前言
本篇博文将详细讲解LDA主题模型,从***层数学推导的角度来详细讲解,只想了解LDA的读者,可以只看***小节简介即可。因为PLSA和LDA非常相似,PLSA也是主题模型方面非常重要的一个模型,本篇也会有的放矢的讲解此模型。如果读者阅读起来比较吃力,可以定义一个菲波那切数列,第 f(n) = f(n-1) + f(n-2) 天再阅读一次,直到这个知识点收敛。如果读者发现文章中的错误或者有改进之处,欢迎交流。
1. 简介
在机器学习领域,LDA是两个常用模型的简称:Linear Discriminant Analysis 和 Latent Dirichlet Allocation。本文的LDA仅指代Latent Dirichlet Allocation. LDA 在主题模型中占有非常重要的地位,常用来做文本分类。
LDA由Blei, David M.、Ng, Andrew Y.、Jordan于2003年提出,用来推测文档的主题分布。它可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题分布后,便可以根据主题分布进行主题聚类或文本分类。
2. 先验知识
LDA 模型涉及很多数学知识,这也许是LDA晦涩难懂的主要原因。本小节主要介绍LDA中涉及的数学知识。数学功底比较好的同学可以直接跳过本小节。
LDA涉及到的先验知识有:二项分布、Gamma函数、Beta分布、多项分布、Dirichlet分布、马尔科夫链、MCMC、Gibs Sampling、EM算法等。限于篇幅,本文仅会有的放矢的介绍部分概念,不会每个概念都仔细介绍,亦不会涉及到每个概念的数学公式推导。如果每个概念都详细介绍,估计都可以写一本百页的书了。如果你对LDA的理解能达到如数家珍、信手拈来的程度,那么恭喜你已经掌握了从事机器学习方面的扎实数学基础。想进一步了解底层的数学公式推导过程,可以参考《数学全书》等资料。




















3.2 PLSA模型
Unigram Model模型中,没有考虑主题词这个概念。我们人写文章时,写的文章都是关于某一个主题的,不是满天胡乱的写,比如一个财经记者写一篇报道,那么这篇文章大部分都是关于财经主题的,当然,也有很少一部分词汇会涉及到其他主题。所以,PLSA认为一篇文档的生成过程如下:
- 1. 现有两种类型的骰子,一种是doc-topic骰子,每个doc-topic骰子有K个面,每个面一个topic的编号;一种是topic-word骰子,每个topic-word骰子有V个面,每个面对应一个词;
- 2. 现有K个topic-word骰子,每个骰子有一个编号,编号从1到K;
- 3. 生成每篇文档之前,先为这篇文章制造一个特定的doc-topic骰子,重复如下过程生成文档中的词:
- 3.1 投掷这个doc-topic骰子,得到一个topic编号z;
- 3.2 选择K个topic-word骰子中编号为z的那个,投掷这个骰子,得到一个词。



