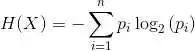本文介绍了来自伦敦大学学院(UCL)Thomas Anthony、Zheng Tian 与 David Barber 的深度学习与树搜索研究。该论文已被 NIPS 2017 大会接收。
二元处理机制理论
「二元处理机制」认为,人类的推理包括两种不同种类的思考方法。如下图所示,系统 1 是一个快速的、无意识的、自动化的思考模式,它也被称为直觉。系统 2 是一个慢速的、有意识的、显式的、基于规则的推理模式,它被认为是一种进化上的最新进展。
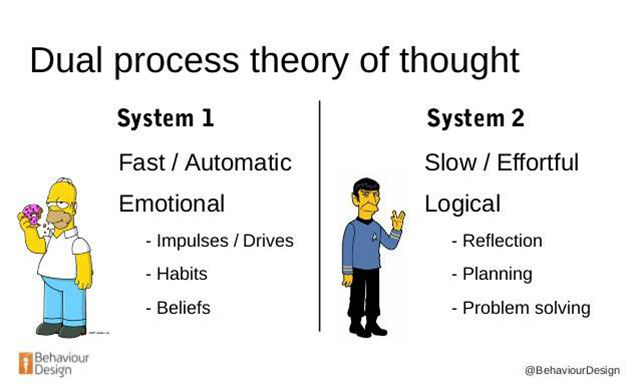
图片出处:https://www.slideshare.net/AshDonaldson/behaviour-design-predicting-irrational-decisions
在学习完成某项具有挑战性的规划任务(例如棋牌类游戏)时,人类会同时运用这两种处理方式:准确的直觉可以快速地选择有利路线,这使我们慢速的分析推理更加高效。而持续的深入学习又能逐渐提升直觉,从而使更准确的直觉回馈到更强大的分析中,这就形成了一个闭合的学习回路。换言之,人类是通过既快又慢的思考方式来学习的 [1]。
目前的深度强化学习存在什么问题?
在当前的深度强化学习算法中,例如策略梯度(Policy Gradient)和 DQN3[3], 神经网络在选择动作的时候没有任何前瞻性;这个和系统 1 类似。与人类直觉不同的是,这些强化学习算法在训练的过程中并没有一个「系统 2」来给它们推荐更好的策略。
AlphaGo 这类 AI 算法的一个缺陷之处在于,它们使用了人类专业玩家的数据库 [4]。在训练的初始阶段,强化学习智能体会模仿人类专家的行动—而只有经历这样的初始阶段,它们才会开始潜在地学习更强大的超人类玩法。但是这种算法从某种程度而言并不令人满意,因为它们可能会严重偏向某人类玩家的风格,从而忽视潜在的更好策略。同时,人类专家数据库在游戏领域中或许可得,而如果我们想要在其他情况下训练出一个 AI 机器,也许我们并没有这种可用的数据库。因此,从零开始训练出一个最先进的棋牌游戏玩家对 AI 而言是一项主要挑战。
专家迭代 (ExIt)
专家迭代(ExIt)是我们在 2017 年 5 月介绍的一个通用学习框架。它能够在不需要模仿人类策略的情况下就训练出强大的 AI 机器。

ExIt 可被视为模仿学习(Imitation Learning)的延伸,它可以扩展至连顶尖人类专家也无法达到满意表现的领域中。在标准的模仿学习中,学徒被训练以模仿专家的行为。ExIt 则将此方法延伸至一种迭代学习过程。在每一次迭代中,我们都会执行一次专家提升(expert improvement)步骤,在这个过程中我们会依靠(快速的)学徒策略来改善(相对较慢的)专家的表现。
ExIt
象棋这类棋类游戏或许可以帮助我们更直观地了解这个概念。在这类游戏中专家就类似于慢手下棋的棋手(每一步都花好多时间来决策),而学徒就像在下快棋(每一步都花很少时间决定如何走)。
一份独立的研究显示,玩家会在同一个位置考虑多个可能的行动,深入(缓慢)地思考每一步可能的行动。她会分析在当前位置哪几手棋会成功而哪几手棋会失败。当在未来遇到相似的棋局时,她之前的学习所培养出来的直觉就会迅速告诉她哪几手棋会可能更好。这样即使在快棋设置下,她依然可以表现不俗。她的直觉就来源于她模仿自己之前通过深度思考计算而获得的强大策略。人类不可能仅仅通过快棋而变成卓越的棋手,更深入的研究是学习过程中必需的部分。
对人工智能游戏机器而言,这种模仿是可以实现的,例如,将一个神经网络拟合到另一个「机器专家」的某一步棋。在短时间之内通过模仿目前所见到的专家的行动,学徒就可以学习到一个快棋策略。这里的关键点在于,假设在这个游戏背后存在一个潜在的结构,机器学习就能够让学徒将它们的直觉泛化到以前没有见到过的状态中去采取快速决策。也就是说,学徒没有仅仅是从有限的,固定的专家棋谱数据库中创建一个行动查询表,而是能将所学泛化到其他棋局状态中。所以神经网络既起着泛化的作用,也起到了模仿专家玩家的作用。
假设学徒通过模仿目前所见到的所有专家行动学到了一个快速决策,那么它就可以被专家所用。当专家希望采取行动的时候,学徒会很快地给出一些备选行动,然后专家会进行深入考虑,并且也许在这个慢速思考的过程中,专家还会继续受到学徒的敏锐直觉的指引。
在这个阶段的最后,专家会在学徒的辅助下采取一些行动,这样,每一步行动通常都会比仅由专家或者仅由学徒单独做出的行动要好。
接下来,上述的过程可以从学徒重新模仿(新)专家推荐的行动开始,反复进行下去。这会形成一个完整的学习阶段的迭代,迭代过程将持续,直到学徒收敛。
从二元处理机制方面来看,模仿学习(imitation learning)步骤类似于人类通过研究实例问题来提升直觉,然而专家提升(expert improvement)步骤则类似于人类利用自己已经得到提升的直觉去指导未来的分析。
树搜索和深度学习
ExIt 是一种通用的学习策略,学徒和专家可以用不同的形式具体化。在棋牌类游戏中,蒙特卡洛树搜索(Monte Carlo Tree Search)是一个强大的游戏策略 [6],是专家角色的天然候选者。深度学习已经被证明是一种模仿强悍玩家的成功方法 [4],所以我们将它作为学徒。
在专家提升(expert improvement)阶段,我们使用学徒来指引蒙特卡洛树搜索算法,让它朝着更有希望的方向行动,这有效地减少了游戏树搜索的宽度和深度。以这种方式,我们就能够把在模仿学习中得到的知识返回来用在规划算法中。
棋牌游戏 HEX
Hex 是一款经典的两玩家棋牌游戏,玩家在 n×n 的六边形格子上角逐。玩家颜色分为黑和白,轮流将代表自己颜色的棋子放在空格子中,如果有一列依次相连的黑子从南到北连在了一起,那么黑方获胜。如果有一列依次相连的白子从东到西连通,那么白方获胜。
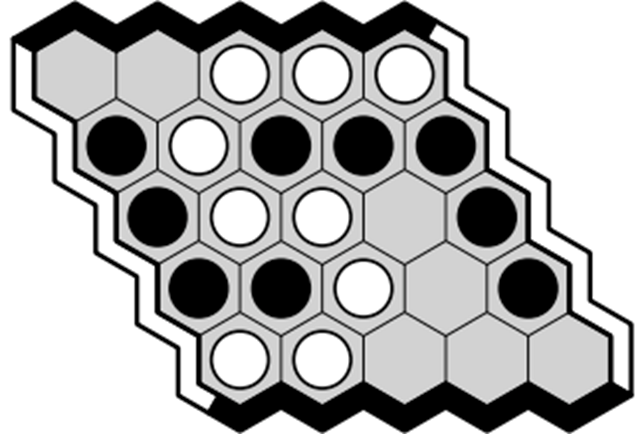
5×5 的 Hex 棋盘示例
上面是一个 5×5 的棋盘,其中白方获胜。Hex 有深度策略,这使得它对机器而言极具挑战性,它巨大的动作集合和连接规则意味着它和围棋给人工智能带来的挑战有些类似。然而,与围棋相比,它的规则更加简单,而且没有平局。
Hex 的规则很简单,因此数学分析方法非常适用於此,目前最好的机器玩家 MoHex[7] 使用的是蒙特卡洛树搜索和巧妙的数学思想。自 2009 年,MoHex 在所有的计算机游戏奥林匹克 Hex 竞赛中战无不胜。值得注意的是,MoHex 使用了人类专家数据库训练展开策略 (rollout policy)。
让我们一起验证,在不使用任何专业知识和人类专家棋谱的情况下(游戏规则除外),ExIt 训练策略是否可以训练出一个胜过 MoHex 的 AI 玩家。为此,我们使用蒙特卡罗树搜索作为专家,由学徒神经网络来引领专家。我们的神经网络是深度卷积神经网络的形式,具有两个输出策略–一个给白方,另一个给黑方(细节参见 [5])。
修正过的蒙特卡罗树搜索公式可实现专家提升(expert improvement):
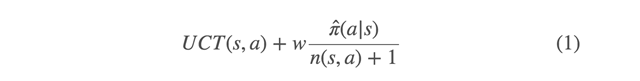
