












这篇文章主要关注的是深度学习领域一个并不非常广为人知的应用领域:结构化数据。本文作者为旧金山大学(USF)在读研究生 Kerem Turgutlu。
使用深度学习方法按照本文所介绍的步骤处理结构化数据有这样的好处:
- 快
- 无需领域知识
- 表现优良
在机器学习/深度学习或任何类型的预测建模任务中,都是先有数据然后再做算法/方法。这也是某些机器学习方法在解决某些特定任务之前需要做大量特征工程的主要原因,这些特定任务包括图像分类、NLP 和许多其它「非常规的」数据的处理——这些数据不能直接送入 logistic 回归模型或随机森林模型进行处理。相反,深度学习无需任何繁杂和耗时的特征工程也能在这些类型的任务取得良好的表现。大多数时候,这些特征需要领域知识、创造力和大量的试错。当然,领域专业知识和精巧的特征工程仍然非常有价值,但这篇文章将提及的技术足以让你在没有任何领域知识的前提下向 Kaggle 竞赛的前三名看齐,参阅:http://blog.kaggle.com/2016/01/22/rossmann-store-sales-winners-interview-3rd-place-cheng-gui/
图 1:一只萌狗和一只怒猫
由于特征生成(比如 CNN 的卷积层)的本质和能力很复杂,所以深度学习在各种各样的图像、文本和音频数据问题上得到了广泛的应用。这些问题无疑对人工智能的发展非常重要,而且这一领域的顶级研究者每年都在分类猫、狗和船等任务上你追我赶,每年的成绩也都优于前一年。但在实际行业应用方面我们却很少看到这种情况。这是为什么呢?公司企业的数据库涉及到结构化数据,这些才是塑造了我们的日常生活的领域。
首先,让我们先定义一下结构化数据。在结构化数据中,你可以将行看作是收集到的数据点或观察,将列看作是表示每个观察的单个属性的字段。比如说,来自在线零售商店的数据有表示客户交易事件的列和包含所买商品、数量、价格、时间戳等信息的列。
下面我们给出了一些卖家数据,行表示每个独立的销售事件,列中给出了这些销售事件的信息。

图 2:结构化数据的 pandas dataframe 示例
接下来我们谈谈如何将神经网络用于结构化数据任务。实际上,在理论层面上,创建带有任何所需架构的全连接网络都很简单,然后使用「列」作为输入即可。在损失函数经历过一些点积和反向传播之后,我们将得到一个训练好的网络,然后就可以进行预测了。
尽管看起来非常简单直接,但在处理结构化数据时,人们往往更偏爱基于树的方法,而不是神经网络。原因为何?这可以从算法的角度理解——算法究竟是如何对待和处理我们的数据的。
人们对结构化数据和非结构化数据的处理方式是不同的。非结构化数据虽然是「非常规的」,但我们通常处理的是单位量的单个实体,比如像素、体素、音频频率、雷达反向散射、传感器测量结果等等。而对于结构化数据,我们往往需要处理多种不同的数据类型;这些数据类型分为两大类:数值数据和类别数据。类别数据需要在训练之前进行预处理,因为包含神经网络在内的大多数算法都还不能直接处理它们。
编码变量有很多可选的方法,比如标签/数值编码和 one-hot 编码。但在内存方面和类别层次的真实表示方面,这些技术还存在问题。内存方面的问题可能更为显著,我们通过一个例子来说明一下。
假设我们列中的信息是一个星期中的某一天。如果我们使用 one-hot 或任意标签编码这个变量,那么我们就要假设各个层次之间都分别有相等和任意的距离/差别。

图 3:one-hot 编码和标签编码
但这两种方法都假设每两天之间的差别是相等的,但我们很明显知道实际上并不是这样,我们的算法也应该知道这一点!
「神经网络的连续性本质限制了它们在类别变量上的应用。因此,用整型数表示类别变量然后就直接应用神经网络,不能得到好的结果。」[1]
基于树的算法不需要假设类别变量是连续的,因为它们可以按需要进行分支来找到各个状态,但神经网络不是这样的。实体嵌入(entity embedding)可以帮助解决这个问题。实体嵌入可用于将离散值映射到多维空间中,其中具有相似函数输出的值彼此靠得更近。比如说,如果你要为一个销售问题将各个省份嵌入到国家这个空间中,那么相似省份的销售就会在这个投射的空间相距更近。
因为我们不想在我们的类别变量的层次上做任何假设,所以我们将在欧几里得空间中学习到每个类别的更好表示。这个表示很简单,就等于 one-hot 编码与可学习的权重的点积。
嵌入在 NLP 领域有非常广泛的应用,其中每个词都可表示为一个向量。Glove 和 word2vec 是其中两种著名的嵌入方法。我们可以从图 4 看到嵌入的强大之处 [2]。只要这些向量符合你的目标,你随时可以下载和使用它们;这实际上是一种表示它们所包含的信息的好方法。

