












本文作者是一名地地道道的程序员,最大的乐趣就是爬各种网站。特别是在过去的一年里,为了娱乐和利润而爬掉了无数网站。从小众到主流电子商店再到新闻媒体和文学博客,通过使用简单的工具(如BeautifulSoup)获得了很多有趣且干净的数据—我也很喜欢Chrome 的Headless模式。
本文,作者将分析从Greek wine e-shop商店(一个希腊葡萄酒网站)中获得的数据,来看看哪种葡萄酒最受欢迎。
scraper本身相当简单,可以在GitHub页面(https://github.com/Florents-Tselai/greek-wines-analysis)找到。作者将着重于通过使用标准的Python包对得到的数据(1125个独特的标签)做一些快速的探索性分析。
scraper本身暴露了一个相当简单的API。首先,请求葡萄酒页面的数据,并将数据返回给nicedict,如下所示:
In [2]:

In [3]:

Out[3]:

然后,定义一些matplotlib。
In [4]:

加载由houseofwine_gr.dump模块生成的数据转储,开发者也可以在GitHub页面找到.json,.csv和.xlsx的数据集。
In [5]:

以下是所拥有数据的视图:
In [6]:

Out[6]:
用np.nan替换空的字符串,使它们更容易处理 Pandas。
In [7]:

重命名一些包含特殊字符的列名,以便将它们用作本机DataFrame存储器。
In [8]:
我们还将适当的类型分配给列:
In [9]:

让我们将color列值从希腊语翻译成英语。
In [10]:

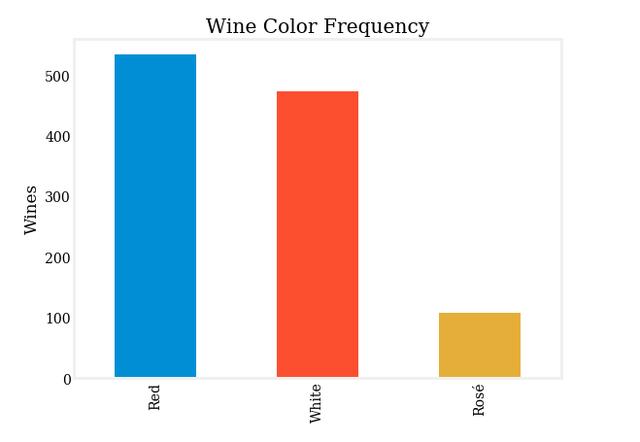
以下是数据集的颜色直方图。
In [11]:

以下是每种葡萄酒的简单指标分布情况:
In [12]:
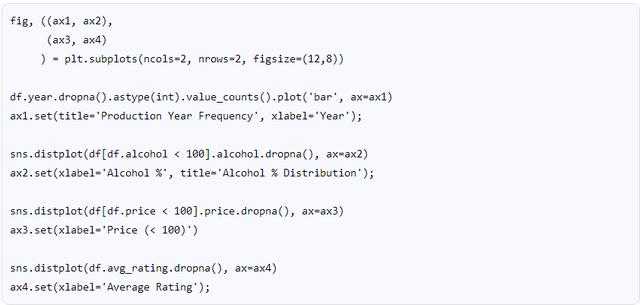
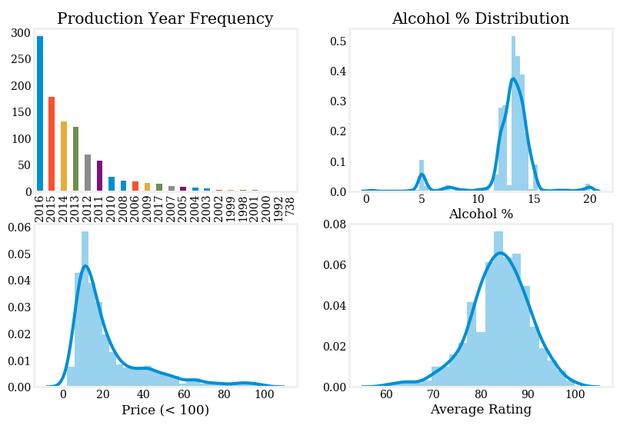
如图所示,Average Rating列几乎为正态分布,μ值高达85以上。 Reddit上的Kroutoner解释了为什么会发生这种情况(并纠正了作者以前的错误):
典型的葡萄酒评级是50-100,而不是0-100。所以看起来似乎只有一半分布,实际上是一个几乎完全的分布。此外,90分以上的葡萄酒一般被认为效果更好,销售也更好。这个事实改变了对数据的解释,也就是说大多数葡萄酒被评为好,只有一小部分被评为非常好。
为了进一步推进,来看一下tags 列。
似乎每个标签列表可以给出有关葡萄酒的各种属性(品种,甜味等)的信息。接下来,作者将这些属性分开,将tags列元素从list 转换为set列表元素,因为这样会使操作更简单。也就是说,不是在一个if x in -else-try-except-IndexError中,我们将使用set操作。

