起步
本章介绍如何不利用第三方库,仅用python自带的标准库来构造一个决策树。
熵的计算公式:
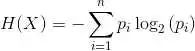
对应的 python 代码:

条件熵的计算
根据计算方法:
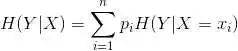
对应的 python 代码:
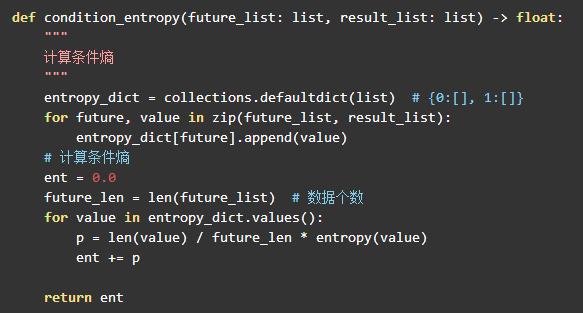
其中参数 future_list 是某一特征向量组成的列表,result_list 是 label 列表。
信息增益
根据信息增益的计算方法:
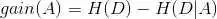
对应的python代码:
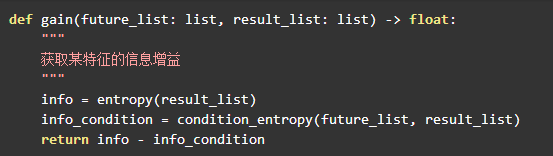 ..
..
定义决策树的节点
作为树的节点,要有左子树和右子树是必不可少的,除此之外还需要其他信息:
树的节点会有两种状态,叶子节点中 results 属性将保持当前的分类结果。非叶子节点中, col 保存着该节点计算的特征索引,根据这个索引来创建左右子树。
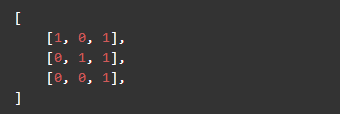
has_calc_index 属性表示在到达此节点时,已经计算过的特征索引。特征索引的数据集上表现是列的形式,如数据集(不包含结果集):
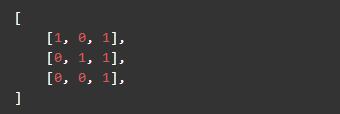
有三条数据,三个特征,那么***个特征对应了***列 [1, 0, 0] ,它的索引是 0 。
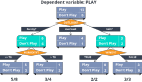
递归的停止条件
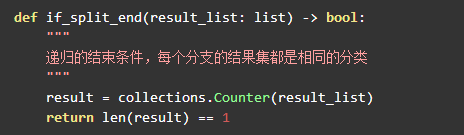
本章将构造出完整的决策树,所以递归的停止条件是所有待分析的训练集都属于同一类:
从训练集中筛选***的特征
因此计算节点就是调用 best_index = choose_best_future(node.data_set, node.labels, node.has_calc_index) 来获取***的信息增益的特征索引。
构造决策树
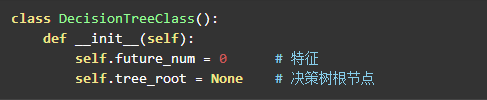
决策树中需要一个属性来指向树的根节点,以及特征数量。不需要保存训练集和结果集,因为这部分信息是保存在树的节点中的。
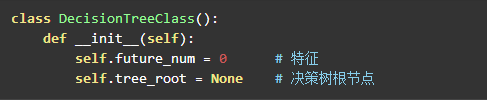
创建决策树
这里需要递归来创建决策树:
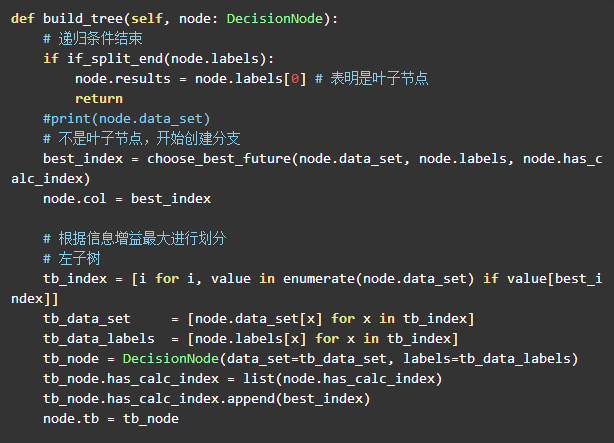

根据信息增益的特征索引将训练集再划分为左右两个子树。
训练函数
也就是要有一个 fit 函数:

清理训练集
训练后,树节点中数据集和结果集等就没必要的,该模型只要 col 和 result 就可以了:
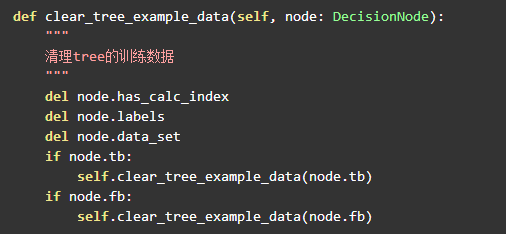
预测函数
提供一个预测函数:
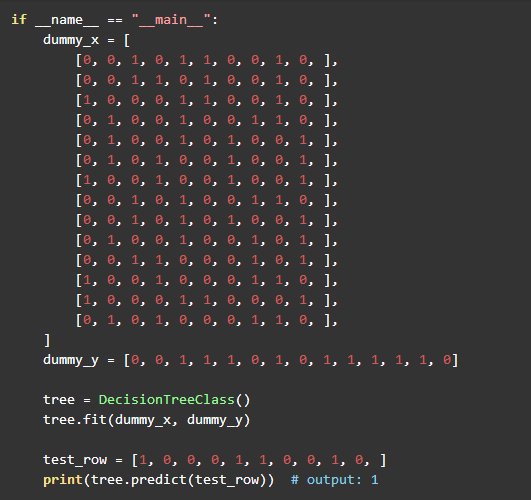
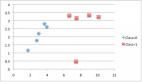
测试
数据集使用前面《应用篇》中的向量化的训练集: