在项目实战中,需根据业务真实诉求,针对业务模型进行***实践分析和洞察,从主机端口、存储系统、后端磁盘等端到端进行分析和评估,才能提供比较切合业务诉求的配置。
那么,通常有哪些因素会影响对性能的准确评估呢?在本文中会把项目性能评估中遇到的难点话题依次罗列,希望对大家有所帮助。
一、IO聚合优化写惩罚
IO聚合成满分条大小的情况下,无需做预读操作,不会触发RAID写惩罚,RAID写惩罚在不是满分条写的时候,才会触发预读的流程。以RAID5-5小写为例,写一个数据位,需要预读两次,写校验位一次。可以认为是一个IO被放大成了四个IO。
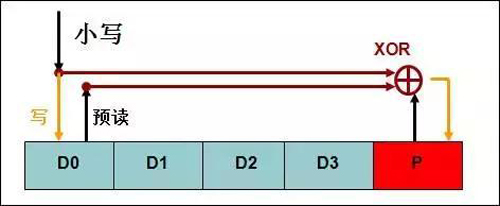
而满分条写的时候,同时写四个数据位,不需要预读,只需要额外写一次校验位,可以认为是四个IO被放大成了五个IO 。对比非满分条写,效率大大提高。
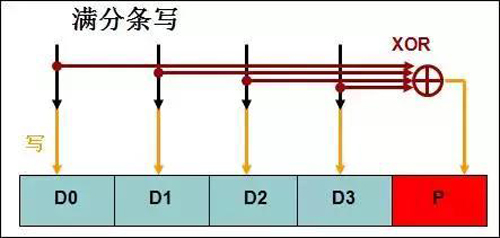
存储的IO合并能力对于数据库业务是否各家都能做到IO合并呢?一般存储针对不同类型的IO有不同的合并能力;数据库业务主要是随机IO,各厂商都做不到完全满分条IO合并。存储收到的IO是否能够合并,主要取决于两个方面。
1、主机侧发下来的业务IO是否顺序,是否连续,与主机业务软件本身、主机侧块设备、卷管理策略、HBA卡拆分策略等相关。主机下发的IO越顺序、越连续,到达阵列后的合并效果越好。
2、IO路径上的Cache、存储块设备、硬盘等模块都会对IO进行排序与合并的操作,试图尽可能将小IO合成大IO下盘。
对于顺序小IO而言,基本上能够实现将IO都合并成满分条后下盘。而对于IO随机程度较高的数据库业务,各厂商都无法确保所有IO都能够合并,只能尽量通过排序和合并,将相邻地址的小IO合成大IO,但合并程度由于算法实现和内存大小等因素可能会有所差异。
二、场景的业务模型
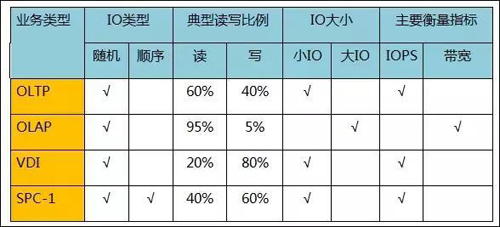
OLTP、OLAP、VDI和SPC-1是当前性能评估中常见的三类业务场景。SPC-1是业界通用的随机IOPS型的IO模型,在不清楚实际业务类型的条件下,常用此模型来进行性能评估。四种模型的简单IO特征如下表所示。
1、OLTP业务模型和特征:
每个事务的读,写,更改涉及的数据量非常小,同时有很多用户连接到数据库,使用数据库,要求数据库有很快的响应时间,通常一个事务在几秒内完成,时延要求一般在10-20ms。
针对Data LUN,主要是随机小IO,IO大小主要为8KB(IO大小与数据库的Block块大小一致),读写比约为3:2,读全随机,写有一定合并。 针对LOG LUN,多路顺序小IO,大小不定,几乎都是写IO。
2、OLAP业务模型和特征:
一般很少有数据修改,除非在批量加载数据时;系统调用非常复杂的查询语句,同时扫描非常多的行;一个查询将花费数小时,甚至数天;主要取决于查询语句的复杂程度;查询的输出通常是一个统计值,由group by与order by得出;当读取操作进行时,发生的写操作通常在临时表空间内;平常对在线日志写入很少,除非在批量加载数据时;分析型业务,一般对时延没有要求。
针对Data LUN,多路顺序大IO(可以近似认为是随机大IO),IO大小与主机侧设置的分条大小有关(如512KB),90%以上为读业务,混合间断读写。针对TMP LUN,随机IO,读写混合(先写后读,计算时写,读临时表时读,大部分是写,占整个业务中很少部分的IO),IO大小基本为200KB以上大IO。
3、VDI业务模型和特征
可以分为启动风暴、登录风暴和平稳状态几个常见场景,在不同的状态下,业务压力相差很大。启动风暴,即大量虚拟机同时启动时的突发状态,是读密集型操作。登录风暴,即大量用户同时登录到桌面,导致共享存储产生大量爆发性负载的情况,是写密集型的,很难通过技术方式避免。平稳状态,即所有用户在同时使用桌面时,产生负载波动较小的状态。不同的用户类型,平稳状态的负载有所不同。时延要求一般在10ms左右。
平稳状态下,读写比例约为2:8,多路顺序小IO,主要是写,存在一定的合并,IO大小从512B到16KB都有;少量的读IO,基本都是16KB,在负载稳定之后,Cache***率在80%以上。
