概述
缓存概述
什么是缓存
缓存在wiki上的定义:用于存储数据的硬件或软件的组成部分,以使得后续更快访问相应的数据。缓存中的数据可能是提前计算好的结果、数据的副本等。典型的应用场景:有cpu cache, 磁盘cache等。本文中提及到缓存主要是指互联网应用中所使用的缓存组件。
为什么引入缓存
传统的后端业务场景中,访问量以及对响应时间的要求均不高,通常只使用DB即可满足要求。这种架构简单,便于快速部署,很多网站发展初期均考虑使用这种架构。但是随着访问量的上升,以及对响应时间的要求提升,单DB无法再满足要求。这时候通常会考虑DB拆分(sharding)、读写分离、甚至硬件升级(SSD)等以满足新的业务需求。但是这种方式仍然会面临很多问题,主要体现在:
性能提升有限,很难达到数量级上的提升,尤其在互联网业务场景下,随着网站的发展,访问量经常会面临十倍、百倍的上涨。
成本高昂,为了承载N倍的访问量,通常需要N倍的机器,这个代价难以接受。
一丶分布式高并发缓存设计系统
总体架构图
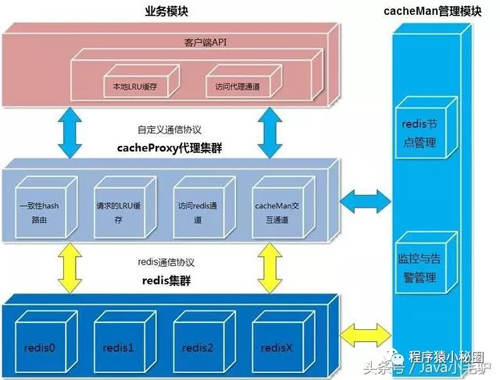
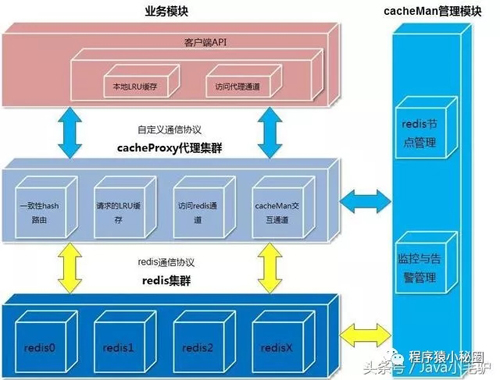
1.2自定义的客户端协议
业务模块采用自定义应用层协议和cacheProxy交互
整个cache后端采用什么协议,什么存储(redis,memcached等)对业务模块透明
cache后端和业务端进行了隔离,修改互不影响
1.2负载均衡与容错机制
采用一致性hash算法,即使部分节点down机,也不会导致全部的缓存失效,新增节点也不会导致大量缓存失效和重建
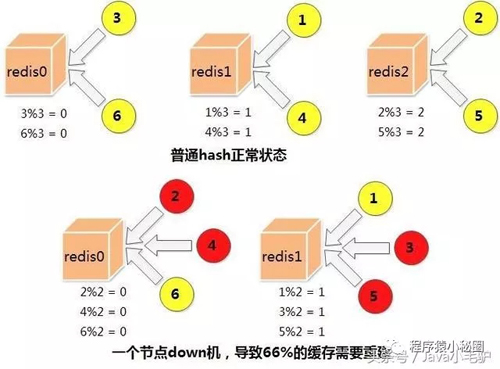
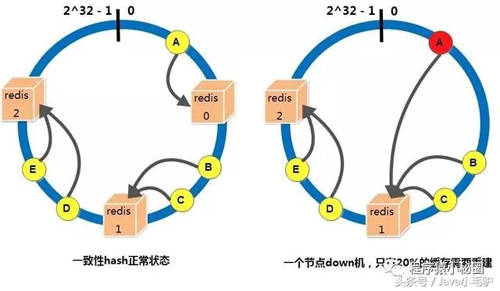
一份缓存数据保留两份,当前hash节点和下一个真实的hash节点,单个节点down机时,缓存也不会马上失效
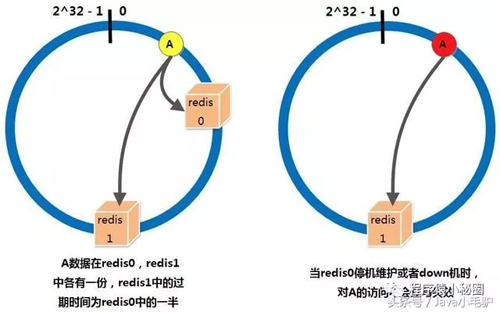
