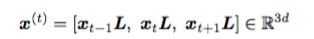自从深度学习被引入语音识别后,误字率迅速下降。不过,虽然你可能读到过一些相关文章,但其实语言识别仍然还没有达到人类水准。语音识别已经有了很多失败的模式。而要将 ASR(自动语音识别)从仅在大部分时间适用于一部分人发展到在任何时候适用于任何人,唯一的方法就是承认这些失败并采取措施解决它们。
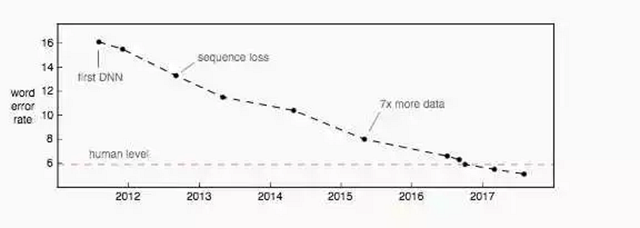
在交换台通话(Switchboard conversational)语音识别标准测试中误字率方面的进展。这个数据集采集于 2000 年,它由四十个电话通话组成,这些通话分别属于随机的两个以英语为母语的人。
仅仅基于交换台通话的结果就声称已经达到人类水准的语音识别,就如同在某个天气晴朗、没有车流的小镇成功测试自动驾驶就声称已经达到人类驾驶水准一样。近期语音识别领域的发展确实非常震撼。但是,关于那些声称达到人类水准的说法就太宽泛了。下面是一些还有待提升的领域。
口音和噪声
语音识别中最明显的一个缺陷就是对口音 [1] 和背景噪声的处理。最直接的原因是大部分的训练数据都是高信噪比、美式口音的英语。比如在交换台通话的训练和测试数据集中只有母语为英语的通话者(大多数为美国人),并且背景噪声很少。
而仅凭训练数据自身是无法解决这个问题的。在许许多多的语言中又拥有着大量的方言和口音,我们不可能针对所有的情况收集到足够的加注数据。单是为美式口音英语构建一个高质量的语音识别器就需要 5000 小时以上的转录音频。
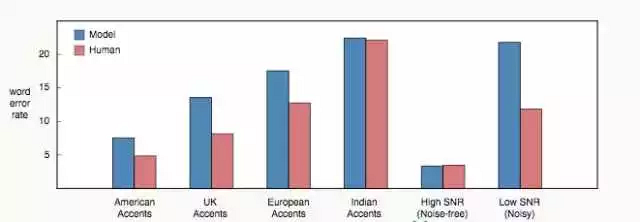
人工转录和百度的 Deep Speech 2 模型在各类语音中的比较 [2] 。注意人工在转录非美式口音时总表现得更差,这可能要归咎于转录员群体中的美国偏见。我更期望为各地区安排本土的转录员,让地区口音的错误率更低。
关于背景噪声,像在移动的汽车中信噪比(SRN)低至 -5dB 的情况并不罕见。在这样的环境中人们并非难以交流,而另一方面,噪声环境中语音识别能力却急速下降。上图中可以看到从高信噪比到低信噪比,人与模型只见的错误率差距急剧扩大。
语义错误
通常语音识别系统的实际目标并不是误字率。我们更关心的是语义错误率,就是被误解的那部分话语。
举个语义错误的例子,比如某人说“let’s meet up Tuesday”,但语音识别预测为“let’s meet up today”。我们也可能在单词错误的情况下保持语义正确,比如语音识别器漏掉了“up”而预测为“let’s meet Tuesday”,这样话语的语义是不变的。
在使用误字率作为指标时必须要小心。举一个最坏的例子,5% 的误字率大概相当于每 20 个单词漏掉 1 个。如果每个语句有 20 个单词(大约是英语语句平均值),那么语句错误率可能高达 100%。希望错误的单词不会改变句子的语义,否则即便只有 5% 的误字率也可能会导致每个句子都被误读。
将模型与人工进行比较时的重点是查找错误的本质,而不仅仅是将误字率作为一个决定性的数字。在我的经历里,人工转录会比语音识别更少产生极端语义错误。
最近微软的研究人员将他们的人工级语音识别器的错误与人类进行了比较 [3]。他们发现的一个差异是该模型比人更频繁地混淆“uh”和“uh huh”。而这两条术语的语义大不相同:“uh”只是个填充词,而“uh huh”是一个反向确认。这个模型和人出现了许多相同类型的错误。
单通道和多人会话