现在,做一些简单操作来提取关于甜度,温和性等信息,以下信息同样从希腊语翻译到了英语。
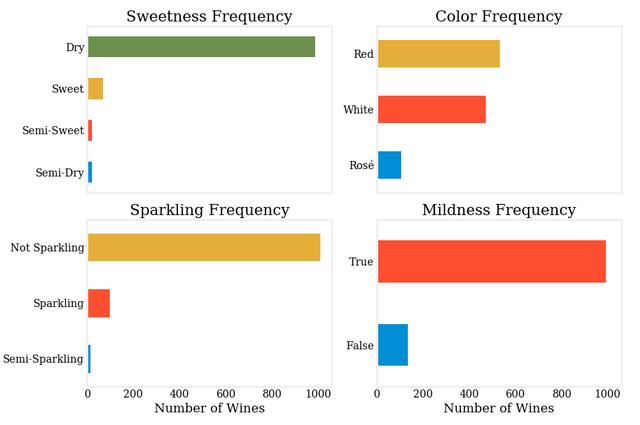
以下是4个属性中每一个属性的直方图:

在这一点上,开发者可以(几乎)安全地假设所有剩下的标签显示每种葡萄酒的品种信息,所以定义一个新的列来存储它们。

由于解析错误,列中出现了一些整数,我们将其过滤掉。
我们也可以添加一个布尔变量varietal。酒中的混合物只有一种的称为varietal,至少有两种混合物的称作blends。

对于varietal葡萄酒,我们设定了一个single_variety - 对于其他非varietal的葡萄酒来说,这个数值将是NaN。
让我们来看看Varietal / Blend的分布是怎样的。
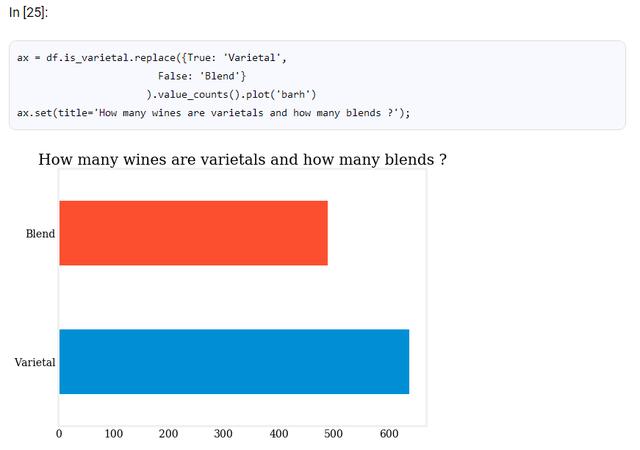
这是一些指示性的情节。
In [27]:

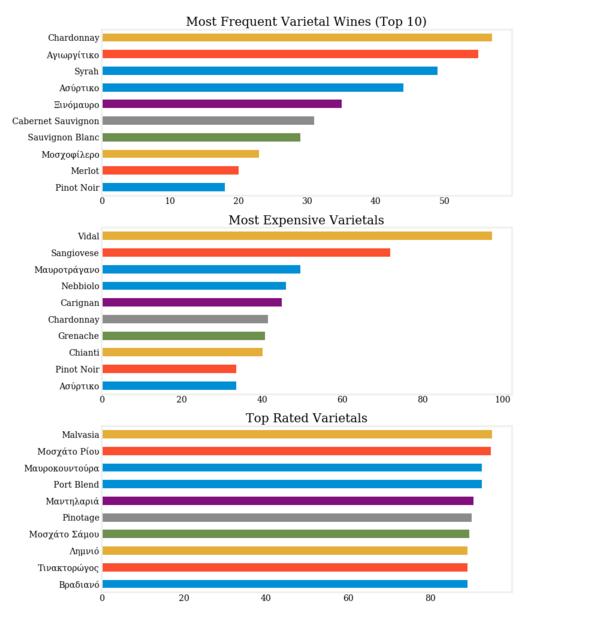
看起来Chardonnay是最流行的品种,而Vidal和Sangiovese是最昂贵的品种。评分最高的是Malvasia,但所有品种都非常接近。
把注意力转移到blends上,我们做了一些Numpy和Scikit-Learn来产生blends的矩阵。
上面的代码简单地从这里得到:
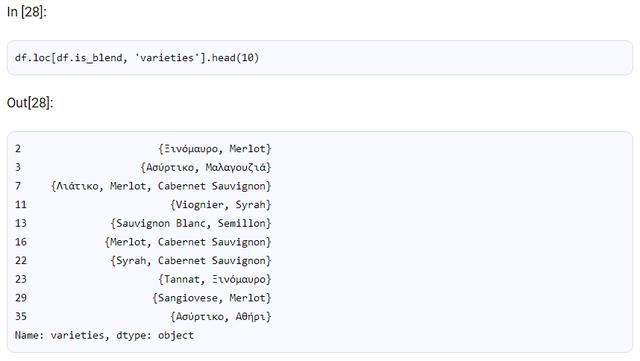
对此:
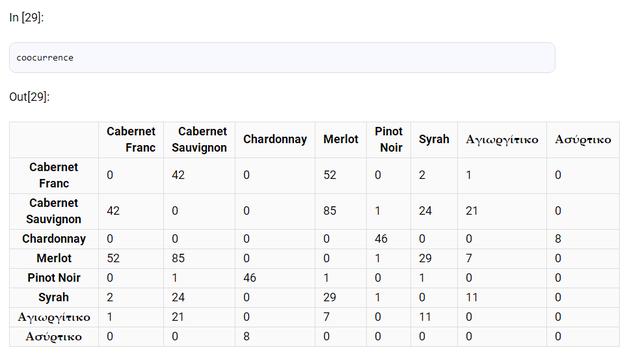
这些是blends中出现频率最高的品种。
In [30]:

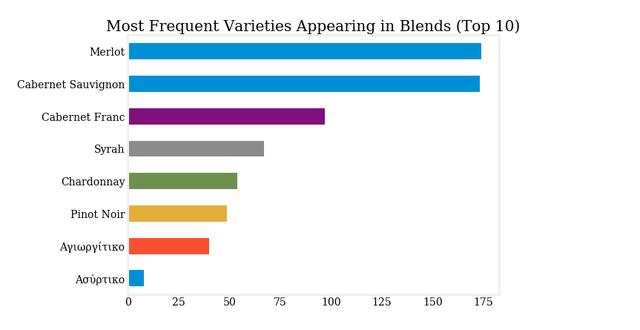
这里是一个热图,显示哪些品种通常混合在一起。
In [31]:

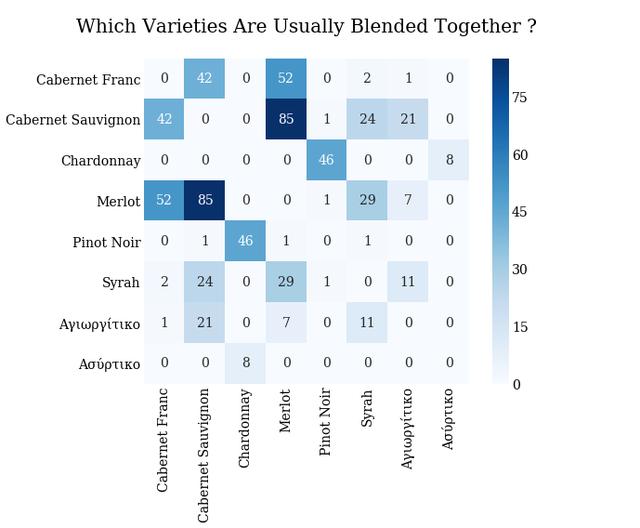
In [32]:

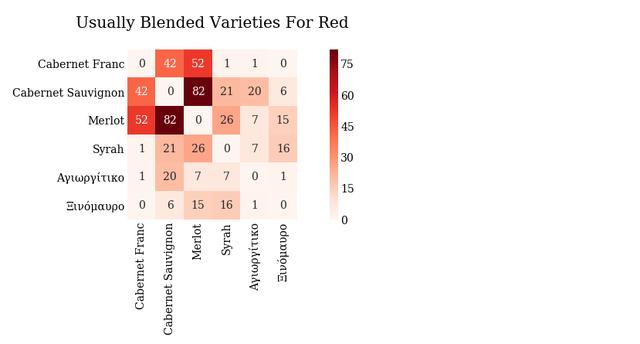
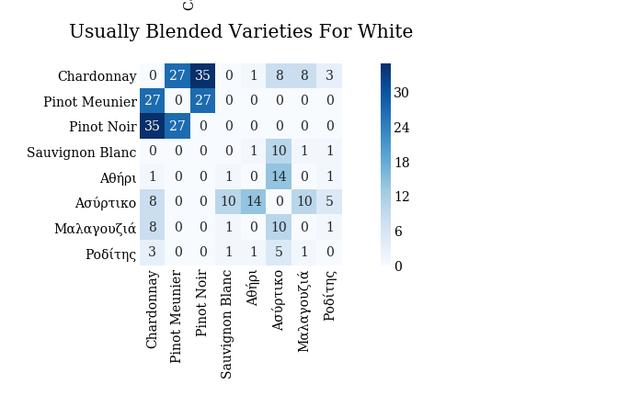
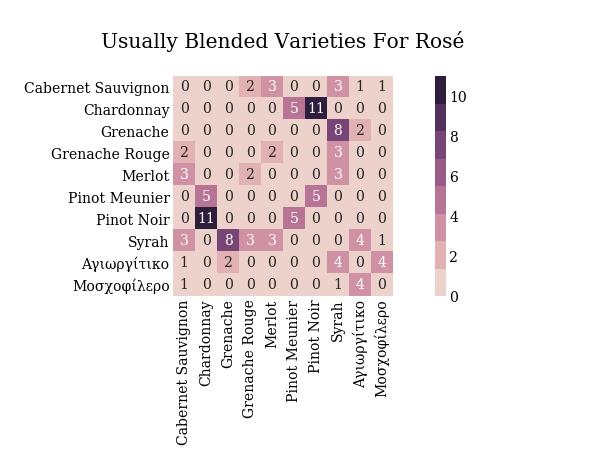
如果你有兴趣,欢迎来Github页面与作者交流。

















