【51CTO.com原创稿件】计算机诞生之日起,人机交互的问题就一直限制着我们工作效率和使用体验。从纸带打孔到命令行、从键盘鼠标到图像界面、从触控屏幕到语音输入,随着更多更新的技术出现和演进,人机交互的方式正在变得越来越友好自然。语音技术本身在基础算法、应用场景、交互体验等方面也经历了诸多进化,到今天已经可以实现全双工上下文连续的自然的人机交互的需求了。
大家好,我是科大讯飞的汪舰,很高兴有机会和大家做这次技术分享。
分享主要从以下三个方面展开
1、解析一下讯飞全双工的上下文连续交互的原理和架构介绍;
2、智能语音交互项目落地的一些总结;
3、讯飞开放平台语音相关技术介绍,以语音识别为例介绍HMM模型原理。
计算机诞生之日起,人机交互的问题就一直限制着我们工作效率和使用体验。从纸带打孔到命令行、从键盘鼠标到图像界面、从触控屏幕到语音输入,随着更多更新的技术出现和演进,人机交互的方式正在变得越来越友好自然。语音技术本身在基础算法、应用场景、交互体验等方面也经历了诸多进化,到今天已经可以实现全双工上下文连续的自然的人机交互的需求了。
山东大汉纠正哥.mp4,点击查看视频
之前网上有个山东纠正哥的视频爆红网络,我们看一下视频回顾一下:
视频中的车载语音系统的人机交互体验就是非常糟糕的,分析其原因主要有以下几个方面,车载环境噪音影响严重;用户方言口音导致识别错误;交互过程中不能随时打断;不支持对话式纠错。
一、讯飞全双工的上下文连续交互的原理和架构介绍

