近日,软件工程师 James Le 在 Medium 上发表了一篇题为《The 10 Deep Learning Methods AI Practitioners Need to Apply》的文章,从反向传播到***池化***到迁移学习,他在文中分享了主要适用于卷积神经网络、循环神经网络和递归神经网络的10大深度学习方法。机器之心对本文进行了编译,原文链接请见文末。
过去十年来,人们对机器学习兴趣不减。你几乎每天都会在计算机科学程序、行业会议和华尔街日报上看到机器学习。对于所有关于机器学习的讨论,很多人把机器学习能做什么与希望其做什么混为一谈。从根本上说,机器学习就是使用算法从原始数据中提取信息,并通过模型进行实现。我们使用这个模型来推断我们尚未建模的其他数据。
神经网络属于机器学习模型的一种,已出现 50 多年,其基本单元即受到哺乳动物大脑中生物神经元启发的非线性变换节点。神经元之间的连接也是仿效生物大脑,并在时间中通过训练推移发展。
1980 年代中期和 1990 年代早期,神经网络的很多重要架构取得重大进展。然而,获得良好结果所需的时间和数据量却阻碍了其应用,因此人们一时兴趣大减。2000 年早期,计算能力呈指数级增长,业界见证了之前不可能实现的计算技术的「寒武纪爆炸」。深度学习作为该领域的一个重要竞争者是在这个十年的爆炸性计算增长中脱颖而出,它赢得了许多重要的机器学习竞赛。深度学习的热度在 2017 年达到峰值,你在机器学习的所有领域都可以看到深度学习。
为了深入了解这一热潮,我学习了 Udacity 的深度学习课程,它很好地介绍了深度学习的起源,以及通过 TensorFlow 从复杂和/或大型数据集中学习的智能系统的设计。对于课程项目,我使用和开发了带有卷积的图像识别神经网络,带有嵌入表征的 NLP 神经网络和带有 RNN 和 LSTM 的基于字符的文本生成神经网络。所有的 Jupiter Notebook 代码可参见:
https://github.com/khanhnamle1994/deep-learning。
下面是一个作业的结果,一个通过相似性聚类的词向量的 t-SNE 投影。

最近,我已经开始阅读相关学术论文。根据我的研究,下面是一些对该领域发展产生重大影响的著作:
- 纽约大学的《Gradient-Based Learning Applied to Document Recognition》(1998),介绍了机器学习领域的卷积神经网络:http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
- 多伦多大学的《Deep Boltzmann Machines》(2009),它展现了一个用于玻尔兹曼机的、包含多个隐藏变量层的新学习算法:http://proceedings.mlr.press/v5/salakhutdinov09a/salakhutdinov09a.pdf
- 斯坦福大学和谷歌的《Building High-Level Features Using Large-Scale Unsupervised Learning》(2012),它解决了只从无标注数据中构建高阶、特定类别的特征探测器的问题:http://icml.cc/2012/papers/73.pdf
- 伯克利大学的《DeCAF—A Deep Convolutional Activation Feature for Generic Visual Recognition》(2013),它推出了 DeCAF,一个深度卷积激活功能和所有相关网络参数的开源实现,能够帮助视觉研究者在一系列视觉概念学习范例中开展深度表征实验:http://proceedings.mlr.press/v32/donahue14.pdf
- DeepMind 的《Playing Atari with Deep Reinforcement Learning》(2016),它展示了借助强化学习直接从高维感知输入中成功学习控制策略的***深度学习模型:https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf
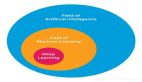
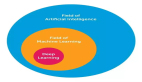
在研究和学习了大量知识之后,我想分享 10 个强大的深度学习方法,工程师可用其解决自己的机器学习问题。开始之前,让我们定义一下什么是深度学习。深度学习是很多人面临的一个挑战,因为过去十年来它在缓慢改变着形式。为了形象化地界定深度学习,下图给出了人工智能、机器学习和深度学习三者之间的关系。

人工智能领域最为广泛,已存在 60+ 年。深度学习是机器学习的一个子领域,机器学习是人工智能的一个子领域。深度学习区分于传统的前馈多层网络的原因通常有以下几点:
- 更多的神经元
- 层之间更复杂的连接方式
- 训练算力的「寒武纪爆炸」
- 自动特征提取
当我说「更多的神经元」,我的意思是神经元数目逐年增长以表达更复杂的模型。层也从多层网络中完全连接的每层发展到卷积神经网络中层之间的局部连接的神经元补丁,以及与循环神经网络中的同一神经元(除了与前一层的连接之外)的周期性连接。
接着深度学习可被定义为下面四个基本网络架构之一中的带有大量参数和层的神经网络:
- 无监督预训练网络
- 卷积神经网络
- 循环神经网络
- 递归神经网络
本文将主要介绍后面 3 个架构。卷积神经网络基本是一个标准的神经网络,通过共享权重在整个空间扩展。卷积神经网络被设计为通过在内部卷积来识别图像,可看到已识别图像上物体的边缘。循环神经网络通过将边缘馈送到下一个时间步而不是在同一时间步中进入下一层,从而实现整个时间上的扩展。循环神经网络被设计用来识别序列,比如语音信号或文本序列,其内部循环可存储网络中的短时记忆。递归神经网络更像是一个分层网络,其中输入序列没有真正的时间维度,但输入必须以树状方式进行分层处理。以下 10 种方法可被用于上述所有架构。
1. 反向传播
反向传播简单地说就是一种计算函数(在神经网络中为复合函数形式)的偏导数(或梯度)的方法。当使用基于梯度的方法(梯度下降只是其中一种)求解优化问题的时候,需要在每一次迭代中计算函数的梯度。