cacheMan是一个弱的管理节点,负责监控,删除节点,新增节点,可以任意启停
1.3缓存维护与淘汰机制
redis原生超时机制+三层LRU缓存架构,减少最终穿透到redis实例上的请求。
客户端LRU缓存
cacheProxy代理LRU缓存
redis实例内存总量限制+LRU缓存
1.4安全机制
redis实例都会开启auth功能
redis实例都监听在内网ip
1.5核心流程
新增redis节点
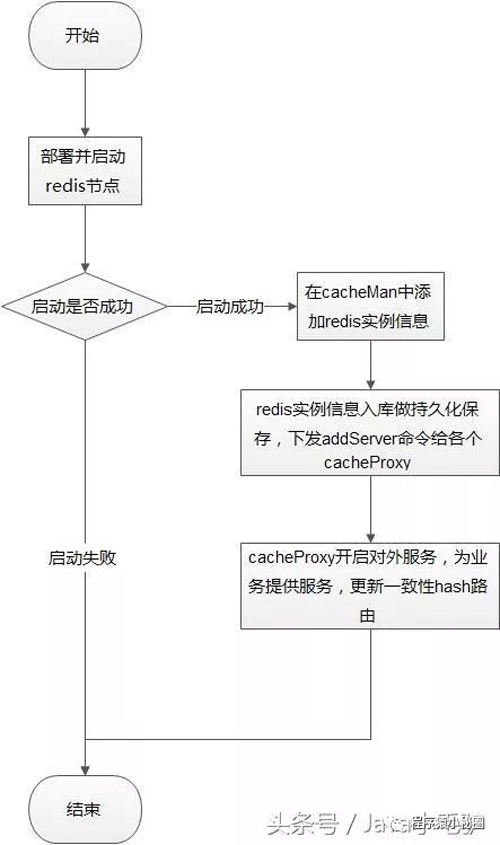
删除redis节点

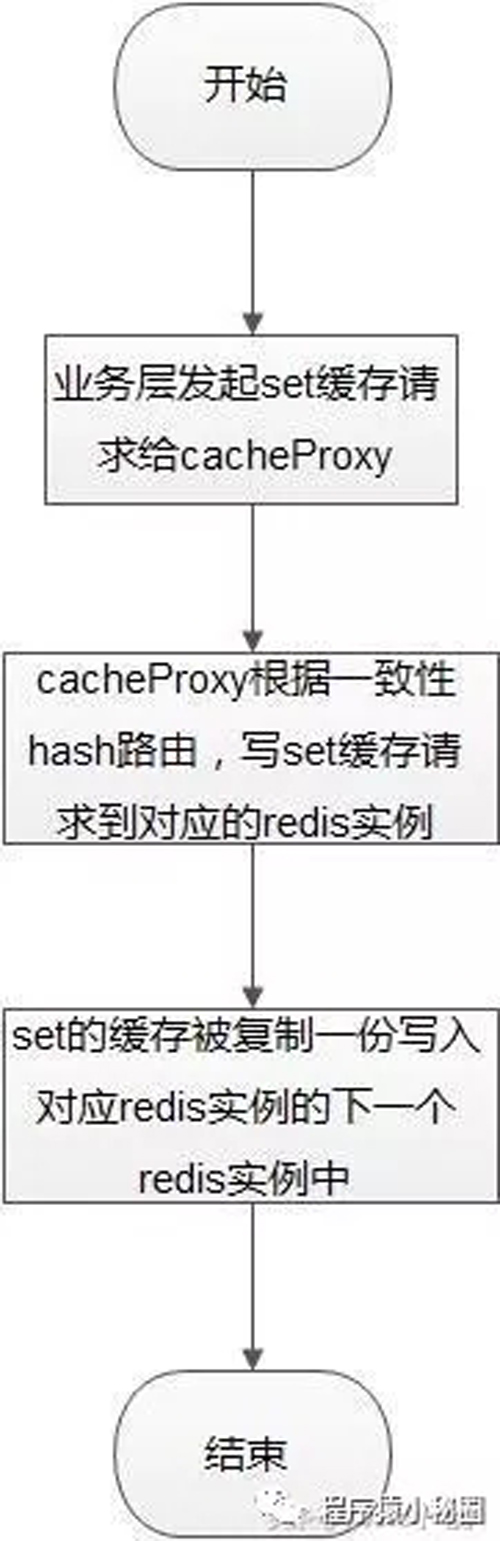
set缓存
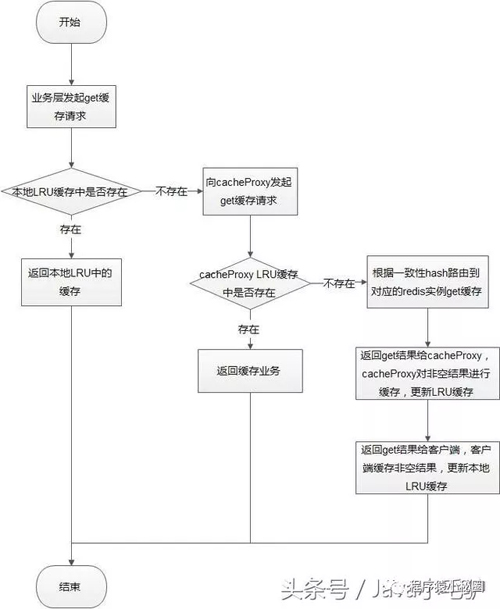
get缓存
二、问题
任何平台随着用户规模的扩大、功能不断的添加,持久化数据库层承受的读写压力会越来越大,一旦数据库承压过大会导致读写性能陡然下降,严重时会导致大量的业务请求超时,进而发生“雪崩”引发严重的故障。
三、解决方案
在业务层和数据库持久层之间引入一层内存缓存层,对于复杂且业务逻辑上不会变化的查询结果进行缓存,业务请求再次发起时,每次都先从缓存层中查询,从而大大减少对数据库的查询,减小对数据库的压力。
四、分布式内存缓存、本地单点缓存、应用层缓存对比
类型稳定性扩展性通用性对代码的侵入性
应用层缓存应用会频繁重启更新,缓存易丢失,稳定性不佳差,受限于进程的资源限制差,不同应用难以复用代码侵入性小,无网络操作,只需要操作应用进程内存
本地单点缓存独立的缓存应用(redis、memcached等),不会频繁重启,稳定性一般,但有单点故障问题一般,受限于单服务器资源限制一般,业务应用和缓存应用有强耦合代码侵入性一般,需要引入对应的api通常有网络操作
分布式内存缓存分布式系统,具备故障自动恢复功能,无单点故障问题,稳定性佳好,支持水平扩展好,对业务层提供通用接口,后端具体的缓存应用对业务透明代码侵入性一般,需要引入通用的api通常有网络操作。