为了增加难度我们考虑一下智能家居场景下的人机交互难题。在智能家居场景下的自然人机交互中,除了车载中噪音和口音的问题以外,也对我们提出了新的要求,就是需要解决远场拾音的问题,还有要能理解纷繁复杂的智能家居控制指令。如果解决不了远场拾音的问题,就会产生一个非常尴尬的情况,就是我要语音控制一个家电,我还需要走到它的跟前说话,既然走到跟前了,干脆点一下开关拉倒了。
说到这里就想机器人产品领域中一个搞笑的段子:我喊机器人到我跟前来,有点远它听不见,于是我需要走到机器人的跟前去再喊一遍。以上所说的这些“说话要靠近”、 “环境要安静”这些问题在移动手机终端上的场景中则相对简单的多。

总结一下上面的问题,我们需要做如下五个工作:第一个就是远场拾音和降噪,第二个就是要能识别用户的方言口音,第三个是实现全双工的交互,就是我能随时打断机器,对它下达新的命令;第四个是纠错,能够在对话中纠正输入错误的部分;第五个上下文关联的多轮对话,要能够持续的识别用户说的多个命令或者提问。
只有解决了这些问题才是相对自然友好的人机交互体验。

下面我们来看一下人工智能时代的人机交互界面——AIUI,看看它是如何逐个解决上面提到的那些问题的。
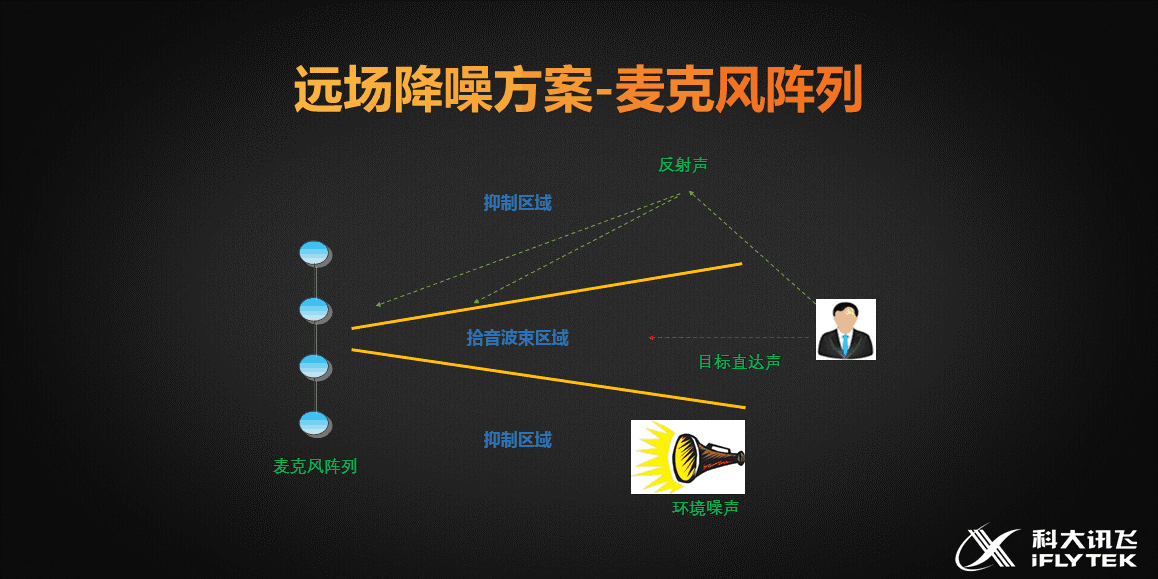
第一个,先来看看降噪和远场拾音的问题,这两个看似独立的问题,其实是同一个问题。它们影响识别效果的原因都是它们明显降低了录音音频的信噪比,所以这两个问题的解决思路也是一致的——提高信噪比。
AIUI的硬件拾音部分使用的是麦克风阵列系统,通俗的说就将多个麦克风按照特定的位置距离构型组成一个阵列,利用冗余的多路拾音的数据,通过降噪算法使得有效音频部分得到增强,从而提高信噪比。麦克风阵列被唤醒词唤醒,开始工作后会识别目标说话人相对阵列角度位置,从而增强目标拾音波束区域的声音,抑制其他角度过来的环境噪声和环境反射声。上面这种图中展示的是四麦线性阵列的降噪原理图。
