机器学习和数据科学工作远不是简单地把数据交给 Python 库处理,使用处理后的结果那么简单。本文将简要介绍一些利用 Bootstrapping 提升模型鲁棒性的方法。
数据科学家需要真正理解数据和如何处理数据,以实现成功的系统。
一个重要方法就是了解什么时候模型可以利用 Bootstrapping 方法获益。这就是集成模型。集成模型的一些示例有 AdaBoost 和随机梯度提升(Stochastic Gradient Boosting)。
为什么使用集成模型?
它们可以帮助提高算法准确率或改善模型的鲁棒性吗?集成学习是经过试验并效果属实的方法吗?Boosting 和 Bagging 是数据科学家和机器学习工程师必须了解的话题。特别是当你计划参加数据科学/机器学习面试的时候。
本质上,集成学习是「集成」的。集成学习使用成百上千个同样算法的模型寻找正确的分类。
对集成学习的另一种认知是「盲人摸象」。每个盲人发现大象的一个特征,认为大象是不同的事物。但是,聚在一起讨论后,他们可能会发现大象到底是什么模样。
使用 Boosting 和 Bagging 等技术可以提升统计模型的鲁棒性,降低方差。
那么现在问题来了,这些以 B 开头的单词(Bootstrapping/Bagging/Boosting)有什么区别呢?
Bootstrapping
首先让我们谈一下这个非常重要的概念 Bootstrapping。当很多数据科学家直接解释 Boosting 和 Bagging 时,他们偶尔会记起 Bootstrapping,因为两者都需要 Boosting 和 Bagging 。
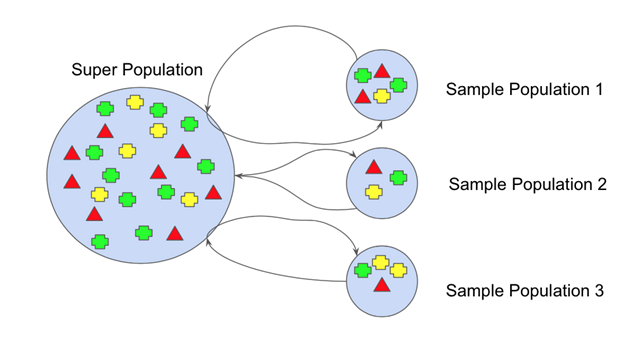
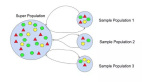
图 1 Bootstrapping
机器学习中,Bootstrap 方法指的是借助替换的随机采样,它是一个重采样,允许模型或算法更好地理解存在于其中的偏差、方差和特征。数据的采样允许重采样包含不同的偏向,然后将其作为一个整体进行包含。如图 1 所示,其中每个样本群有不同的部分,而且各不相同。接着这会影响到数据集的整体均值、标准差和其他描述性指标。反过来,它可以发展出更多鲁棒的模型。
Bootstrapping 同样适用倾向于过拟合的小数据集。事实上,我们把它推荐给了一家有关注的公司,其数据集远称不上「大数据」。Bootstrapping 是这一案例的一个解决方案,因为利用 Bootstrapping 的算法可以更鲁棒,并根据已选的方法论(Boosting 或 Bagging)来处理新数据集。
使用 Bootstrap 的原因是它可以测试解决方案的稳定性。使用多个样本数据集测试多个模型可以提高鲁棒性。或许一个样本数据集的平均值比其他数据集大,或者标准差不同。这种方式可以识别出过拟合且未使用不同方差数据集进行测试的模型。
Bootstrapping 越来越普遍的原因之一是计算能力的提升。出现比之前更多次数的重排列、重采样。Bagging 和 Boosting 都使用 Bootstrapping,下面将会具体介绍。
Bagging
Bagging 实际上指 Bootstrap Aggregator。大多数提到使用 Bagging 算法的论文或文章都会引用 Leo Breiman,他曾经写过一篇论文《Bagging Predictors》(1996)。
Leo 这么描述 Bagging:
「Bagging predictor 是一种生成多个预测器版本然后生成聚合预测器的方法。」
Bagging 的作用是降低只在训练数据上准确率较高的模型的方差——这种情况也叫作过拟合。
过拟合即函数过于拟合数据。通常原因在于实际的公式过于复杂,无法考虑每个数据点和异常值。
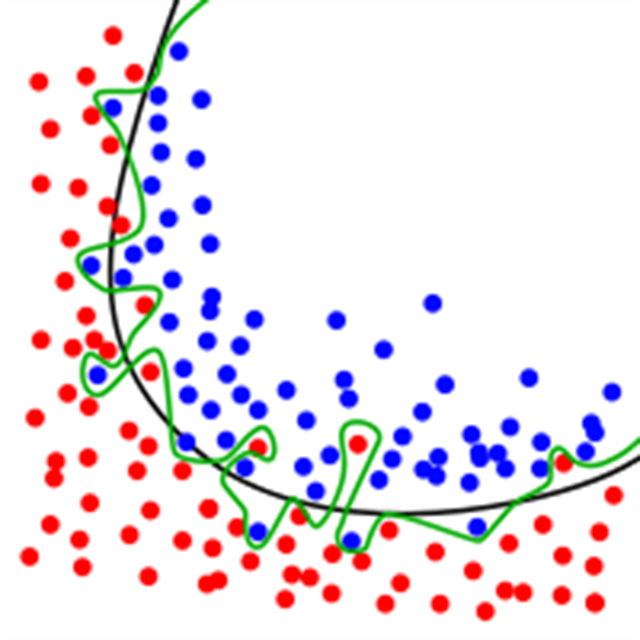
图 2. 过拟合
容易过拟合的另一种算法是决策树。使用决策树构建的模型需要非常简单的启发式方法。决策树由一系列特定顺序的 if-else 语句组成。因此,如果把一个数据集变更成新的数据集,则新数据集可能在底层特征中与之前的数据集存在一些偏差或区别。该模型不可能准确。原因在于数据无法非常好地拟合数据(前向声明)。
Bagging 使用采样和替换数据的方法在数据中创建自己的方差来规避这个问题,同时测试多个假设(模型)。通过使用多个样本(很可能由不同属性的数据组成)来减少噪声。
直到每个模型提出一个假设。这些模型使用投票法(voting)进行分类,用平均法进行回归。这里「Aggregating」和「Bootstrap Aggregating」将发挥作用。每个假设具备相同的权重。这是 Bagging 和 Boosting 方法的区别之一。
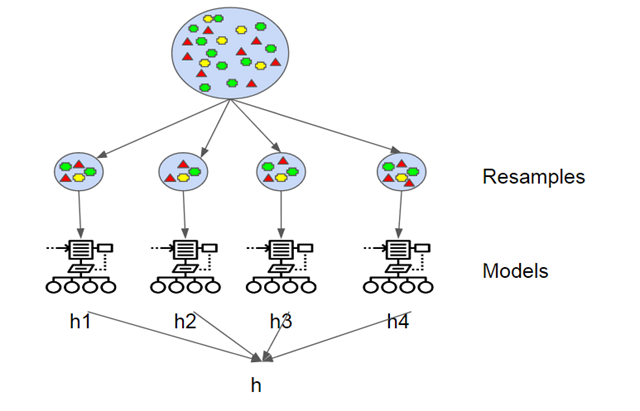
图 3. Bagging
本质上,所有这些模型同时运行,然后对哪个假设最准确进行投票。
这有助于降低方差,即减少过拟合。
Boosting
Boosting 指使用加权平均值使弱的学习器变强的一组算法。与 Bagging 不同,每个模型单独运行,***在不偏向任何模型的前提下聚合输出结果。Boosting 是一项「团队工作」。每个模型决定下一个模型要关注的特征。
Boosting 也需要 Bootstrapping。但是,这里还有一个区别。与 bagging 不同,boosting 为每个数据样本加权。这意味着一些样本运行的频率比其他样本高。
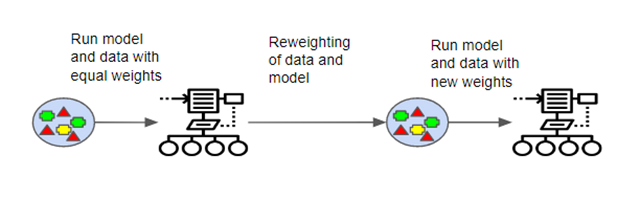
图 4. Boosting
当 Boosting 运行在模型中时,它追踪哪些数据样本是成功的,哪些不成功。输出结果分类错误最多的数据集会被赋予更高的权重。即这些数据更加复杂,需要更多次迭代才能恰当地训练模型。
在实际的分类阶段中,Boosting 处理模型的方式也存在区别。Boosting 追踪模型误差率,因为更好的模型会获得更好的权重。
这样,当「投票」(voting)出现时,结果更好的模型更有可能最终主导输出。
总结
Boosting 和 Bagging 能够有效降低方差。集成方法通常优于单个模型。这就是那么多 Kaggle 获胜者使用集成方法的原因。
但是,它们不适合所有问题,它们各自也有缺陷。Bagging 在模型过拟合时能够有效降低方差,但 Boosting 可能是二者中较好的选择。Boosting 更有可能导致性能问题,但它在模型欠拟合时也能有效降低偏差。
这就需要经验和专业知识了!***个模型能够成功运行可能比较容易,但是分析算法和它选择的所有特征非常重要。例如,如果一个决策树设置了特定的叶,那么这么设置的原因是什么呢?如果你无法用其他数据点或图支持它,它可能就不该实现。
这不只是在不同的数据集上尝试 AdaBoost 或随机森林。我们需要根据算法的倾向和获得的支持来决定最终使用的算法。