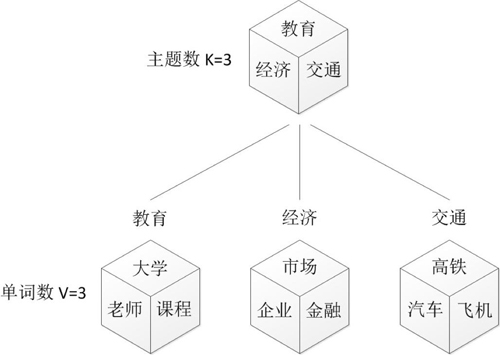
上图中有三个主题,在PLSA中,我们会以固定的概率来抽取一个主题词,比如0.5的概率抽取教育这个主题词,然后根据抽取出来的主题词,找其对应的词分布,再根据词分布,抽取一个词汇。由此,可以看出PLSA中,主题分布和词分布都是唯一确定的。但是,在LDA中,主题分布和词分布是不确定的,LDA的作者们采用的是贝叶斯派的思想,认为它们应该服从一个分布,主题分布和词分布都是多项式分布,因为多项式分布和狄利克雷分布是共轭结构,在LDA中主题分布和词分布使用了Dirichlet分布作为它们的共轭先验分布。所以,也就有了一句广为流传的话 -- LDA 就是 PLSA 的贝叶斯化版本。下面两张图片很好的体现了两者的区别:
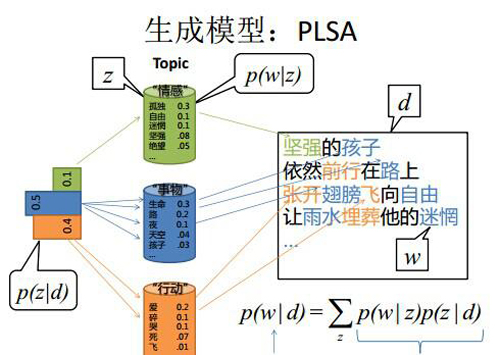
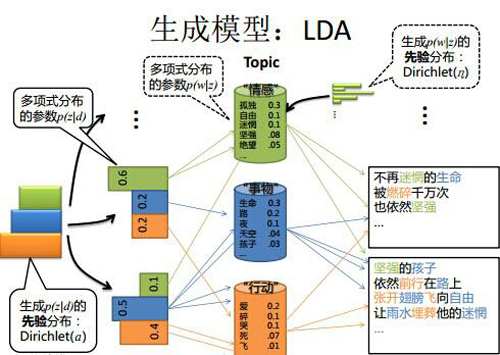
在PLSA和LDA的两篇论文中,使用了下面的图片来解释模型,它们也很好的对比了PLSA和LDA的不同之处。
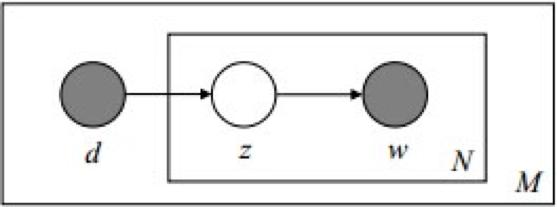
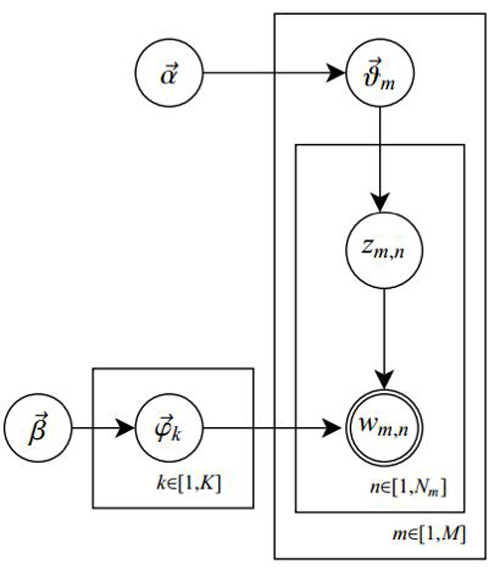








3.3.6 LDA Inference
有了 LDA 的模型,对于新来的文档 doc,我们只要认为 Gibbs Sampling 公式中的 部分是稳定不变的,是由训练语料得到的模型提供的。所以采样过程中,我们只要估计该文档的 topic 分布就好了。具体算法如下:
- 1. 对当前文档中的每个单词, 随机初始化一个topic编号z;
- 2. 使用Gibbs Sampling公式,对每个词,重新采样其topic;
- 3. 重复以上过程,知道Gibbs Sampling收敛;
- 4. 统计文档中的topic分布,该分布就是。
4 Tips
懂 LDA 的面试官通常会询问求职者,LDA 中主题数目如何确定?
在 LDA 中,主题的数目没有一个固定的***解。模型训练时,需要事先设置主题数,训练人员需要根据训练出来的结果,手动调参,优化主题数目,进而优化文本分类结果。
5 后记
LDA 有非常广泛的应用,深层次的懂 LDA 对模型的调优,乃至提出新的模型 以及对AI技能的进阶有巨大帮助。只是了解 LDA 能用来干什么,只能忽悠小白。
百度开源了其 LDA 模型,有兴趣的读者可以阅读:https://github.com/baidu/Familia/wiki
References
[1]: Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. Journal of machine Learning research, 3(Jan), 993-1022.
[2]: Hofmann, T. (1999). Probabilistic latent semantic indexing. In Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval (pp. 50-57). ACM.
[3]: Li, F., Huang, M., & Zhu, X. (2010). Sentiment Analysis with Global Topics and Local Dependency. In AAAI (Vol. 10, pp. 1371-1376).
[4]: Medhat, W., Hassan, A., & Korashy, H. (2014). Sentiment analysis algorithms and applications: A survey. Ain Shams Engineering Journal, 5(4), 1093-1113.
[5]: Rick, Jin. (2014). Retrieved from http://www.flickering.cn/数学之美/2014/06/【lda数学八卦】神奇的gamma函数/.
[6]: 通俗理解LDA主题模型. (2014). Retrieved from http://blog.csdn.net/v_july_v/article/details/41209515.
[7]: 志华, 周. (2017). 机器学习. 北京, 北京: 清华大学出版社.
[8]: Goodfellow, I., Bengio, Y., & Courville, A. (2017). Deep learning. Cambridge, MA: The MIT Press.
[9]: 航, 李. (2016). 统计学习方法. 北京, 北京: 清华大学出版社.
作者:达观数据NLP组—夏琦,微信号:Datagrand
【本文为51CTO专栏作者“达观数据”的原创稿件,转载可通过51CTO专栏获取联系】