这里,s 是一个棋局状态,a 是一个在状态 s 下可能被采取的行动。UCT(s,a) 是蒙特卡罗树搜索中所使用的树 [6] 的经典上置信区间(Upper Confidence Bound),后面所加的那一项能帮助神经网络学徒指导专家搜索更佳的行动。其中π̂ 是学徒的策略(在状态 s 中对于每个潜在行动 a 的相对优势),n(s,a) 是搜索算法在状态 s 做出行动 a 的当前访问次数;w 是为了平衡专家的慢思考和学徒的快思考而经验性选择的权重因子。该附加项使神经网络学徒引领搜索至更有希望的行动,并且更快地拒绝不佳的行动。
为了在每一个模仿学习阶段生成用以训练学徒的数据,批处理方法每次都重新生成数据,抛弃之前迭代中产生的所有数据。因此,我们同时也考虑了一个仅保存有限的最新生成数据的在线版本,以及一个保留所有数据的在线版本,但是随着与最强玩法对应的最新专家的增多,数据会成指数增长。在下图中我们对比了一些不同的方法:从训练的时间去衡量每一种学习策略网络的强度(测量 ELO 分数)。
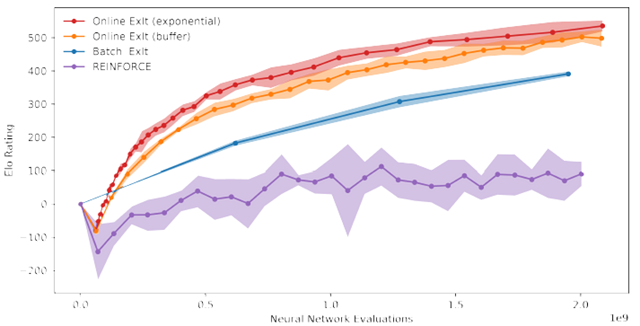
我们还展示了仅仅使用一个更传统的强化学习方法,通过自我对弈(self play)学到策略 π̂ (a|s) 的结果(换言之不使用蒙特卡罗树搜索)。这正是 AlphaGo 训练策略网络时所用的方法。上图的结果证明:ExIt 训练方法比传统方法更高效。值得注意的是,在这个例子中训练还没有完全收敛,在更充足的训练时间下,学徒还能进一步提升能力。
在论文中 [5],我们也运用了另一种能提升棋手性能的机制,也就是能够让学徒估计在自己独自下棋时获胜的概率的价值网络 Vπ̂ (s)。策略网络和价值网络被结合起来以帮助指导最终受学徒辅助的蒙特卡罗树搜索玩家(apprentice-aided MCTS player)。策略网络和价值网络使用一个和(1)近似,但是又有所修改(包含了学徒在 s 状态的价值)的方程指导最终的 MCTS 玩家。(细节参考 [5])
我们最终的 MCTS 玩家表现超越了最著名的 Hex 机器玩家 MoHex,在 9X9 的棋局中胜率是 75%。考虑到训练没有完全收敛,表示这个结果更加卓越。[9] 中展示了一些我们使用 ExIt 训练游的游戏机器玩家与目前最优的 MoHex 玩家对阵的情况。我们对比了从同一个状态开始时不同算法的玩法。论文 [5] 中有更多的例子。

ExIt(黑方)VS MoHex(白方)
MoHex(黑方)VS ExIt(白方)
ExIt 为何会如此成功?
部分原因模仿学习一般比强化学习容易,因此 EXIT 要比像 REINFORCE 等任意模型(model-free)的算法更成功。
此外,唯有在搜索中,相对其他选择来说,没有缺点的行动才会被 MCTS 推荐。因此 MCTS 的选择会比大多数潜在对手的选择更好。相比之下,在常规的自我对弈(网络自身充当对手角色)中,行动都是基于打败当前仅有的一个对手而推荐的,(因此所训练的棋手很有可能对当前的非最优对手过拟合)。我们认为这就是为什么 EXIT(使用 MCTS 作为专家时)会如此成功的关键因素 –事实上学徒在与很多对手的对战中都能取得良好的表现。
与 ALPHAGO ZERO 的关系
AlphaGo Zero[10](在我们的工作 [11] 发表之后的几个月之后问世)也实现了一种 ExIt 风格的算法,并且证明,在围棋中可以在不使用人类棋手棋谱的情况下达到当前最佳水平。论文 [5] 中给出了详细的对比。
总结
专家迭代是一种新的强化学习算法,它受启发于人类思维的二元处理机制理论。ExIt 将强化学习分解为两个独立的子问题:泛化和规划。规划在具体分析的基础上执行,并且在找到了强大的策略之后将之泛化。这将允许智能体做长期规划,并进行更快速的学习,即使在极具挑战的问题也能达到高水平表现。这个训练策略在棋牌类人工智能玩家中是非常强大的,不需要任何人类专家的棋谱就能达到当前最佳性能。