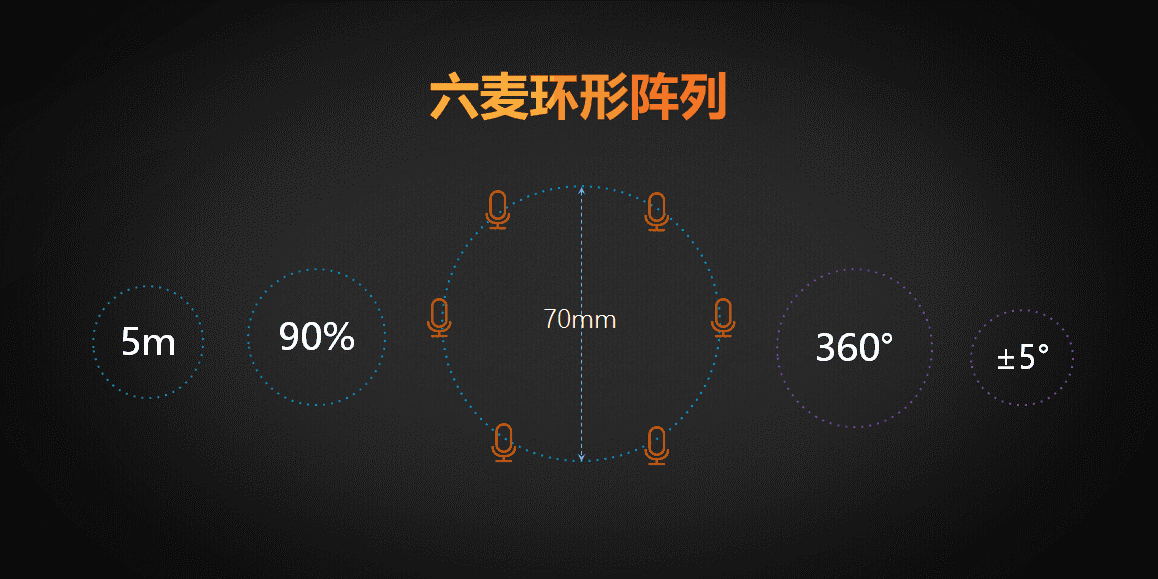
目前用的比较多的是六麦环形阵列,顾名思义就是六个麦克风按照环形均匀分布的构型。该环形结构的直径是7厘米,她的最大有效拾音距离是5米,拾音数据的识别准确度是90%,由于是环形结构所以角度定位范围是360度,定位误差是正负5度。而线性阵列的角度定位范围是180度,因为它的线性结构的两边是对称的。
另外我们前面提到的实时打断功能也是麦克风阵列模块实现的,阵列处理可以接受若干路麦克风录音数据以外,还可以接受一路机器自身播放的声音(回声)做为参考信号。阵列可以将麦克风录音的回声部分过滤掉,这样识别作业就不会收到回声的干扰,我们就可以用语义让正在播放音乐智能音响切歌。
再来看一下第二个问题:方言口音的识别问题。目前AIUI可以做到方言口音普通话的自适配,而AIUI中的搭载的语音识别引擎还支持包括东北话、粤语、上海话、湖南话、闽南语等在内的21种方言的识别。相关方言识别的效果可以在讯飞输入法app中体验。

第三个问题:用户语义场景匹配的问题。以智能家居场景为例,目前市面上的家居家电电子产品不胜枚举,每个产品的控制指令也不尽相同,而每条指令用户的表达方式又千差万别。这些都给智能家居产品的落地增加了非常大难度。AIUI语义系统内置了39中常见家居产品的控制场景,用户只需要通过勾选配置就可以使用它们。
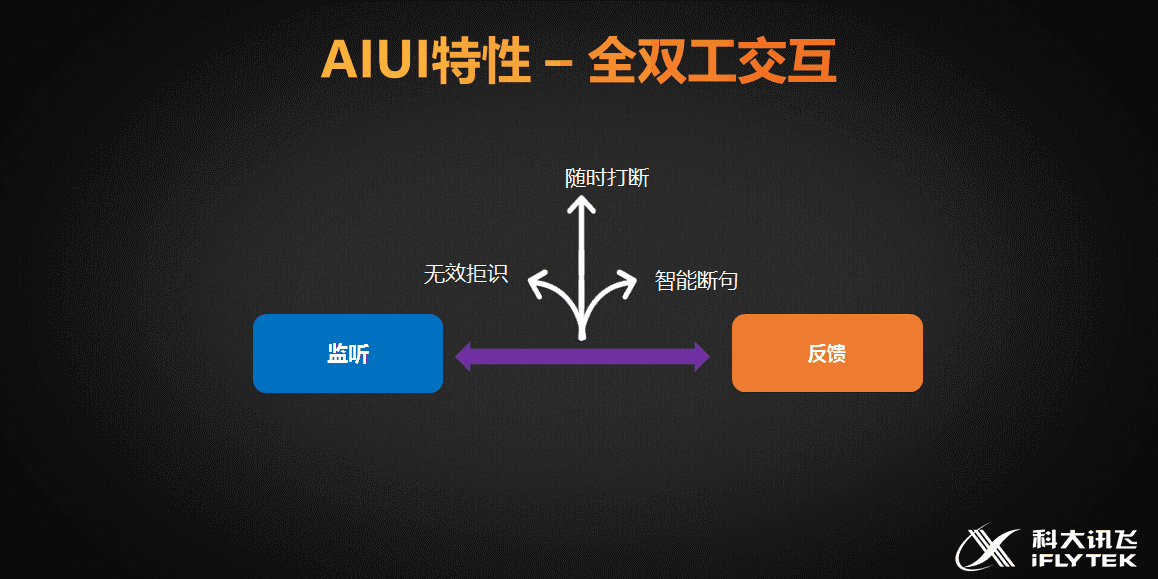