尽管嵌入可以在不同的语境中使用(不管是监督式方法还是无监督式方法),但我们的主要目标是了解如何为类别变量执行这种映射。
实体嵌入
尽管人们对「实体嵌入」有不同的说法,但它们与我们在词嵌入上看到的用例并没有太大的差异。毕竟,我们只关心我们的分组数据有更高维度的向量表示;这些数据可能是词、每星期的天数、国家等等。这种从词嵌入到元数据嵌入(在我们情况中是类别)的转换使用让 Yoshua Bengio 等人使用一种简单的自动方法就赢得了 2015 年的一场 Kaggle 竞赛——通常这样做是无法赢得比赛的。参阅:https://www.kaggle.com/c/pkdd-15-predict-taxi-service-trajectory-i
「为了处理由客户 ID、出租车 ID、日期和时间信息组成的离散的元数据,我们使用该模型为这些信息中的每种信息联合学习了嵌入。这种方法的灵感来自于自然语言建模方法 [2],其中每个词都映射到了一个固定大小的向量空间(这种向量被称为词嵌入)。[3]

我们将一步步探索如何在神经网络中学习这些特征。定义一个全连接的神经网络,然后将数值变量和类别变量分开处理。
对于每个类别变量:
1. 初始化一个随机的嵌入矩阵 mxD:
- m:类别变量的不同层次(星期一、星期二……)的数量
- D:用于表示的所需的维度,这是一个可以取值 1 到 m-1 的超参数(取 1 就是标签编码,取 m 就是 one-hot 编码)

图 6:嵌入矩阵
2. 然后,对于神经网络中的每一次前向通过,我们都在该嵌入矩阵中查询一次给定的标签(比如为「dow」查询星期一),这会得到一个 1xD 的向量。
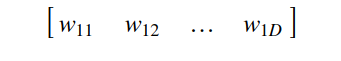
图 7:查找后的嵌入向量
3. 将这个 1×D 的向量附加到我们的输入向量(数值向量)上。你可以把这个过程看作是矩阵增强,其中我们为每一个类别都增加一个嵌入向量,这是通过为每一特定行执行查找而得到的。

