、压缩流程几个方面来进行介绍,从而能够对LevelDB有一个整体的感知。
设计思路
LevelDB的数据是存储在磁盘上的,采用LSM-Tree的结构实现。LSM-Tree将磁盘的随机写转化为顺序写,从而大大提高了写速度。为了做到这一点LSM-Tree的思路是将索引树结构拆成一大一小两颗树,较小的一个常驻内存,较大的一个持久化到磁盘,他们共同维护一个有序的key空间。写入操作会首先操作内存中的树,随着内存中树的不断变大,会触发与磁盘中树的归并操作,而归并操作本身仅有顺序写。如下图所示:
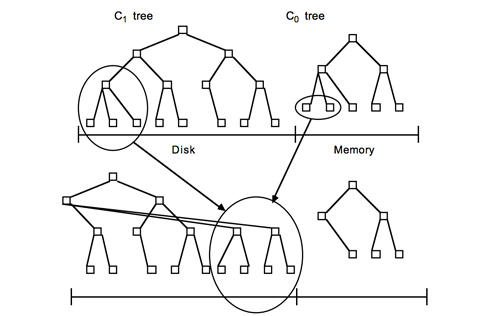
LSM示意
随着数据的不断写入,磁盘中的树会不断膨胀,为了避免每次参与归并操作的数据量过大,以及优化读操作的考虑,LevelDB将磁盘中的数据又拆分成多层,每一层的数据达到一定容量后会触发向下一层的归并操作,每一层的数据量比其上一层成倍增长。这也就是LevelDB的名称来源。
整体结构
具体到代码实现上,LevelDB有几个重要的角色,包括对应于上文提到的内存数据的Memtable,分层数据存储的SST文件,版本控制的Manifest、Current文件,以及写Memtable前的WAL。这里简单介绍各个组件的作用和在整个结构中的位置。
- Memtable:内存数据结构,跳表实现,新的数据会首先写入这里;
- Log文件:写Memtable前会先写Log文件,Log通过append的方式顺序写入。Log的存在使得机器宕机导致的内存数据丢失得以恢复;
- Immutable Memtable:达到Memtable设置的容量上限后,Memtable会变为Immutable为之后向SST文件的归并做准备,顾名思义,Immutable Mumtable不再接受用户写入,同时会有新的Memtable生成;
- SST文件:磁盘数据存储文件。分为Level 0到Level N多层,每一层包含多个SST文件;单个SST文件容量随层次增加成倍增长;文件内数据有序;其中Level0的SST文件由Immutable直接Dump产生,其他Level的SST文件由其上一层的文件和本层文件归并产生;SST文件在归并过程中顺序写生成,生成后仅可能在之后的归并中被删除,而不会有任何的修改操作。
- Manifest文件: Manifest文件中记录SST文件在不同Level的分布,单个SST文件的***最小key,以及其他一些LevelDB需要的元信息。
- Current文件: 从上面的介绍可以看出,LevelDB启动时的首要任务就是找到当前的Manifest,而Manifest可能有多个。Current文件简单的记录了当前Manifest的文件名,从而让这个过程变得非常简单。

LevelDB 结构
读写操作
作为KV数据存储引擎,基本的读写操作是必不可少的,通过对读写操作流程的了解,也能让我们更直观的窥探其内部实现。
1,写流程
LevelDB的写操作包括设置key-value和删除key两种。需要指出的是这两种情况在LevelDB的处理上是一致的,删除操作其实是向LevelDB插入一条标识为删除的数据。下面就一起看看LevelDB插入值的过程。
LevelDB对外暴露的写接口包括Put,Delete和Write,其中Write需要WriteBatch作为参数,而Put和Delete首先就是将当前的操作封装到一个WriteBatch对象,并调用Write接口。这里的WriteBatch是一批写操作的集合,其存在的意义在于提高写入效率,并提供Batch内所有写入的原子性。
在Write函数中会首先用当前的WriteBatch封装一个Writer,代表一个完整的写入请求。LevelDB加锁保证同一时刻只能有一个Writer工作。其他Writer挂起等待,直到前一个Writer执行完毕后唤醒。单个Writer执行过程如下:
- Status status = MakeRoomForWrite(my_batch == NULL);
- uint64_t last_sequence = versions_->LastSequence();
- Writer* last_writer = &w;
- if (status.ok() && my_batch != NULL) {
- WriteBatch* updates = BuildBatchGroup(&last_writer);
- WriteBatchInternal::SetSequence(updates, last_sequence + 1);
- last_sequence += WriteBatchInternal::Count(updates);
- // 将当前的WriteBatch内容写入Binlog以及Memtable
- ......