4、SPC-1业务模型和特征
SPC-1设计一个专门为测试存储系统在典型业务应用场合下的负载模型,这个负载模型连续不断地对业务系统并发的做查询和更新的工作,因此其主要由随机I/O组成。这些随机I/O的操作主要涉及数据库型的OLTP应用以及E-mail系统应用,能够很好地衡量存储系统的IOPS指标。
它抽象的测试区域称为ASU,包括ASU1临时数据区域,ASU2用户数据区域和ASU3日志区域。对整体而言,读写比约为4:6,顺序IO与随机IO的比例约为3:7,IO大小主要为4KB,有较明显的热点访问区域。
三、如何考虑校验对性能的影响
对于顺序写业务,IO经过cache的IO合并后下发到RAID层,基本能够确保都是满分条写。对于RAID5-5(4D+1P)这种配置来说,每4个数据IO(D)下盘同时会有一个校验IO(P)需要下盘。校验IO下盘所占的硬盘带宽用于保障数据的可靠性,而对于用户上层业务来说并没有提供可用带宽,因此需要扣除掉校验位下盘所占的带宽开销。
对于顺序读业务,在满分条的情况下,在每个分条内部只需要读数据位所在的磁盘,不需要读校验位所在的磁盘。
例如,某一款产品,能够提供的***写带宽为3200MB,规划配置96块600GB 15k SAS盘(推荐单盘写带宽为30MB),部署RAID6-6(4D+2P),估算这款产品能够提供的有效写带宽。
硬盘提供的有效写带宽 = 单盘顺序写带宽 * 硬盘数量 * (RAID数据盘数量/RAID总盘数)= 30MB * 96 * (4/6)= 1920 MB
产品能提供的有效写带宽 = MIN(产品能提供的***写带宽,硬盘提供的有效写带宽)= MIN(3200MB,1920MB)= 1920 MB
四、读写比和对性能影响
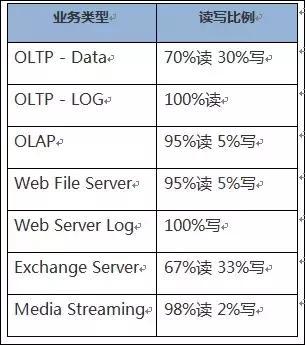
读写比指的是上层应用下发的读IO和写IO的比例分布。此数据是存储规划的重要参考依据。读业务与写业务消耗的存储资源差异很大。下面是一些典型业务模型的常见读写比例
确切了解上层应用的读写比例直接影响到对cache策略、RAID级别和LUN配置的选择。写业务比读业务会消耗更多的存储系统资源。
1、在回写的场景下,写IO下发到cache之后需要通过交换通道“镜像”到对端控制器,IO路径更长,并需要占用交换通道的带宽;
2、为保证写数据的可靠性和一致性,智能存储通常会采用一些可靠性技术,例如writehole方案,需要将写数据额外保存一份在cache或磁盘上;
3、对于不同的RAID级别而言,写惩罚的存在会造成更大的时延和资源的开销;此外对于磁盘(包括SSD盘)而言,写速度低于读速度。
而对于读业务来说,通常消耗较少的系统资源。例如,读业务不需要生成额外的数据来保证数据一致。此外,绝大部分存储设备的读速度都比写速度要快。当读IO发现它所需读取的数据已经在Cache中(读***)时,可以直接返回而不需要再下盘读取。在读***的情况下,通常意味着最短的响应时延。
同样数量的主机IO,如果读写比例不同,最终需要下盘的IO数量不同,意味着需要提供的磁盘能力不同。
五、RAID级别对性能影响
由于各RAID级别的写惩罚不同,对于相同的业务类型、同样数量的硬盘而言,选择不同的RAID算法,能够提供给主机的性能是不相等的。
针对各种典型场景的RAID10、RAID5和RAID6的性能对比,其中假设某存储设备上所有硬盘能够提供的性能为100%,按照各个应用场景的读写比例,经过写惩罚系数的折算,得到配置成各个RAID级别后能提供给用户的实际性能。
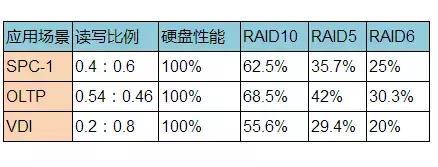
从数据中也可以看出,对于不同的业务类型、同样数量的硬盘、相同的RAID算法,写比例越大,性能越差。以SPC-1场景配置RAID6为例,假设用户实际性能为x(0.4x + 0.6x * 6 = 100%),实际性能只是磁盘能提供的x = 25%。
由于RAID算法的实现原理不同(RAID10的镜像、RAID5/6的校验盘),对于同样大小的裸容量来说,选择不同的RAID算法,可提供给用户的可用容量是不同的(不考虑热备空间和系统预留的影响)。