4. 在执行反向传播的同时,我们也以梯度的方式来更新这些嵌入向量,以最小化我们的损失函数。
输入一般不会更新,但对嵌入矩阵而言有一种特殊情况,其中我们允许我们的梯度反向流回这些映射的特征,从而优化它们。
我们可以将其看作是一个让类别嵌入在每次迭代后都能进行更好的表示的过程。
注意:根据经验,应该保留没有非常高的基数的类别。因为如果一个变量的某个特定层次占到了 90% 的观察,那么它就是一个没有很好的预测价值的变量,我们可能最好还是避开它。
好消息
通过在我们的嵌入向量中执行查找并允许 requires_grad=True 并且学习它们,我们可以很好地在我们最喜欢的框架(最好是动态框架)中实现上面提到的架构。但 Fast.ai 已经实现了所有这些步骤并且还做了更多。除了使结构化的深度学习更简单,这个库还提供了很多当前最先进的功能,比如差异学习率、SGDR、周期性学习率、学习率查找等等。这些都是我们可以利用的功能。你可以在以下博客进一步了解这些主题:
- https://medium.com/@bushaev/improving-the-way-we-work-with-learning-rate-5e99554f163b
- https://medium.com/@surmenok/estimating-optimal-learning-rate-for-a-deep-neural-network-ce32f2556ce0
- https://medium.com/@markkhoffmann/exploring-stochastic-gradient-descent-with-restarts-sgdr-fa206c38a74e
使用 Fast.ai 实现
在这一部分,我们将介绍如何实现上述步骤并构建一个能更有效处理结构化数据的神经网络。
为此我们要看看一个热门的 Kaggle 竞赛:https://www.kaggle.com/c/mercari-price-suggestion-challenge/。对于实体嵌入来说,这是一个非常合适的例子,因为其数据基本上都是类别数据,而且有相当高的基数(也不是过高),另外也没有太多其它东西。
数据:
约 140 万行
- item_condition_id:商品的情况(基数:5)
- category_name:类别名称(基数:1287)
- brand_name:品牌名称(基数:4809)
- shipping:价格中是否包含运费(基数:2)
重要说明:因为我已经找到了最好的模型参数,所以我不会在这个例子包含验证集,但是你应该使用验证集来调整超参数。
第 1 步:
将缺失值作为一个层次加上去,因为缺失本身也是一个重要信息。
- train.category_name = train.category_name.fillna('missing').astype('category')
- train.brand_name = train.brand_name.fillna('missing').astype('category')
- train.item_condition_id = train.item_condition_id.astype('category')
- test.category_name = test.category_name.fillna('missing').astype('category')
- test.brand_name = test.brand_name.fillna('missing').astype('category')
- test.item_condition_id = test.item_condition_id.astype('category')
第 2 步:
预处理数据,对数值列进行等比例的缩放调整,因为神经网络喜欢归一化的数据。如果你不缩放你的数据,网络就可能格外重点关注一个特征,因为这不过都是点积和梯度。如果我们根据训练统计对训练数据和测试数据都进行缩放,效果会更好,但这应该影响不大。这就像是把每个像素的值都除以 255,一样的道理。
因为我们希望相同的层次有相同的编码,所以我将训练数据和测试数据结合了起来。
- combined_x, combined_y, nas, _ = proc_df(combined, 'price', do_scale=True)
第 3 步:
创建模型数据对象。路径是 Fast.ai 存储模型和激活的地方。
- path = '../data/'
- md = ColumnarModelData.from_data_frame(path, test_idx, combined_x, combined_y, cat_flds=cats, bs= 128
第 4 步:
确定 D(嵌入的维度),cat_sz 是每个类别列的元组 (col_name, cardinality+1) 的列表。
- # We said that D (dimension of embedding) is an hyperparameter
- # But here is Jeremy Howard's rule of thumb
- emb_szs = [(c, min(50, (c+1)//2)) for _,c in cat_sz]
- # [(6, 3), (1312, 50), (5291, 50), (3, 2)]
第 5 步:
创建一个 learner,这是 Fast.ai 库的核心对象。
- params: embedding sizes, number of numerical cols, embedding dropout, output, layer sizes, layer dropouts
- m = md.get_learner(emb_szs, len(combined_x.columns)-len(cats),
第 6 步:
这部分在我前面提及的其它文章中有更加详细的解释。
要充分利用 Fast.ai 的优势。
在损失开始增大之前的某个时候,我们要选择我们的学习率……
- # find best lrm.lr_find()# find best lrm.sched.plot()
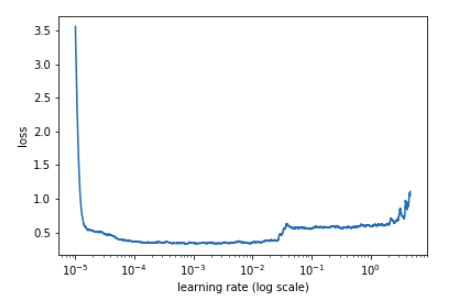
图 9:学习率与损失图
拟合
我们可以看到,仅仅过了 3 epoch,就得到:
- lr = 0.0001m.fit(lr, 3, metrics=[lrmse])
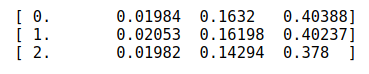
更多拟合
- m.fit(lr, 3, metrics=[lrmse], cycle_len=1)

还有更多……
- m.fit(lr, 2, metrics=[lrmse], cycle_len=1)

所以,在短短几分钟之内,无需进一步的其它操作,这些简单却有效的步骤就能让你进入大约前 10% 的位置。如果你真的有更高的目标,我建议你使用 item_description 列并将其作为多个类别变量使用。然后把工作交给实体嵌入完成,当然不要忘记堆叠和组合。
参考文献
- [1] Cheng Guo, Felix Berkhahn (2016, April, 22) Entity Embeddings of Categorical Variables. Retrieved from https://arxiv.org/abs/1604.06737.
- [2] TensorFlow Tutorials: https://www.tensorflow.org/tutorials/word2vec
- [3] Yoshua Bengio, et al. Artificial Neural Networks Applied to Taxi Destination Prediction. Retrieved from https://arxiv.org/pdf/1508.00021.pdf.




