- versions_->SetLastSequence(last_sequence);
- }
- 在MakeRoomForWrite中为当前的写入准备Memtable空间:Level0层有过多的文件时,会延缓或挂起当前写操作;Memtable已经写满则尝试切换到Immutable Memtable,生成新的Memtable供写入,并触发后台的Immutable Memtable向Level0 SST文件的Dump。Immutable Memtable Dump不及时也会挂起当前写操作。
- BuildBatchGroup中会尝试将当前等待的所有其他Writer中的写入合并到当前的WriteBatch中,以提高写入效率。
- 之后将WriteBatch中内容写入Binlog并循环写入Memtable。
- 关注上述代码的***一行,在所有的值写入完成后才将Sequence真正更新,而LevelDB的读请求又是基于Sequence的。这样就保证了在WriteBatch写入过程中,不会被读请求部分看到,从而提供了原子性。
2,读流程
- 首先,生成内部查询所用的Key,该Key是由用户请求的UserKey拼接上Sequence生成的。其中Sequence可以用户提供或使用当前***的Sequence,LevelDB可以保证仅查询在这个Sequence之前的写入。
- 用生成的Key,依次尝试从 Memtable,Immtable以及SST文件中读取,直到找到。
- 从SST文件中查找需要依次尝试在每一层中读取,得益于Manifest中记录的每个文件的key区间,我们可以很方便的知道某个key是否在文件中。Level0的文件由于直接由Immutable Dump 产生,不可避免的会相互重叠,所以需要对每个文件依次查找。对于其他层次,由于归并过程保证了其互相不重叠且有序,二分查找的方式提供了更好的查询效率。
- 可以看出同一个Key出现在上层的操作会屏蔽下层的。也因此删除Key时只需要在Memtable压入一条标记为删除的条目即可。被其屏蔽的所有条目会在之后的归并过程中清除。
压缩操作
数据压缩是LevelDB中重要的部分,即上文提到的归并。冷数据会随着Compaction不断的下移,同时过期的数据也会在合并过程中被删除。LevelDB的压缩操作由单独的后台线程负责。这里的Compaction包括两个部分,Memtable向Level0 SST文件的Compaction,以及SST文件向下层的Compaction,对应于两个比较重要的函数:
1,CompactMemTable
CompactMemTable会将Immutable中的数据整体Dump为Level 0的一个文件,这个过程会在Immutable Memtable存在时被Compaction后台线程调度。过程比较简单,首先会获得一个Immutable的Iterator用来遍历其中的所有内容,创建一个新的Level 0 SST文件,并将Iterator读出的内容依次顺序写入该文件。之后更新元信息并删除Immutable Memtable。
2,BackgroundCompaction
SST文件的Compaction可以由用户通过接口手动发起,也可以自动触发。LevelDB中触发SST Compaction的因素包括Level 0 SST的个数,其他Level SST文件的总大小,某个文件被访问的次数。Compaction线程一次Compact的过程如下:
- 首先根据触发Compaction的原因以及维护的相关信息找到本次要Compact的一个SST文件。对于Level0的文件比较特殊,由于Level0的SST文件由Memtable在不同时间Dump而成,所以可能有Key重叠。因此除该文件外还需要获得所有与之重叠的Level0文件。这时我们得到一个包含一个或多个文件的文件集合,处于同一Level。
- SetupOtherInputs: 在Level+1层获取所有与当前的文件集合有Key重合的文件。
- DoCompactionWork:对得到的包含相邻两层多个文件的文件集合,进行归并操作并将结果输出到Level + 1层的一个新的SST文件,归并的过程中删除所有过期的数据。
- 删除之前的文件集合里的所有文件。通过上述过程我们可以看到,这个新生成的文件在其所在Level不会跟任何文件有Key的重叠。
总结
通过对LevelDB设计思路,整体结构以及其工作过程的介绍。相信已经对LevelDB有一个整体的印象。接下来还将用几篇博客,更深入的介绍LevelDB的数据管理,版本控制,迭代器,缓存等方面的设计和实现。



















