自从 Apache Spark 2009 年在 U.C. Berkeley 的 AMPLab 默默诞生以来,它已经成为这个世界上最重要的分布式大数据框架之一。Spark 可以用多种方式部署,它为 Java、Scala、Python,和 R 编程语言提供了本地绑定,并且支持 SQL、流数据、机器学习,和图处理。你将会发现它被银行、电信公司、游戏公司、政府,和所有如 Apple、Facebook、IBM,和 Microsoft 等主要的科技巨头公司使用。

非常好,Spark 可以运行在一个只需要在你集群中的每台机器上安装 Apache Spark 框架和 JVM 的独立集群模式。然而,你将更有可能做的是,希望利用资源或集群管理系统来帮你按需分配工作。 在企业中,这通常意味着在 Hadoop YARN (这是 Cloudera 和 Hortonworks 分配运行 Spark 任务的方式 )上运行。尽管 work 是在增加了本地支持的 Kubernetes 上执行,但是 Apache Spark 也可以在 Apache Mesos 上运行。
如果你追求一个有管理的解决方案,那么可以发现 Apache Spark 已作为 Amazon EMR、Google Cloud Dataproc, 和 Microsoft Azure HDInsight 的一部分。雇佣了 Apache Spark 创始人的公司 Databricks 也提供了 Databricks 统一分析平台,这个平台是一个提供了 Apache Spark 集群,流式支持,集成了基于 Web 的笔记本开发,和在标准的 Apache Spark 分布上优化了云的 I/O 性能的综合管理服务。
值得一提的是,拿 Apache Spark 和 Apache Hadoop 比是有点不恰当的。目前,在大多数 Hadoop 发行版中都包含 Spark 。但是由于以下两大优势,Spark 在处理大数据时已经成为***框架,超越了使 Hadoop 腾飞的旧 MapReduce 范式。
***个优势是速度。Spark 的内存内数据引擎意味着在某些情况下,它执行任务的速度比 MapReduce 快一百倍,特别是与需要将状态写回到磁盘之间的多级作业相比时更是如此。即使 Apache Spark 的作业数据不能完全包含在内存中,它往往比 MapReduce 的速度快10倍左右。
第二个优势是对开发人员友好的 Spark API 。与 Spark 的加速一样重要的是,人们可能会认为 Spark API 的友好性更为重要。
Spark Core
与 MapReduce 和其他 Apache Hadoop 组件相比,Apache Spark API 对开发人员非常友好,在简单的方法调用后面隐藏了分布式处理引擎的大部分复杂性。其中一个典型的例子是几乎要 50 行的 MapReduce 代码来统计文档中的单词可以缩减到几行 Apache Spark 实现(下面代码是 Scala 中展示的):
- val textFile = sparkSession.sparkContext.textFile(“hdfs:///tmp/words”)
- val counts = textFile.flatMap(line => line.split(“ “))
- .map(word => (word, 1))
- .reduceByKey(_ + _)
- counts.saveAsTextFile(“hdfs:///tmp/words_agg”)
通过提供类似于 Python、R 等数据分析流行语言的绑定,以及更加对企业友好的 Java 和 Scala ,Apache Spark 允许应用程序开发人员和数据科学家以可访问的方式利用其可扩展性和速度。
Spark RDD
Apache Spark 的核心是弹性分布式数据集(Resilient Distributed Dataset,RDD)的概念,这是一种编程抽象,表示一个可以在计算集群中分离的不可变对象集合。 RDD 上的操作也可以跨群集分割,并以批处理并行方式执行,从而实现快速和可扩展的并行处理。
RDD 可以通过简单的文本文件、SQL 数据库、NoSQL 存储(如 Cassandra 和 MongoDB )、Amazon S3 存储桶等等创建。Spark Core API 的大部分是构建于 RDD 概念之上,支持传统的映射和缩减功能,还为连接数据集、过滤、采样和聚合提供了内置的支持。
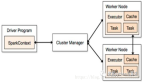
Spark 是通过结合驱动程序核心进程以分布式方式运行的,该进程将 Spark 应用程序分解成任务,并将其分发到完成任务的许多执行程序的进程中。这些执行程序可以根据应用程序的需要进行扩展和缩减。
Spark SQL
Spark SQL 最初被称为 Shark,Spark SQL 对于 Apache Spark 项目开始变得越来越重要。它就像现在的开发人员在开发应用程序时常用的接口。Spark SQL 专注于结构化数据的处理,借用了 R 和 Python 的数据框架(在 Pandas 中)。不过顾名思义,Spark SQL 在查询数据时还兼容了 SQL2003 的接口,将 Apache Spark 的强大功能带给分析师和开发人员。
除了支持标准的 SQL 外,Spark SQL 还提供了一个标准接口来读写其他数据存储,包括 JSON,HDFS,Apache Hive,JDBC,Apache Parquet,所有这些都是可以直接使用的。像其他流行的存储工具 —— Apache Cassandra、MongoDB、Apache HBase 和一些其他的能够从 Spark Packages 生态系统中提取出来单独使用的连接器。
下边这行简单的代码是从数据框架中选择一些字段:
- citiesDF.select(“name”, “pop”)