第四个问题:全双工持续交互的问题。目前常见的语音识别交互流程大多是,通过按键等操作来启动一次识别,识别得到结果后,自动停止,再次识别需要再次按键操作。而AIUI的可以做到“录音”、“断句处理”、“识别反馈”三个模块独立流水作业,也就是启动识别后,一直在录音,用户可以一直说话,也可以持续的得到所说命令的反馈,知道用户主动停止的识别会话,或者用户一直不再说话,识别自动超时停止。
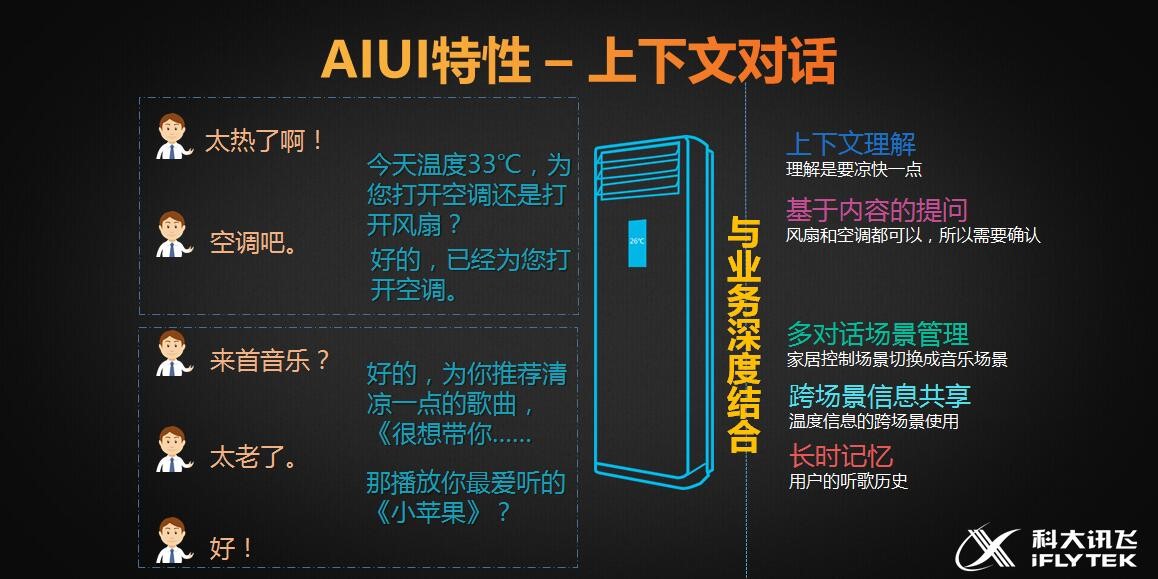
第五个问题:上下文对话理解。对于很多比较复杂的功能,用户很难一句话两句话表达清楚,我们智能采用上下文多轮对话的方式来改善用户的交互体验。例如订火车票的场景,大部分用户都是在和机器的多次对话中补充说明业务所需的参数:出发地、目的地、出发时间、座次、票价范围等等。
另外如上图所示,利用上下文交互得到的历史信息,我们也可以给比较燥热的你推荐写清凉的歌曲。
说了这么多,可能比较抽象,下面我想给大家直观感受下AIUI实现的人机交互到底能实现怎么样的交互到底是什么样的。
这个是我们15年12月12号在北京国家会议中心发布的最新的人工智能交互的效果演示。
2015发布会.mp4,点击查看视频
二、智能语音交互项目落地的一些总结
下面我们看几个使用AIUI的落地产品的例子。

她可以通过声音控制音响,可以选择切歌,调节音量,甚至可以控制智能家居。

这个可以通过语音进行空调的温度、风量控制,以及开关机等操作。

公子小白机器人,除了具有和普通的语音机器人类似的功能外,还具有把头转写说话人进行对话的功能,其实现原理就是前面介绍的麦克风阵列的波束定位的功能。
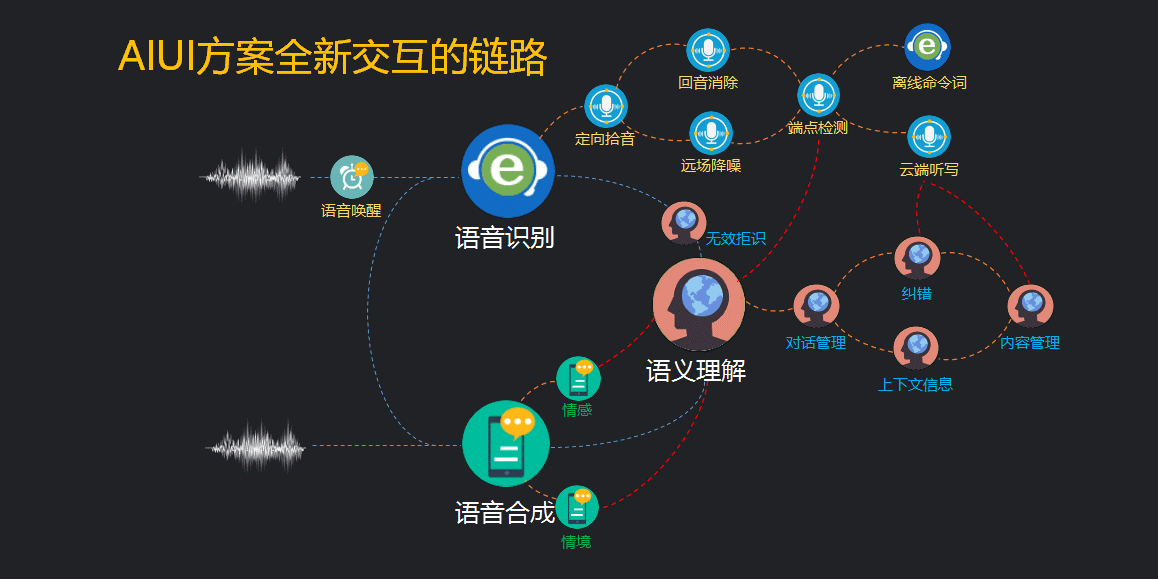
那么下面我们来总结下新的人机交互流程。
1、唤醒是必须,此后进入持续交互过程
