【51CTO.com原创稿件】11 月 18 日,北京西红门镇新建二村“聚福缘公寓”突发火灾。火灾后,随之而来的是一场全北京市的“安全隐患大排查大清理大整治”风暴。
聚集着几万外来务工人员的新建村在几天之内被清理一空。很多人正面临着要重新找房子或是离开北京的问题。
违建的公寓正在消失,危房出租正在被拆,这些被“风暴”涉及到的外来上班族怎么办?只有接受现实,勇敢面对。
为了生存,为了能留在帝都,为了改变人生、出人头地,再贵的房子他们都要租,或者他们可以再寻找一处稍远点的房子。
租房的烦恼,相信大家或多或少都有过。独自一人在大都市打拼,找个温暖的小窝实属不易,租个称心又价格公道的房子是件重要的事儿。
站在技术人的角度,今天我就如何从各大租房网的房源里面,找到最称心如意的小窝做些分享,供大家参考。
在找房子的过程中我们最关心是价格和通勤距离这两个因素。关于价格方面,现在很多租房网站都有,但是这些租房网站上没有关于通勤距离的衡量。
对于我这种对帝都不是很熟的人,对各个区域的位置更是一脸懵逼。所以我就想着能不能自己计算距离呢,后来查了查还真可以。
实现思路就是:先抓取房源信息,然后获取房源的经纬度,***根据经纬度计算公司与具体房源之间的距离。
我们在获取经纬度之前,首先需要获取各个出租房所在地的名称,这里获取的方法是用爬虫爬取链家网上的信息。
Xpath 介绍
在爬取链家网的信息的时候用的是 Xpath 库,这里对 Xpath 库做一个简单的介绍。
Xpath 是什么
Xpath 是一门在 XML 文档中查找信息的语言。Xpath 可用来在 XML 文档中对元素和属性进行遍历。
Xpath 在查找信息的时候,需要先对 requests.get() 得到的内容进行解析,这里是用 lxml 库中的 etree.HTML(html) 进行解析得到一个对象 dom_tree,然后利用 dom_tree.Xpath() 方法获取对应的信息。
Xpath 怎么用
Xpath 最常用的几个符号就是“/”、“//”这两个符号,“/”表示该标签的直接子节点,就比如说一个人的众多子女,而“//”表示该标签的后代,就比如说是一个人的众多后代(包括儿女、外甥、孙子之类的辈分)。

更多详细内容这里就不 Ctrl C/V了。
数据抓取
我们本次抓取数据的流程是先获得目标网页 url,然后利用 requests.get() 获得 html,然后再利用 lxml 库中的 etree.HTML(html) 进行解析得到一个对象 dom_tree,然后利用 dom_tree.Xpath() 方法获取对应的信息。
先分析目标网页 url 的构造,链家网的 url 构造还是很简单的,页码就是 pg 后面的数字,在租房这个栏目下一共有 100 页,所以我们循环 100 次就好啦。
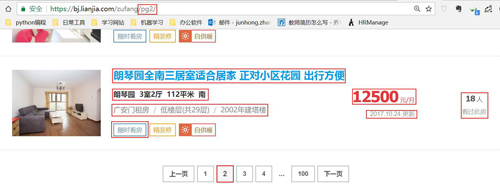
还有就是明确我们要获取的信息,在前面我们说了目标是要研究公司附近的出租房信息,但是我们在租房的时候也不是仅仅考虑距离这一个因素。
这里我准备获取标题、价格、区域(大概在哪一块)、看房人数(说明该房的受欢迎程度),楼层情况(高楼层还是低楼层),房租建筑时间等等。(就是你能看到的信息差不多都要弄下来哈哈)。
开始代码部分:
- #导入相关库
- from lxml import etree
- import requests
- from requests.exceptions import ConnectionError
- import pandas as pd
- #获取目标网页的url
- def get_page_index():
- base="https://bj.lianjia.com/zufang/pg"
- for i in range(1,101,1):
- url=base+str(i)+"/"
- yield url#yield为列表生成器
得到目标网页的 url 后,对其进行解析,采用的方法是先用 lxml 库的 etree 对 response 部分进行解析,然后利用 Xpath 进行信息获取。
- #请求目标网页,得到response
- def get_page_detail(url):
- try:
- response=requests.get(url)
- if response.status_code==200:
- return etree.HTML(response.content.decode("utf-8"))
- #lxml.etree.HTML处理网页源代码会默认修改编码
- return None
- except ConnectionError:
- print ("Error occured")
