作为创业公司和推行DevOps工程师们来说,都遇到过这样的问题:
1. 硬件资源利用率的问题,造成部分成本的浪费
在网站功能中不同的业务场景有计算型的,有IO读写型的,有网络型,有内存型的,集中部署应用就会导致资源利用率不合理的问题。比如,一个机器上部署的服务都是内存密集型,那么CPU资源就都很容易浪费了。
2. 单物理机多应用无法对无法进行有效的隔离,导致应用对资源的抢占和相互影响
一个物理机器跑多个应用,无法进行所使用的CPU,内存,进程进行限制,如果一个应用出现对资源的抢占问题,就会引起连锁反应,最终导致网站部分功能不可用。
3. 环境、版本管理复杂,上线部署流程缺乏,增加问题排查的复杂度
由于内部开发流程的不规范,代码在测试或者上线过程中,对一些配置项和系统参数进行随意的调整,在发布时进行增量发布,一旦出现问题,就会导致测试的代码和线上运行的代码是不一致的,增加了服务上线的风险,也增加了线上服务故障排查的难度。
4. 环境不稳定,迁移成本高,增加上线风险
在开发过程中存在多个项目并行开发和服务的依赖问题,由于环境和版本的复杂性很高,不能快速搭建和迁移一个环境,导致无法在测试环境中无法模拟出线上的流程进行测试,很多同学在线上环境进行测试,这里有很高的潜在风险,同时导致开发效率降低。
5. 传统虚拟机和物理机占用空间大,启动慢,管理复杂等问题
传统虚拟机和物理机在启动过程进行加载内核,执行内核和init进行,导致在启动过程占用很长时间,而且在管理过程中会遇到各种各样的管理问题。
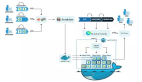
基于Docker容器技术,运维技术团队开发了五阿哥网站的容器云平台。通过容器云平台95%的应用服务已经实现容器化部署。这些应用支持业务按需拓展,秒级伸缩,提供与用户友好的交互过程,规范了测试和生产的发布流程,让开发和测试同学从基础的环境配置和发布解放出来,使其更聚焦自己的项目开发和测试。结合五阿哥容器云平台和Docker容器技术的实践,本文先介绍如何实现7*24小时“一站式”的持续交付,实现产品的上线。

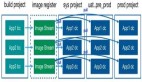
容器云平台架构图
一、Docker镜像标准化
众所周知,Docker的镜像是分层的。对镜像分层进行约定:
- 第一层是操作系统层,由CentOS/Alpine等基础镜像构成,安装一些通用的基础组件;
- 第二层是中间件层,根据不同的应用程序,安装它们运行时需要使用到的各种中间件和依赖软件包,如,Nginx、Tomcat等;
- 第三层是应用层,这层仅包含已经打好包的各应用程序代码。

Docker Image分层
经验总结:如何让自己的镜像变的更小,PUSH的更快?

Docker Image优化前后对比
- Dockerfile构建应用镜像,在中间件层遇到一些需要安装的软件包时,尽可能的使用包管理工具(如yum)或以git clone方式下载源码包进行安装,目的是将软件包的copy和安装控制在同一层,软件部署成功后清除一些无用的rpm包或源码包,让基础镜像的尺寸更小。
- Java应用镜像中并没有将JDK软件包打入镜像,将JDK部署在每台宿主上,在运行镜像时,通过挂载目录的方式将宿主机上的Java家目录挂载至容器指定目录下。因为它会把基础镜像撑得非常大。
- 在构建应用镜像时,Docker会对这两层进行缓存并直接使用,仅会重新创建代码出现变动的应用层,这样就提高了应用镜像的构建速度和构建成功后向镜像仓库推送的速度,从整体流程上提升了应用的部署效率。
二、容器的编排管理
编排工具的选型:

Docker编排工具对比
Rancher图形化管理界面,部署简单、方便,可以与AD、LDAP、GitHub集成,基于用户或用户组进行访问控制,快速将系统的编排工具升级至Kubernetes或者Swarm,同时有专业的技术团队进行支持,降低容器技术入门的难度。

Rancher架构图
基于以上优点我们选择Rancher作为我们容器云平台的编排工具,在对应用的容器实例进行统一的编排调度时,配合Docker-Compose组件,可以在同一时间对多台宿主机执行调度操作。同时,在服务访问出现峰值和低谷时,利用特有的rancher-compose.yml文件调用“SCALE”特性,对应用集群执行动态扩容和缩容,让应用按需求处理不同的请求。https:/zhuanlan.zhihu.com/p/29093407
容器网络模型选型:

Docker 网络对比
由于后端开发基于阿里的HSF框架,生产者和消费者之间需要网络可达,对网络要求比较高,需要以真实IP地址进行注册和拉取服务。所以在选择容器网络时,我们使用了Host模式,在容器启动过程中会执行脚本检查宿主机并分配给容器一个独立的端口,来避免冲突的问题。
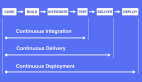
三、持续集成与持续部署
持续集成,监测代码提交状态,对代码进行持续集成,在集成过程中执行单元测试,代码Sonar和安全工具进行静态扫描,将结果通知给开发同学同时部署集成环境,部署成功后触发自动化测试(自动化测试部分后续会更新)。

持续集成
静态扫描结果:
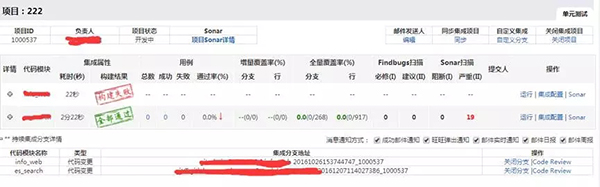
静态扫描结果
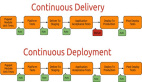
持续部署,是一种能力,这种能力非常重要,把一个包快速部署在你想要的地方。平台采用分布式构建、部署,Master管理多个Slave节点,每个Slave节点分属不同的环境。在Master上安装并更新插件、创建job、管理各开发团队权限。Slave用于执行job。

持续部署
基于上述架构,我们定义了持续部署规范的流程:
- 开发同学向GitLab提交代码;
- 拉取项目代码和配置项文件,执行编译任务;
- 拉取基础镜像,将编译好的应用包打入生成最新的应用镜像,推送到镜像仓库;
- 根据当前应用及所属环境定制化生成docker-compose.yml文件,基于这个文件执行rancher-compose命令,将应用镜像部署到预发环境(发布生产前的测试环境,相关配置、服务依赖关系和生产环境一致)。
- 预发环境测试通过后将应用镜像部署至线上环境,测试结果通知后端测试同学。
四、容器的运行管理
应用容器现在已经部署到线上环境,那么在整个容器的生命周期中,还需要解决下面两个问题:
- 如何保存应用程序产生的运行日志和其它业务日志;
- 如何在后端服务出现变化后nginx能够自动发现并完成配置更新。
五、日志管理
容器在运行时会在只读层之上创建读写层,所有对应用程序的写操作都在这层进行。当容器重启后,读写层中的数据(包含日志)也会一并被清除。虽然可以通过将容器中日志目录挂载到宿主机解决此类问题,但当容器在多个宿主机间频繁漂移时,每个宿主机上都会有留存应用名的部分日志,增加了开发同学查看、排查问题的难度。
综上所属,日志服务平台作为五阿哥网站日志仓库,将应用运行过程中产生的日志统一存储,并且支持多种方式的查询操作。

日志管理
通过在日志服务的管理界面配置日志采集路径,在容器中部署Agent把应用日志统一投递到Logstore中,再在Logstore中配置全文索引和分词符,以便开发同学能够通过关键字搜索、查询想要的日志内容。
经验总结:如何避免日志的重复采集问题?
日志服务的agent需要在配置文件“ilogtailconfig.json”中增加配置参数“checkpoint_filename”,指定checkpoint文件生成的绝对路径,并且将此路径挂载至宿主机目录下,确保容器在重启时不会丢失checkpoint文件,不会出现重复采集问题。
六、服务的注册
etcd是一个具备高可用性和强一致性的键值存储仓库,它使用类似于文件系统的树形结构,数据全部以“/”开头。etcd的数据分为两种类型:key和directories,其中key下存储单独的字符串值,directories下则存放key的集合或者其他子目录。