2、语音识别新增需调控的子环节,分散在硬件、软件、云端各个部分相配合
3、因为持续交互,拒识成为必须
4、语义理解不再是单次简单的语义抽取,需要按照对话进行管理,并且增加了对话相关的多个环节配合
5、语音合成的更多特性需求
6、识别和语义之间需要互相配合以达到最佳,合成的效果也需要依据语义对话来调控。
三、讯飞开放平台语音相关技术介绍,以语音识别为例介绍HMM模型原理。

下面的时间,给大家从技术原理的角度简单介绍一下语音识别,语音识别简单的说通过语音信号处理和模式识别等技术让机器自动识别甚至是理解人类口述的语言。相对于语音合成(文字转语音),语音识别的发展历史要短很多,只有几十年的时间。

来看一下语音识别的大概过程。首先是声音的输入,输入的音频既可以是实时的来自于麦克风,也可以来自于现成的音频文件。然后是音频信号的预处理,包括降噪、回声消除、端点检查和模数转换等等。特征提取,就是从音频信号中提取出对识别有用的信息,将这些信息拿到声学模型中去匹配,会得到这些音频信号的发音信息,比如这里例子中的科大讯飞四个字的发音信息。然后把这些发音信息拿到语言模型中匹配,找出最大概率的发这四个音的汉字。这样一个识别的过程就完成了。
这过程中比较核心的部分就是声学模型和语言模型的匹配和处理,鼎鼎大名的HMM(隐马尔科夫模型)和深度神经网络就是在这里发挥作用的。
由于HMM只需要少量的数据就能训练出一个可用的模型,所以在上世界80、90年代,HMM技术在语音识别领域几乎是处于统治地位的,直到之后互联网特别是移动互联网还有大数据技术的爆发,数据的来源已经完全不是问题的情况下,深度神经网络才逐渐让HMM退居二线。下面我们以HMM为例,讲解一下它在语音识别中是如何发挥作用的。