- return None
- #解析目标网页
- #title为房屋标题;name为小区名称;catogery为房屋类别(几室几厅)
- #size为房屋大小;region为区域;PV为看房人数;
- #second_feature为高低楼层;third_feature为房屋建筑时间
- def parse_page_detail(dom_tree):
- try:
- title=dom_tree.xpath('//li/div[2]/h2/a/text()')
- name=dom_tree.xpath('//li/div[2]//div/a/span/text()')
- catogery=dom_tree.xpath('//li/div[2]//div//span[1]//span/text()')
- size=dom_tree.xpath('//li/div[2]//div//span[2]/text()')
- region=dom_tree.xpath('//li/div[2]//div[1]//div[2]//div/a/text()')
- PV=dom_tree.xpath("//li/div[2]//div[3]//span[@class='num']/text()")
- price=dom_tree.xpath("//li/div[2]//div[2]//span[@class='num']/text()")
- date=dom_tree.xpath("//li/div[2]//div[2]//div[@class='price-pre']/text()")
- first_feature=dom_tree.xpath('//li/div[2]//div[1]//div[3]//span[@class="fang-subway-ex"]/span/text()')
- other=dom_tree.xpath('//li/div[2]//div[1]//div[2]//div/text()')
- name1=[]
- catogery1=[]
- size1=[]
- second_feature=[]
- third_feature=[]
- for n in name:
- name2=n[0:-2]
- name1.append(name2)
- for c in catogery:
- catogery2=c[0:-2]
- catogery1.append(catogery2)
- for s in range(0,59,2):
- size2=size[s][0:-2]
- size1.append(size2)
- second_feature1=other[s]
- second_feature.append(second_feature1)
- for m in range(1,60,2):
- third_feature1=other[m]
- third_feature.append(third_feature1)
- return {
- "title":title,
- "name":name1,
- "catogery":catogery1,
- "size":size1,
- "region":region,
- "price":price,
- "PV":PV,
- "second_feature":second_feature,
- "third_feature":third_feature,
- "other":other
- }
- except:
- pass
- #对获得目标内容进行整理导出
- #建立一个空的DataFrame
- df1=pd.DataFrame(columns=["title","name","catogery", "size","region","price","PV",
- "second_feature","third_feature","other" ])
- i=0
- if __name__=="__main__":
- urls=get_page_index()
- for url in urls:
- dom_tree=get_page_detail(url)
- result=parse_page_detail(dom_tree)
- df2=pd.DataFrame(result)
- df1=df1.append(df2,ignore_index=False,verify_integrity=False)
- i=i+1
- print(i) #打印出目前爬取的页数
- #保存数据到本地
- df1.to_csv("D:\\Data-Science\\Exercisedata\\lianjia\\result.csv")
