随着业务越来越复杂,数据量越来越大,并发量越来越大,数据库的性能越来越低。好不容易找运维申请了两台机器,让DBA部署了几个实例,想把一些业务库拆分出来,却发现拆不出来,扩不了容,尴尬!
因为数据库强关联在一起,无法通过增加数据库实例扩容,就是一个耦合的典型案例。
场景还原
有一个公共用户数据库DB_USER,里面table_user存放了通用的用户数据:
- table_user (uid, name, passwd, …)
在数据量比较小,并发量比较小,业务还没有这么复杂的时候,为了提高资源利用率(程序员才没有考虑什么资源利用率,更多的是图方便),业务A把用户个性化的数据也放在这个库里:
- table_A(uid, A业务的个性化属性)
业务A有一个需求,即要展现用户公共属性,又要展现业务A个性化属性,程序员经常这么实现的:
- select * from table_user, table_A
- where table_user.uid = table_A.uid
- and table_user.uid = $uid
初期关联查询没有任何问题,单条记录访问,***索引,一次查询所有数据,简单高效。
如何产生各业务数据耦合?
通过join实现业务,导致通用表table_user和业务表table_A必须存在于一个数据库实例里。
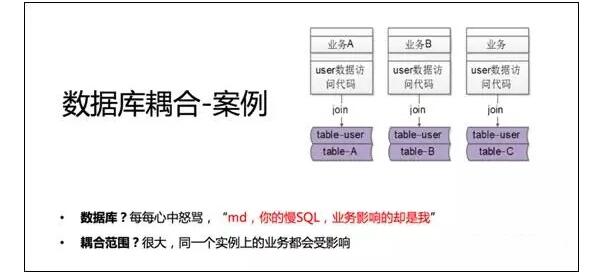
如果业务B也这么做,业务C也这么做,会导致公用业务,业务A,业务B,业务C都必须存在于一个数据库实例里。
会产生什么潜在问题呢?
假如A业务线上线了一个新功能,不小心进行了全表扫描,导致数据库CPU100%,数据库实例性能下降,由于实例共用,通用业务,业务B和业务C都会受影响。
即某个业务线的数据库性能急剧下降导致所有业务都受影响,这种耦合,历史总是惊人的相似:
- 业务B的大boss在群里首先发飙:“技术都干啥了,怎么系统挂了”
- 业务B的rd一脸无辜:“业务A上线了,所以我们挂了”
- 额,然而,这个理由,好像在大boss那解释不通…
- 业务B的大boss:“赶紧加几台机器,拆分开”
- 业务B的rd一脸无奈:“加机器加实例也扩容不了”
- 业务B的大boss对业务2的rd吼道“还想甩锅,拖出去祭天”
- ...
唉,加了几台机器,加了几个实例,然而并没有什么卵用,都耦合在一个实例里,完全扩不了容。
那,如何解除公共数据库与业务数据库的耦合?
***步:公共数据访问下沉服务化

还是上面的例子,当公共的user数据访问服务化之后,依据服务化的原则:
- 业务层只能通过服务RPC接口访问数据
- 底层user库属于user服务私有
- 任何上游不允许跨过服务访问底层的user库
第二步:垂直拆分,个性化数据访问上浮
原来业务方:
- 通过join一次性获取通用的数据和个性化的业务数据数据
- 服务化+垂直拆分后,变成两次访问:
- 一次取得业务数据(业务可以直接调用自己的数据库,也可以自己做业务服务调用RPC接口)
- 一次取得共性数据(调用通用的RPC接口)
两种方式相比:
- 之前的方式其实业务代码可能会更简单一些,因为它是将这个业务逻辑放在了SQL语句中,但是导致数据库耦合在了一起
- 后面这种方式就是业务的代码会更复杂,会变成多次访问,将原来在SQL中进行的逻辑计算变成业务代码中的逻辑计算,但是数据库解耦了
业务复杂,数据量大,并发老大,对扩展性要求更高的架构,一定是后者。
此时各业务有自己的库,公共有公共的库:
- 早期:可以放在一个数据库实例里
- 后期:可以很容易地通过新增数据库实例,把user库或者业务A/B/C的库拆分出来,实现增加机器增加实例就实现扩容
个性业务数据访问垂直拆分,共性数据访问服务化下沉,只是一个很小的优化点,但对于数据库解耦却是非常的有效。
【本文为51CTO专栏作者“58沈剑”原创稿件,转载请联系原作者】