由于每个通话者都由单独的麦克风进行记录,所以交换台通话任务也变得更加简单。在同一个音频流里没有多个通话者的重叠。而另一方面,人类却可以理解有时同时发言的多个会话者。
一个好的会话语音识别器必须能够根据谁在说话对音频进行划分(Diarisation),还应该能弄清重叠的会话(声源分离)。它不只在每个会话者嘴边都有麦克风的情况下可行,进一步才能良好地应对发生在任何地方的会话。
领域变化
口音和背景噪声只是语音识别有待强化的两个方面。这还有一些其他的:
- 来自声环境变化的混响
- 硬件造成的伪影
- 音频的编解码器和压缩伪影
- 采样率
- 会话者的年龄
大多数人甚至都不会注意 mp3 和 wav 文件的区别。但在声称达到人类水准的性能之前,语音识别还需要进一步增强对文件来源多样化的处理。
上下文
你会注意到像交换台这样人类水准误字率的基准实际上是非常高的。如果你在跟一个朋友交流时,他每 20 个单词就误解其中一个,沟通会很艰难。
一个原因在于这样的评估是上下文无关的。而实际生活中我们会使用许多其他的线索来辅助理解别人在说什么。列举几个人类使用上下文而语音识别器没有的情况:
- 历史会话和讨论过的话题
- 说话人的视觉暗示,包括面部表情和嘴唇动作
- 关于会话者的先验知识
目前,Android 的语音识别器已经掌握了你的联系人列表,它能识别出你朋友的名字 [4]。地图产品的语音搜索则通过地理定位缩小你想要导航的兴趣点范围 [5]。
当加入这些信号时,ASR 系统肯定会有所提高。不过,关于可用的上下文类型以及如何使用它,我们才刚刚触及皮毛。
部署
在会话语音方面的最新进展都还不能展开部署。如果要解决新语音算法的部署,需要考虑延迟和计算量这两个方面。这两者之间是有关联的,算法计算量的增加通常都导致延迟增加。不过简单起见,我将它们分开讨论。
延迟:关于延迟,这里我指的是用户说完到转录完成的时间。低延迟是 ASR 中一个普遍的产品约束,它明显影响到用户体验。对于 ASR 系统来说,10 毫秒的延迟要求并不少见。这听起来可能有点极端,但是请记住文字转录通常只是一系列复杂计算的第一步。例如在语音搜索中,实际的网络搜索只能在语音识别之后进行。
一个关于延迟方面难以改进的例子是双向循环层。当前所有最先进的会话语音识别都在使用它。其问题在于我们无法在第一层计算任何东西,而必须要等到用户说完。所以这里的延迟跟话语时长有关。
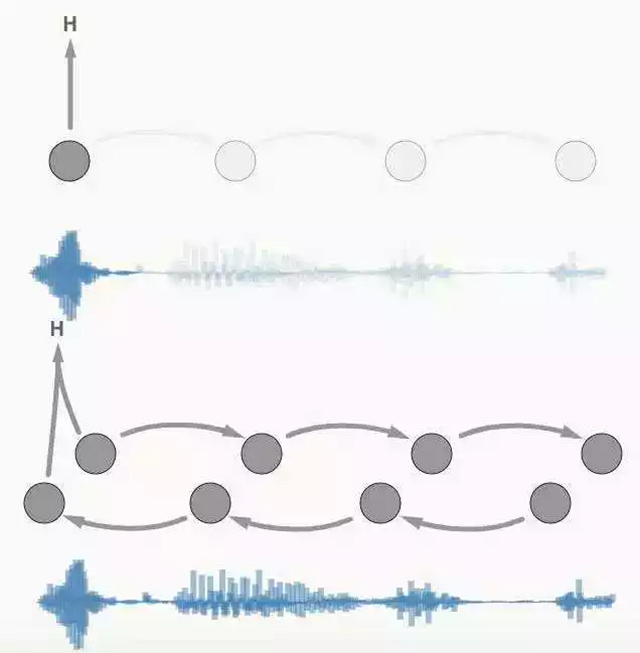
上图:只有一个前向循环,可以在转录时进行计算。
下图:在双向循环的情况下,必须要等待全部话语说完才能计算转录。
在语音识别中如何有效结合未来信息仍然是一个开放问题。
计算:转录语音所需的计算能力是一个经济约束。我们必须考虑语音识别器每次精度改进的性价比。如果改进达不到一个经济门槛,那它就无法部署。
一个从未部署的持续改进的典型案例就是集成。1% 或者 2% 的误差减少很少值得 2-8 倍的计算量增长。新一代 RNN 语言模型也属于这一类,因为它们用在束搜索时代价昂贵,不过预计未来会有所改变。
需要说明的是,我并不认为研究如何在巨大计算成本上提高精度是无用的。我们已经看到过“先慢而准,然后提速”模式的成功。要提的一点是在改进到足够快之前,它还是不可用的。
未来五年
语音识别领域仍然存在许多开放性和挑战性的问题:
- 在新地区、口音、远场和低信噪比语音方面的能力扩展
- 在识别过程中引入更多的上下文
- Diarisation 和声源分离
- 评价语音识别的语义错误率和创新方法
- 超低延迟和高效推理
我期待着今后 5 年在以上以及其他方面取得的进展。