- df1.info#打印出爬虫结果的基本信息

通过上图可以看出,我们一共抓取到 2970 条房屋信息,9columns。
- df1.head(3)#预览前3行

经纬度的获取
我们刚刚只是获取了一些出租房的基本信息,但是我们要想计算距离还需要获得这些出租房所在的地理位置,即经纬度信息。
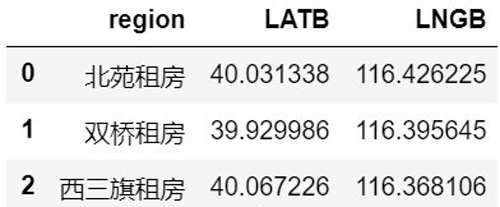
这里的经纬度是获取的区域层级的,即大概属于哪一个片区,本次爬取的 2970 条房屋信息分布在北京的 208 个区域/区域。
关于如何获取对应地点的经纬度信息,这里利用的 XGeocoding_v2 工具:
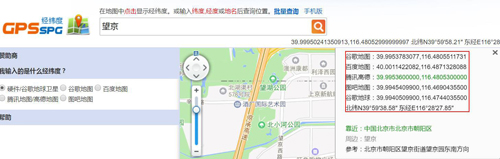
获取经纬度信息的地址如下:http://www.gpsspg.com/maps.htm
得到如下的结果(LATB 表示维度,LNGB 表示经度):
距离的计算
- #经纬度的计算函数
- # input Lat_A 纬度A
- # input Lng_A 经度A
- # input Lat_B 纬度B
- # input Lng_B 经度B
- # output distance 距离(km)
- def calcDistance(Lat_A, Lng_A, Lat_B, Lng_B):
- ra = 6378.140 # 赤道半径 (km)
- rb = 6356.755 # 极半径 (km)
- flatten = (ra - rb) / ra # 地球扁率
- rad_lat_A = radians(Lat_A)
- rad_lng_A = radians(Lng_A)
- rad_lat_B = radians(Lat_B)
- rad_lng_B = radians(Lng_B)
- pA = atan(rb / ra * tan(rad_lat_A))
- pB = atan(rb / ra * tan(rad_lat_B))
- xx = acos(sin(pA) * sin(pB) + cos(pA) * cos(pB) * cos(rad_lng_A - rad_lng_B))
- c1 = (sin(xx) - xx) * (sin(pA) + sin(pB)) ** 2 / cos(xx / 2) ** 2
- c2 = (sin(xx) + xx) * (sin(pA) - sin(pB)) ** 2 / sin(xx / 2) ** 2
- dr = flatten / 8 * (c1 - c2)
- distance = ra * (xx + dr)
- return distance
- #具体的计算
- #Lat_A,Lng_A为你公司地址,这里以望京为例,
- #你可以输入你公司所在地
- Lat_A=40.0011422082; Lng_A=116.4871328088
- Distance0=[]#用于存放各个区域到公司的距离
- region=[]
- for r in range(0,208,1):
- Lat_B=df3.loc[r][1];Lng_B=df3.loc[r][2]
- distance=calcDistance(Lat_A, Lng_A, Lat_B, Lng_B)
- Distance1='{0:10.3f} km'.format(distance)
- region0=df3.loc[r][0]
- Distance0.append(Distance1);region.append(region0)
- date={"region":region,"Distance":Distance0}
- Distance_result=pd.DataFrame(date,columns=["region","Distance"])
***将距离以及区域与对应的小区拼接在一起,得到下面的结果。

进一步分析
- #导入相关库
- % matplotlib inline
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt
- plt.style.use("ggplot")
- #导入合并后的文件
- df=pd.read_csv("D:\\Data-Science\\Exercisedata\\lianjia\\lianjia-rental.csv",encoding="gbk",index_col="name")
- df.head()
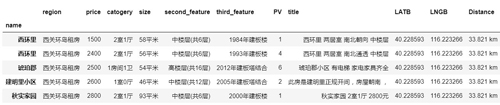
- df.info()