从可靠性的层面来看,RAID6的可靠性***,RAID10次之,RAID5最差。RAID6和RAID10都支持同时坏2块盘不丢数据,但是RAID10对坏的2块盘是有条件要求的。
六、顺序、随机特性对性能影响
在磁盘层面,顺序IO的性能优于随机IO。这是由于传统的机械磁盘读写数据需要盘片转动和磁头移动,使得随机读写的盘片旋转和磁头寻道时间要远大于顺序读写。
在智能存储系统层面,通常情况下,顺序IO的性能同样大大优于随机IO,特别是对于小IO的IOPS性能而言。
1、小IO读:通过顺序流识别和预取算法,系统提前在磁盘上读取大块的连续数据存放在cache中,后续的大量顺序小IO在cache中***,无需下盘处理。而随机小IO在cache中***率极低,只能逐个下盘读。
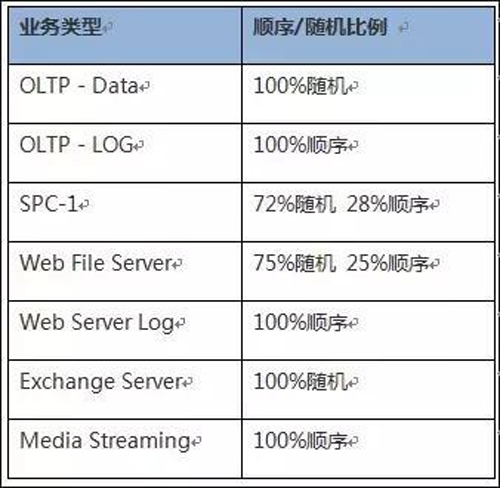
2、小IO写:通过IO合并,系统将多个顺序小IO合并成一个较大的IO下盘。如果在RAID5或RAID6场景,IO聚合成满分条大小的情况下,无需做预读操作,不会触发RAID写惩罚,效率很高。而随机小IO无法合并,只能逐个下盘写,且会触发写惩罚,导致性能更为低下。典型业务场景的顺序/随机特性,以下是一些典型业务场景的顺序/随机特性。
七、IO大小对性能的影响
IO的大小取决于上层应用程序本身。对性能而言,小IO一般用IOPS来衡量,大IO一般用带宽来衡量。例如我们熟悉的SPC-1,主要衡量存储系统在随机小IO负荷下的IOPS,而SPC-2则主要衡量在各种高负荷连续读写应用场合下存储系统的带宽。
就单个IO而言,大IO从微观角度相比小IO会需要更多的处理资源。对于随机IO而言,随着随机IO块大小的增加,IOPS会随之降低。例如,当随机IO大小大于16KB时,机械硬盘的IOPS会呈线性下降。因此,我们通常SPC-1测试的IOPS值很高,但因为用户业务模型不同,IO大小不同,性能值也是变化的。
不过对于智能存储系统来说,会尽可能通过排序、合并、填充等方法对IO进行整合,将多个小IO组合成单个大IO。例如,典型的Web Server Log业务,一般是8KB大小的顺序小IO,在分条大小设置为128KB的存储设备上,最终会将16个8KB大小的小IO合并成一个128KB的大IO下发到硬盘上。在这种情况下,对比处理多个小IO,处理单个大IO的速度更快、开销更小。
IO的大小,影响到磁盘选型,缓存、RAID类型、LUN的一些属性和策略的调优。例如,随机小IO的场景,由于SSD盘具有快速随机读写的特性,选用SSD盘对比SAS盘能够大幅提升性能;但如果是随机大IO,选用带宽性能相当、价钱便宜的SAS盘更有优势。
八、缓存Cache对性能影响
Cache是存储中最重要的模块之一,对于IOPS性能而言,Cache的主要作用是加速。对于写业务,Cache加速体现在三个方面。
1、回写情况下,主机侧下到阵列侧的数据只需要下到CACHE处而不需要真正写到磁盘即可以返回通知主机写完成,当写CACHE的数据积累到一定程度(水位),阵列才把数据刷到磁盘。由此可以将速度较差的“同步单个写”转为“异步批量写”,在通常情况下,回写的性能约是透写性能的两倍以上。
2、写***。回写条件下,新写到Cache中的数据发现在Cache中已经有准备写到相同地址但还没有刷盘的数据。在这种情况下,只需要将新写入的数据下盘即可。
3、写合并。例如小IO下到Cache中,Cache会尽可能对IO进行排序与合并,将多个小IO合成单个大IO再下盘。
对于读业务,Cache加速主要体现在读***。例如智能预取策略,Cache会主动识别IO流的特征,如果发现是顺序IO流,Cache会在下盘读IO的同时,主动读取相邻区域的大块数据放到Cache中。当顺序IO下发到Cache时,发现Cache中已存放了需要的数据,则直接将此数据返回即可,不需要再下盘读。其中的一个特例是“全***”。在全***条件下,业务需要读取的数据已经全部保存到Cache中,完全不需要再下盘处理,即所有IO到Cache层就返回了,路径和时延最短。全***读的IOPS值,往往是一款存储产品能够提供的***IOPS值。