先跟大家分享一个异地恋的故事,我从网络听来的,非常感人所以和大家分享一下。话说小明有个女朋友在北京上学。。。。。。。(见图片)
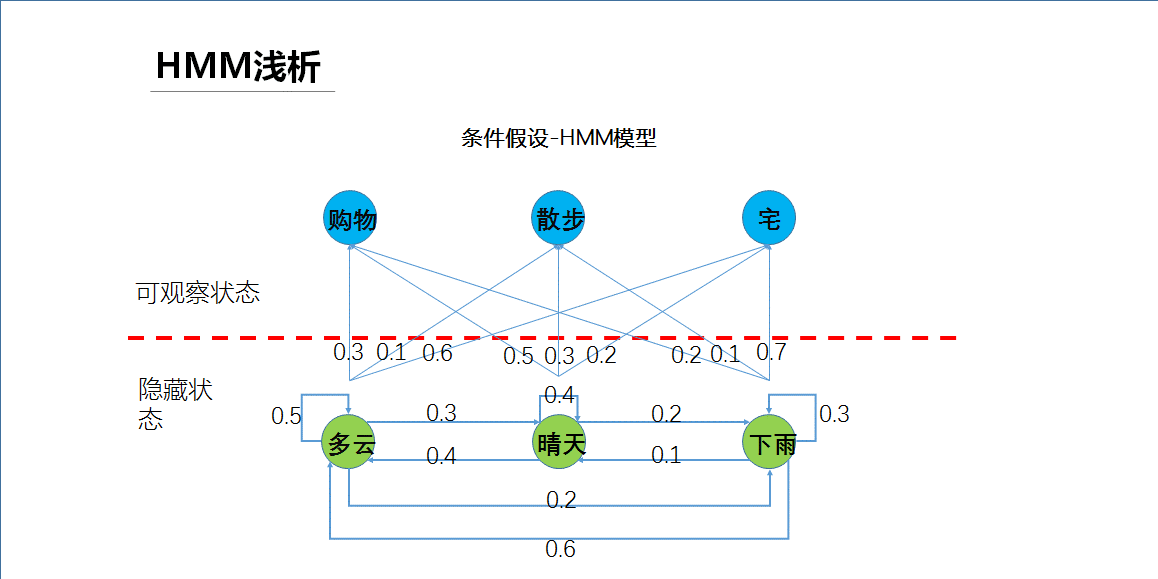
为了让复杂的问题简化便于我们讲解原理,我们来给出一些假设条件,比如女朋友只有购物散步和宅家里这三种活动(这些叫可观察到的状态),天气也只有多云晴天和下雨三种(这些叫隐藏的状态,就是小明无法直接观察到的状态),再比如第一天是多云的情况下,第二天还是多云的概率是0.5、是晴天的概率是0.3、是下雨的概率是0.2;再比如今天是晴天的情况下,女朋友去购物的概率是0.5,去散步的概率是0.3,宅家里的概率是0.2。那么所有上述的假设条件合在一起其实就形成了一个模型,这个模型就叫做HMM模型。
模型建好之后,那么问题来了。。。

这三个问题在很早以前就有很多算法大师给出了解法,也就是说这些看起来很难解的问题对计算机来说都很快解出来。
那么同学可能要问了,你讲了半天故事,和语音识别到底有什么关系啊?不要浪费时间直接讲重点。
好,我下面将第二个问题和第三个问题抽象一下。

左边这个部分就对应刚刚的第二个问题:已知模型参数,和女朋友的活动序列(就是可观察状态链),来求最大概率的隐藏状态链(也就是这三天天气的变化序列)。
而语音识别也是已知一个HMM和一段我们可观察到的波形,来求这段音频包含的最大概率的隐藏状态,这里隐藏状态链指的就是识别结果中的文字。
对于第三个问题,由于缺少了一个已知的HMM模型,所以我们需要先利用已知的历史数据来训练一个可用的模型,然后再来求识别结果。