要使用 SQL 接口,首先要将数据框架注册成一个临时表,之后我们就可以使用 SQL 语句进行查询:
- citiesDF.createOrReplaceTempView(“cities”)
- spark.sql(“SELECT name, pop FROM cities”)
在后台, Apache Spark 使用名为 Catalyst 的查询优化器来检查数据和查询,以便为数据局部性和计算生成有效的查询计划,以便在集群中执行所需的计算。在 Apache Spark 2.x 版本中,Spark SQL 的数据框架和数据集的接口(本质上是一个可以在编译时检查正确性的数据框架类型,并在运行时利用内存并和计算优化)是推荐的开发方式。RDD 接口仍然可用,但只有无法在 Spark SQL 范例中封装的情况下才推荐使用。
Spark MLib
Apache Spark 还有一个捆绑许多在大数据集上做数据分析和机器学习的算法的库 (Spark MLib) 。Spark MLlib 包含一个框架用来创建机器学习管道和在任何结构化数据集上进行特征提取、选择、变换。MLLib 提供了聚类和分类算法的分布式实现,如 k 均值聚类和随机森林等可以在自定义管道间自由转换的算法。数据科学家可以在 Apache Spark 中使用 R 或 Python 训练模型,然后使用 MLLib 存储模型,***在生产中将模型导入到基于 Java 或者 Scala 语言的管道中。
需要注意的是 Spark MLLib 只包含了基本的分类、回归、聚类和过滤机器学习算法,并不包含深度学建模和训练的工具(更多内容 InfoWorld’s Spark MLlib review )。提供深度学习管道的工作正在进行中。
Spark GraphX
Spark GraphX 提供了一系列用于处理图形结构的分布式算法,包括 Google 的 PageRank 实现。这些算法使用 Spark Core 的 RDD 方法来建模数据;GraphFrames 包允许您对数据框执行图形操作,包括利用 Catalyst 优化器进行图形查询。
Spark Streaming
Spark Streaming 是 Apache Spark 的一个新增功能,它帮助在需要实时或接近实时处理的环境中获得牵引力。以前,Apache Hadoop 世界中的批处理和流处理是不同的东西。您可以为您的批处理需求编写 MapReduce 代码,并使用 Apache Storm 等实时流媒体要求。这显然导致不同的代码库需要保持同步的应用程序域,尽管是基于完全不同的框架,需要不同的资源,并涉及不同的操作问题,以及运行它们。
Spark Streaming 将 Apache Spark 的批处理概念扩展为流,将流分解为连续的一系列微格式,然后使用 Apache Spark API 进行操作。通过这种方式,批处理和流操作中的代码可以共享(大部分)相同的代码,运行在同一个框架上,从而减少开发人员和操作员的开销。每个人都能获益。
对 Spark Streaming 方法的一个批评是,在需要对传入数据进行低延迟响应的情况下,批量微操作可能无法与 Apache Storm,Apache Flink 和 Apache Apex 等其他支持流的框架的性能相匹配,所有这些都使用纯粹的流媒体方法而不是批量微操作。
Structured Streaming
Structured Streaming(在 Spark 2.x 中新增的特性)是针对 Spark Streaming 的,就跟 Spark SQL 之于 Spark 核心 API 一样:这是一个更高级别的 API,更易于编写应用程序。在使用 Structure Streaming 的情况下,更高级别的 API 本质上允许开发人员创建***流式数据帧和数据集。它还解决了用户在早期的框架中遇到的一些非常真实的痛点,尤其是在处理事件时间聚合和延迟传递消息方面。对 Structured Streaming 的所有查询都通过 Catalyst 查询优化器,甚至可以以交互方式运行,允许用户对实时流数据执行 SQL 查询。
Structured Streaming 在 Apache Spark 中仍然是一个相当新的部分,已经在 Spark 2.2 发行版中被标记为产品就绪状态。但是,Structure Streaming 是平台上流式传输应用程序的未来,因此如果你要构建新的流式传输应用程序,则应该使用 Structure Streaming。传统的 Spark Streaming API 将继续得到支持,但项目组建议将其移植到 Structure Streaming 上,因为新方法使得编写和维护流式代码更加容易。
Apache Spark 的下一步是什么?
尽管结构化数据流为 Spark Streaming 提供了高级改进,但它目前依赖于处理数据流的相同微量批处理方案。然而, Apache Spark 团队正在努力为平台带来连续的流媒体处理,这应该能够解决许多处理低延迟响应的问题(声称大约1ms,这将会非常令人印象深刻)。 更好的是,因为结构化流媒体是建立在 Spark SQL 引擎之上的,所以利用这种新的流媒体技术将不需要更改代码。
除此之外,Apache Spark 还将通过 Deep Learning Pipelines 增加对深度学习的支持。 使用 MLlib 的现有管线结构,您将能够在几行代码中构建分类器,并将自定义 Tensorflow 图形或 Keras 模型应用于传入数据。 这些图表和模型甚至可以注册为自定义的 Spark SQL UDF(用户定义的函数),以便深度学习模型可以作为 SQL 语句的一部分应用于数据。
这些功能目前都无法满足生产的需求,但鉴于我们之前在 Apache Spark 中看到的快速发展,他们应该会在2018年的黄金时段做好准备。