通过 df.info() 可以看出,总共有 2454 条数据,这是在爬虫获取的 2970 条数据去重以后得到的。

在这些项中,size(房屋面积)、second_feature 以及 third_feature 均带有单位,为了后续分析方便,这里统一进行去单位(后缀)操作。
- df["size"]=[i[0:-2] for i in df["size"]]
- df["Distance"]=[i[0:-2] for i in df["Distance"]]
- df["second_feature"]=[i[0:3] for i in df["second_feature"]]
- df["third_feature"]=[i[0:4] for i in df["third_feature"]]
- df.head()
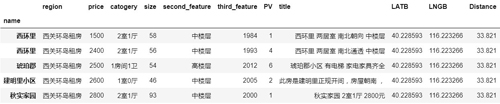
- df.info()
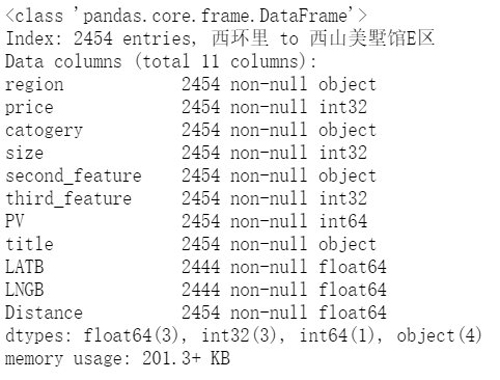
我们把后缀去掉了,Size、third_feature 和 Distance 看上去是数字,但是通过 df.info() 看出,这两个指标类型依然是 Object。为了进一步分析,我们要对它们继续进行处理。
- df["size"]=df["size"].astype(np.int32)
- df["Distance"]=df["Distance"].astype(np.float64)
- df["price"]=df["price"].astype(np.int32)
- df["third_feature"]=df["third_feature"].astype(np.int32)
- df.info()
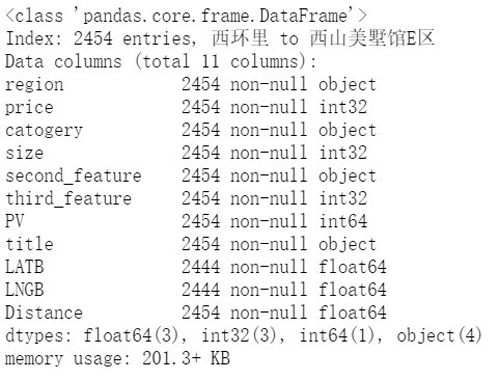
再次通过 df.info() 看出,该是数字类型的指标全部变成了 int/float 了,可以进行下一步了。
在文章刚开头就说过,一般租房最看重的两个因素就是距离&价格,价格可以直接在那些租房网上看到,肯定是越低越好,没啥好说的。
主要是距离,关于距离,有两种选择方式,一种是先选出离你上班地最近的几个区域,然后再在该区域内具体选择;另一个是可以设定你可以接受的通勤距离,然后以这个距离作为条件,在小于等于这个距离内进行筛选。
我们这里着重以***种为主,先选择距离最近的几个区域,然后在这几个区域内进行选择。
因为距离是按 Region 来进行计算的,而表是按 Name 来统计的,所以要想计算出距离最近的 Region,需要先把 Region 和 Distance 部分提取出来,并合并成一个 DataFrame。
- region=list(df.region)
- Distance=list(df.Distance)
- Distance_result_data={"region":region,"Distance":Distance}
- Distance_result=pd.DataFrame(Distance_result_data)
- Distance_result1=Distance_result.drop_duplicates()
- Distance_result1.head()

- #距离最近的Top10区域
- Distance_result1.sort_values(by="Distance").head(10)
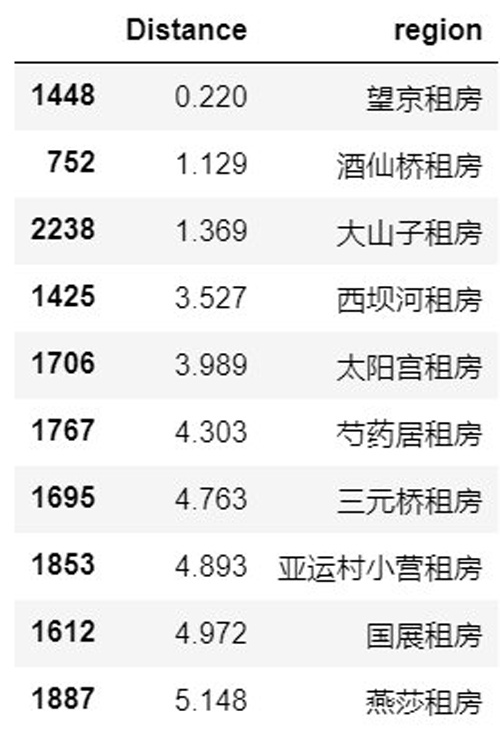
- #对位置进行可视化
- top_region=Distance_result1.sort_values(by="Distance").head(10).region
- top_Distance=Distance_result1.sort_values(by="Distance").head(10).Distance
- #绘制雷达图
- labels = np.array(top_region)#标签
- dataLenth = 10#数据个数
- data = np.array(top_Distance)#数据
- angles = np.linspace(0, 2*np.pi, dataLenth, endpoint=False)
- data = np.concatenate((data, [data[0]])) # 闭合
- angles = np.concatenate((angles, [angles[0]])) # 闭合
- fig = plt.figure()
- ax = fig.add_subplot(111, polar=True)# polar参数!!