应用注册
在五阿哥环境中,每个向etcd注册的应用服务,它们的根目录都以”/${APPNAME}${ENVIRONMENT}”命名。根目录下存储每个应用实例的Key信息,它们都以“${IP}-${PORT}”的方式命名。
下图是使用上述约定,存储在etcd上某应用实例的数据结构:

etcd数据存储结构
可以看到我是使用get方法向etcd发送请求的,请求的是部署在预发环境(PRE)的搜索服务(search);在它的根目录“/search_PRE”下,仅存储了一个应用实例的信息,这个实例的key是“172.18.100.31-86”;对应的value是“172.18.100.31:86‘’,整个注册过程是这样的:
- 通过代码为容器应用程序生成随机端口,和宿主机正在使用的端口进行比对,确保端口没有冲突后写入程序配置文件;
- 把通过Python和etcd模块编写的服务注册工具集成在脚本中,将IP地址和上一步获取的随机端口以参数的方式传递给服务注册工具;
- 待应用程序完全启动后,由服务注册工具以约定好的数据结构将应用实例的写入etcd集群,完成服务注册工作;
- 容器定时向etcd发送心跳,报告存活并刷新TTL时间;
- 容器脚本捕获Rancher发送至应用实例的singnal terminal信号,在接收到信号后向etcd发送delete请求删除实例的数据。
注:在TTL基础上增加主动清除功能,在服务正常释放时,可以立刻清除etcd上注册信息,不必等待ttl时间。
经验总结:容器在重启或者意外销毁时,让我们一起看一下这个过程中容器和注册中心都做了什么事情?
应用在注册是携带key和value时携带了TTL超时属性,就是考虑到当服务集群中的实例宕机后,它在etcd中注册的信息也随之失效,若不予清除,失效的信息将会成为垃圾数据被一直保存,而且配置管理工具还会把它当做正常数据读取出来,写入web server的配置文件中。要保证存储在etcd中的数据始终有效,就需要让etcd主动释放无效的实例信息,来看一下注册中心刷新的机制,代码直接奉上:
- #!/usr/bin/env
- python
- import etcd
- import sys
- arg_l=sys.argv[1:]
- etcdetcd_clt=etcd.Client(host='172.18.0.7')
- def
- set_key(key,value,ttl=10):
- try:
- return
- etcd_clt.write(key,value,ttl)
- except TypeError:
- print 'key or vlaue is null'
- def
- refresh_key(key,ttl=10):
- try:
- return
- etcd_clt.refresh(key,ttl)
- except TypeError:
- print 'key is null'
- def
- del_key(key):
- try:
- return etcd_clt.delete(key)
- except TypeError:
- print 'key is null'
- if arg_l:
- if len(arg_l) == 3:
- key,value,ttl=arg_l
- set_key(key,value,ttl)
- elif len(arg_l) == 2:
- key,ttl=arg_l
- refresh_key(key,ttl)
- elif len(arg_l) == 1:
- key=arg_l[0]
- del_key(key)
- else:
- raise TypeError,'Only three
- parameters are needed here'
- else:
- raise Exception('args is null')
七、服务的发现
Confd是一个轻量级的配置管理工具,支持etcd作为后端数据源,通过读取数据源数据,保证本地配置文件为最新;不仅如此 ,它还可以在配置文件更新后,检查配置文件语法有效性,以重新加载应用程序使配置生效。这里需要说明的是,Confd虽然支持rancher作为数据源,但考虑易用性和扩展性等原因,最终我们还是选择了etcd。
和大多数部署方式一样,我们把Confd部署在web server所在的ECS上,便于Confd在监测到数据变化后及时更新配置文件和重启程序。Confd的相关配置文件和模板文件部署在默认路径/etc/confd下,目录结构如下:
- /etc/confd/
- ├── conf.d
- ├── confd.toml
- └── templates
confd.toml是Confd的主配置文件,使用TOML格式编写,因为我们etcd是集群部署,有多个节点,而我又不想把Confd的指令搞的又臭又长,所以将interval、nodes等选项写到了这个配置文件里。
cond.d目录存放web server的模板配置源文件,也使用TOML格式编写。该文件用于指定应用模板配置文件路径(src)、应用配置文件路径(dest)、数据源的key信息(keys)等。
Templates目录存放web server下每个应用的模板配置文件。它使用Go支持的text/template语言格式进行编写。在confd从etcd中读取到最新应用注册信息后,通过下面的语句写入模板配置文件中:
- {{range getvs "/${APP_NAME}/*"}}
- server {{.}};
- {{end}}

服务发现
通过Supervisor管理Confd进程。Confd在运行后会每隔5秒对etcd进行轮询,当某个应用服务的K/V更新后,Confd会读取该应用存储在etcd中的数据,写入到模板配置文件中,生成这个应用配置文件,最后由Confd将配置文件写入到目标路径下,重新加载Nginx程序使配置生效。