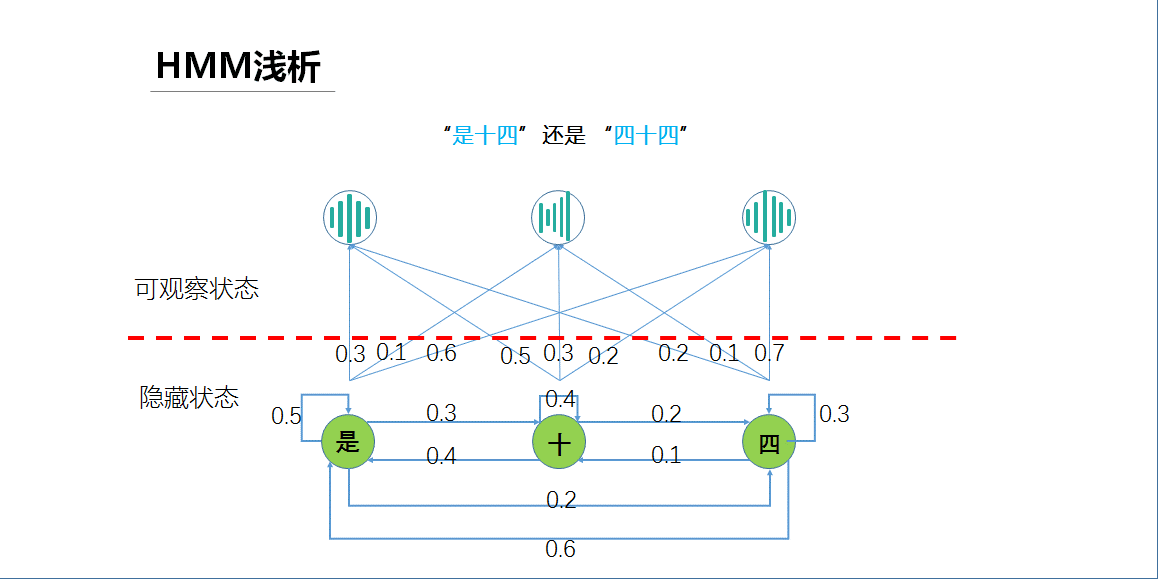
这张图片应该看的更加清楚了,同样一个模型,同样一套模型参数,各个状态转化和映射概率都没有变,我们把可观察状态换成语音识别的输入波形(或者说是波形特征),把隐藏状态换成语音识别的输出(也就是文字结果),就会发现这个HMM用来做语音识别简直太合适啦。比如这里的例子,这样三个连续的波形隐含的文字到底是“是十四”还是“四十四”,我们只需要分别把它们的概率算出来,哪个概率大我们就认为是哪个结果。对于HMM模型未知的情况下,我们可以利用带标注的数据按照鲍姆-韦尔奇算法训练一个就可以了,只有足够的数据就能训练出趋于完美的模型。
注意,这个例子中我们并没有区分声学模型和语言模型,而是将两者放在一起抽象出来一个大的模型,将波形直接映射成文字,而省去类似拼音发音的中间结果。事实上HMM也的确是既可以做声学模型,也可以做语言模型。
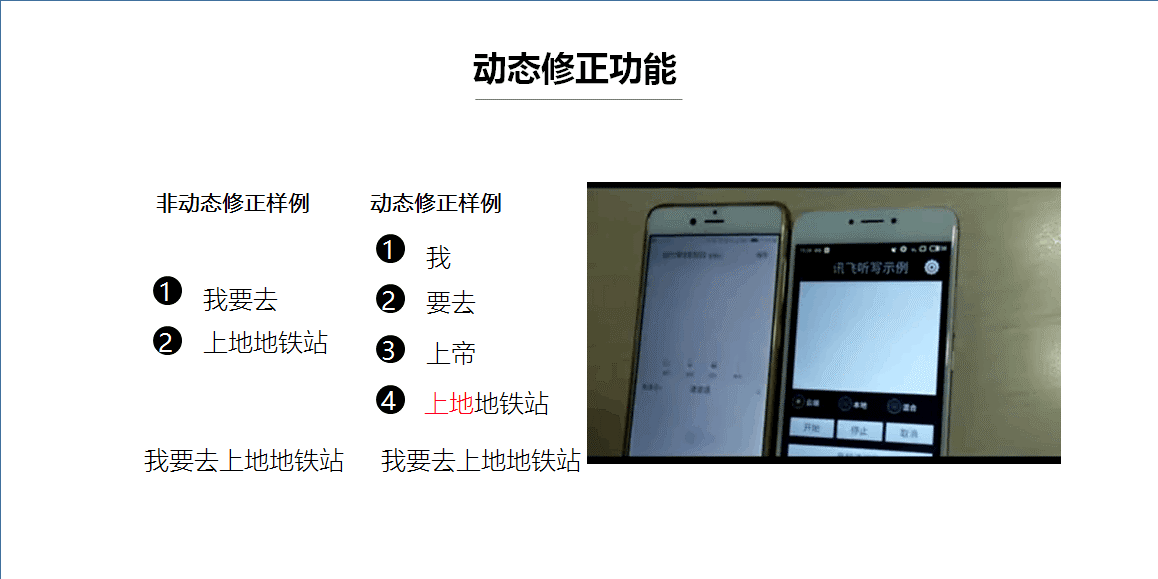
最后给大家介绍一个比较炫酷的功能——动态修正,其实细心的小伙伴已经在之前的发布会的视频中注意到它了。动态修正可以获得更好的用户交互体验,用户可以更加实时的拿到识别结果,虽然中间的过程当中可能部分结果会不准确,但是随着上下文的判断,引擎最终可以修正为准确的识别结果。因此是否开启动态修正功能,最终的识别结果都是一样的。了解动态修正之前需要先了解一点:听写的识别结果是分多次返回的,将多次返回的结果拼接起来才是完整的结果。
动态修正.mp4,点击查看视频
这个是动态修正的对比演示视频。
以下问题是来自51CTO开发者社群小伙伴们的提问和分享
Q:运维-罗盘-上海:这个是通过嵌入式开发出来的?
A:讯飞开放平台-汪舰老师:AIUI是软硬一体的解决方案,其中硬件部分负责录音和降噪的部分,识别理解和合成的部分是通过软件接口来调用实现的。
Q:运维-罗盘-上海:从拾取到反馈需要多久?
A:讯飞开放平台-汪舰老师:网络正常的情况下,一般的业务从用户说话,到结果播报(展示出来)的延迟平均在600ms以内
Q:Android-磐石-北京:全双工持续对话,是仅针对当前某一个用户吗?如果是两个人交替发出指令,怎么识别和反馈?
A:讯飞开放平台-汪舰老师:可以,只要不是两个人站在同一个角度同时说话就可以识别。
Q:运维-罗盘-上海:使用量,按并发收费?
A:讯飞开放平台-汪舰老师:收费策略一般情况下按照访问次数来收费,针对不同客户的产品类型收费策略是比较灵活的。当然,也是一定的免费额度可以供小客户使用的。
Q:404→极星辰→广东:是完全展示出来,还是开始展示?
A:讯飞开放平台-汪舰老师:上面讲的延迟是完全展示,云端反馈的结果其实是文本,如果是订机票场景反馈的航班列表信息一般是客户端绘制屏幕UI展示出来,普通的文本结果客户端直接用合成播报出来即可。
Q:开发-沙蛎子-西安:上下文对话理解,这个是针对一个时间段内的么?
A:讯飞开放平台-汪舰老师:上下文的历史记录的清除有两种方式,第一种是用户通过api接口主动清除,另外一种是云端的超时自动清除。
Q:安徽-Coeus-PHP:可以购买到吗?
A:讯飞开放平台-汪舰老师:可以的,如果有需要逛逛讯飞开放平台的官方网站。就是这里,关于购买的问题,这边结束后,我们可以私聊哈,一对一支持。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】