- ax.plot(angles, data, 'ro-', linewidth=2)# 画线
- #ax.fill(angles, data, facecolor='r', alpha=0.25)# 填充
- ax.set_thetagrids(angles * 180/np.pi, labels, fontproperties="SimHei")
- ax.set_title("距离望京最近的十个区域", va='bottom', fontproperties="SimHei")
- ax.set_rlim(0,6)
- ax.grid(True)
- plt.show()
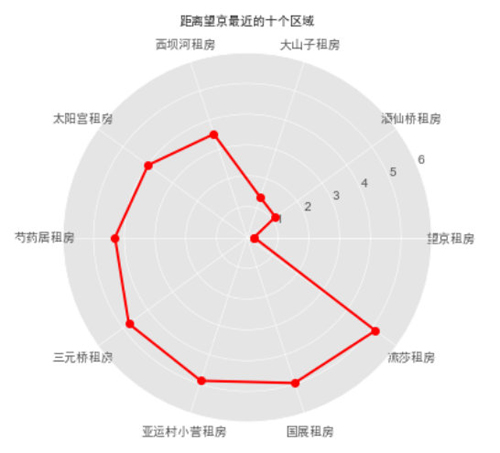
可以看到,Region=“望京”距离最近,所以我们重点在该区域内选择,接下来具体看看该区域内租房情况。
- Top1=df[df.region=="望京租房"]#将望京的租房信息筛选出来
- Top1.info()

通过上表可以看到在望京区域总共有 101 套房源,接下来对这 101 套房源进行深入分析。
- plt.subplot(131)
- ax1=Top1.boxplot("price")
- ax1.set_ylim(0,90000)
- plt.subplot(132)
- ax2=Top1.boxplot("size")
- ax2.set_ylim(0,270)
- plt.subplot(133)
- ax3=Top1.boxplot("PV")
- ax3.set_ylim(-5,100)
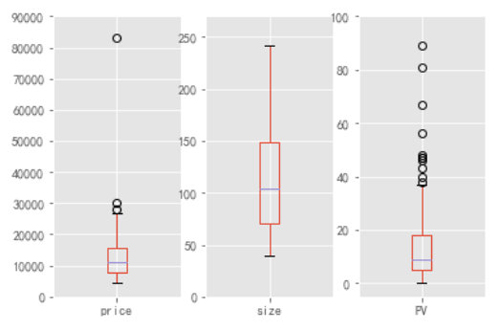
数据概览,先对该区域的租房整体情况有个认识,看到 Price 指标的下界为 5000 左右,上界接近于 30000,中位数为 10000 出头(有没有感觉到好贵哈哈哈哈),但是我们也看到有一个大于 80000 的超级异常值,我们利用截尾均值对他进行替代。
关于房屋大小,中位数为 100 平,这与 Price 中位数正好可以对应,折算下来相当于 1 平 100 大洋,在与那些 10 平左右的合租房需要 2000+ 大洋比一比,是不是觉得还是 100 平 10000 大洋便宜哈。
所以论一平米的价格的话还是整租更便宜。
先找出那个大于 80000 的异常值具体值是多少,然后进行值替换。
- Top1[Top1.price>80000]#通过图表可以看出,异常值是大于80000,但是看不到具体是多少
![]()
- #值替换
- from scipy import stats
- Top1.price.replace(83000,stats.trim_mean(Top1.price,0.1),inplace=True)
- Top1.boxplot("price")
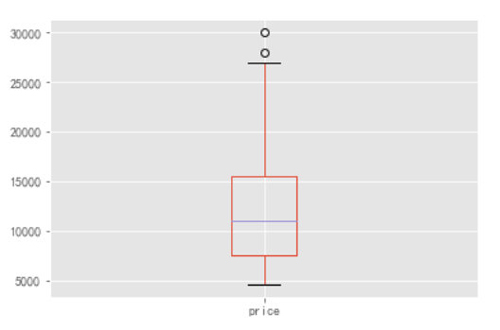
这是将 Price 异常值处理以后得到的箱型图,看起来就比较规范了哈。
- plt.rcParams["font.sans-serif"]='SimHei'
- plt.subplot(311)
- grouped=Top1.groupby("second_feature")["price"]
- ax4=grouped.count().plot.bar()
- plt.subplot(312)
- grouped2=Top1.groupby("third_feature")["price"]
- ax5=grouped2.count().plot.bar()
- plt.subplot(313)
- grouped3=Top1.groupby("catogery")["price"]
- ax6=grouped3.count().plot.bar()
- plt.tight_layout()
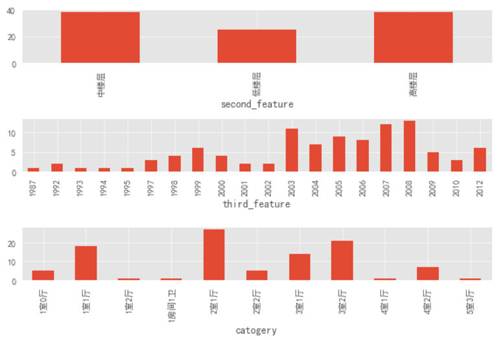
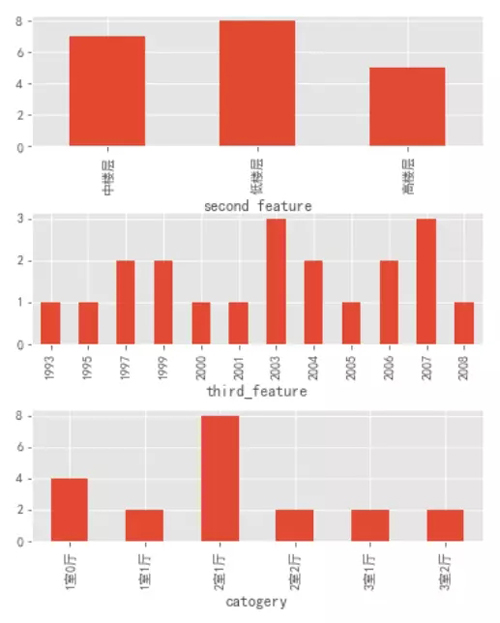
通过上图可以看出:中楼层和高楼层的房源绝对数量基本持平,高出低楼层数量一半。
房屋修建时间也是 2003 年以后的居多,这就和前面的楼层类型可以对应上了,在刚开始的时候(2003 年以前)大部分房子都是低楼层,随着时代的进步,科技的发展,人员的增多,楼层的数量和房屋的数量也随之增加。
房屋类型上的 Top3 类型分别为:2 室 1 厅、3 室 2 厅和 1 室 1 厅。
- #房屋修建时间与价格的散点图
- Top1.plot.scatter(x="third_feature",y="price")
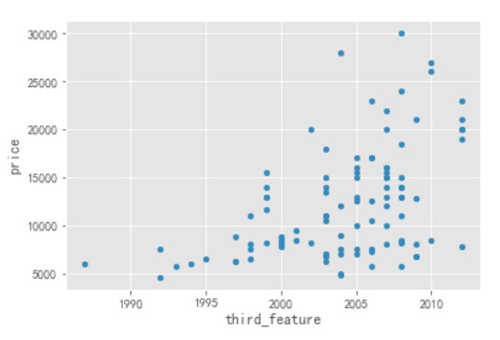
通过上图可以看出,随着时间的推移,2003 年以后的房子的 Price 要明显高于 2003 年以前的,如果要是对价格比较敏感,可以考虑 2003 年以前的房子。
- Top1.boxplot(column=["price"],by="catogery")
- plt.tight_layout()
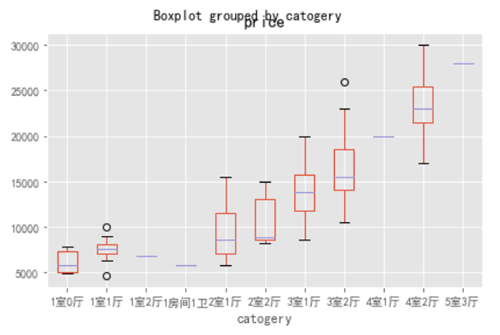
随着房屋类型的升级,价格也是随之升高,但是我们也发现,有一些三室房子的价格(下边界)要低于两室的价格的,如果对房间数量和价格都有要求的可以考虑这部分房源。
- Top1.boxplot(column=["price"],by="second_feature")
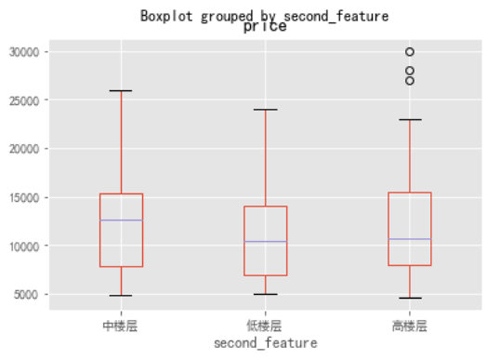
通过上图可以看到三个楼层的价格下界基本持平,但是中楼层的中位数和上界价格是要明显高于其他两个房型的,这也很正常,中楼层相比于其他两个楼层的房屋是最宜居的啦,价格贵也正常。
当然了,对于现在租房都很困难的环境下,哪还考虑什么宜居,当然是挑价格低的房型。
- Top1_PV=Top1.sort_values(by="PV",ascending=False).head(20)
- Top1_PV.head()
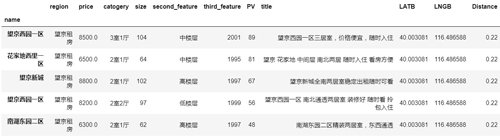
按 PV 进行降序,我们可以看出哪些房源是比较受欢迎,这些房源都有啥特征。
- plt.rcParams["font.sans-serif"]='SimHei'
- plt.subplot(311)
- grouped4=Top1_PV.groupby("second_feature")["price"]
- ax7=grouped4.count().plot.bar()
- plt.subplot(312)
- grouped5=Top1_PV.groupby("third_feature")["price"]
- ax8=grouped5.count().plot.bar()
- plt.subplot(313)
- grouped6=Top1_PV.groupby("catogery")["price"]
- ax9=grouped6.count().plot.bar()
- plt.subplots_adjust(left=0.2,right=1.0,top=1.6,bottom=0.2,hspace=0.5)
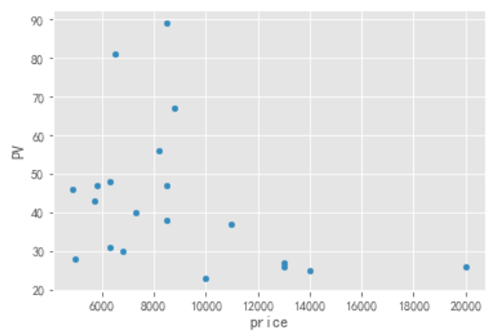
- Top1_PV.plot.scatter(y="PV",x="price")
从图中可以看到,低楼层的房源数量不是最多的,但是看房次数却是最多的(***的),可能是低楼层价格低的原因吧。
2003 年和 2007 的房源 PV ***,这和该年代的房源绝对数量基本维持一致;两室一厅的户型最为火爆;在价格方面 10000 以下的房源比较受欢迎。
- Top1_PV.plot.scatter(y="PV",x="price")
结论
通过上面的分析我们可以得出一些参考:
- 2003 年以前的房源的价格是要低于 2003 年之后的,对价格敏感的可以考虑 2003 年以前的房源。
- 有一些三室的房子价格是低于两室的,如果对房间数量和价格都有要求的可以考虑这部分。
- 中楼层的价格整体上是要高于低楼层的,但是还有一部分是要比低楼层低,而且通过从 PV ***的楼层来看,低楼层的火爆程度要比中楼层高,所以可以寻找那些不那么火爆但是价格还低的中楼层。
- 如果希望单位面积价格***,还是整租比较合适。
注:本次的数据为链家网的整租房源信息,非合租信息,所以你会看到价格都很高。
张俊红,中国统计网专栏作者,个人公众号ID:zhangjunhong0428,数据分析路上的学习者与实践者,与你分享我的所见、所学、所想。

【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】