在神经网络中,目标函数通常是复合函数的形式。这时如何计算梯度?有两种方式:(i)解析微分(Analytic differentiation),函数的形式是已知的,直接使用链式法则计算导数就可以。(ii)利用有限差分的近似微分(Approximate differentiation using finite difference),这种方法的运算量很大,因为函数计算量(number of function evaluation)等于 O(N),其中 N 是参数数量。相比于解析微分,运算量大得多。有限差分通常在调试的时候用于验证反向传播的实现。
2. 随机梯度下降
理解梯度下降的一种直观的方法是想象一条河流从山顶顺流而下的路径。梯度下降的目标正好就是河流力争实现的目标—即,到达***点(山脚)。
假设山的地形使得河流在到达***点之前不需要做任何停留(最理想的情况,在机器学习中意味着从初始点到达了全局最小/***解)。然而,也存在有很多凹点的地形,使得河流在其路径中途停滞下来。在机器学习的术语中,这些凹点被称为局部极小解,是需要避免的情况。有很多种方法能解决这种问题(本文未涉及)。

因此,梯度下降倾向于停滞在局部极小解,这取决于地形((或机器学习中的函数))的性质。但是,当山地的地形是一种特殊类型的时候,即碗形地貌,在机器学习中称为凸函数,算法能保证找到***解。凸函数是机器学习优化中最想遇到的函数。而且,从不同的山顶(初始点)出发,到达***点之前的路径也是不同的。类似地,河流的流速(梯度下降算法中的学习率或步长)的不同也会影响路径的形态。这些变量会影响梯度下降是困在局域***解还是避开它们。
3. 学习率衰减

调整随机梯度下降优化过程的学习率可以提升性能并减少训练时间,称为学习率退火(annealing)或适应性学习率。最简单的也可能是最常用的训练中的学习率调整技术是随时间降低学习率。这有益于在训练刚开始的时候使用更大的学习率获得更大的变化,并在后期用更小的学习率对权重进行更精细的调整。
两种简单常用的学习率衰减方法如下:
- 随 epoch 的增加而降低学习率;
- 在特定的 epoch 间断地降低学习率。
4. dropout
拥有大量参数的深度神经网络是很强大的机器学习系统。然而,这样的网络有很严重的过拟合问题。而且大型网络的运行速度很慢,使得在测试阶段通过结合多个不同大型神经网络的预测解决过拟合的过程也变得很慢。dropout 正是针对这个问题应用的技术。

其关键的思想是在训练过程中随机删除神经网络的单元和相应的连接,从而防止过拟合。在训练过程中,dropout 将从指数级数量的不同的稀疏网络中采样。在测试阶段,很容易通过用单 untwined 网络(有更小的权重)将这些稀疏网络的预测取平均而逼近结果。这能显著地降低过拟合,相比其它的正则化方法能得到更大的性能提升。dropout 被证明在监督学习任务比如计算机视觉、语音识别、文本分类和计算生物学中能提升神经网络的性能,并在多个基准测试数据集中达到***结果。
5. ***池化
***池化是一种基于样本的离散化方法,目标是对输入表征(图像、隐藏层的输出矩阵,等)进行下采样,降低维度,并允许假设包含在子区域中的被丢弃的特征。

通过提供表征的抽象形式,这种方法在某种程度上有助于解决过拟合。同样,它也通过减少学习参数的数量和提供基本的内部表征的转换不变性减少了计算量。***池化通过在初始表征的子区域(通常是非重叠的)取***值而抽取特征与防止过拟合。
6. 批量归一化
神经网络(包括深度网络)通常需要仔细调整权重初始化和学习参数。批量归一化能使这个过程更简单。
权重问题:
- 无论哪种权重初始化比如随机或按经验选择,这些权重值都和学习权重差别很大。考虑在初始 epoch 中的一个小批量,在所需要的特征激活中可能会有很多异常值。
- 深度神经网络本身就具有病态性,即初始层的微小变动就会导致下一层的巨大变化。
在反向传播过程中,这些现象会导致梯度的偏离,意味着梯度在学习权重以生成所需要的输出之前,需要对异常值进行补偿,从而需要额外的 epoch 进行收敛。

批量归一化会系统化梯度,避免因异常值出现偏离,从而在几个小批量内直接导向共同的目标(通过归一化)。
学习率问题:
- 学习率通常保持小值,从而使梯度对权重的修正很小,因为异常值激活的梯度不应该影响学习激活。通过批量归一化,这些异常值激活会被降低,从而可以使用更大的学习率加速学习过程。
7. 长短期记忆
长短期记忆(LSTM)网络的神经元和其它 RNN 中的常用神经元不同,有如下三种特征:
- 它对神经元的输入有决定权;
- 它对上一个时间步中计算内容的存储有决定权;
- 它对将输出传递到下一个时间步的时间有决定权。
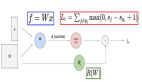
LSTM 的强大在于它能只基于当前的输入就决定以上所有的值。看看下方的图表:

当前时间步的输入信号 x(t) 决定了以上 3 个值。输入门决定了***个值,忘记门决定了第二个值,输出门决定了第三个值。这是由我们的大脑工作方式所启发的,可以处理输入中的突然的情景变化。
8. Skip-gram
词嵌入模型的目标是为每一个词汇项学习一个高维密集表征,其中嵌入向量的相似表示相关词的语义或句法的相似。skip-gram 是一种学习词嵌入算法的模型。
skip-gram 模型(和很多其它词嵌入模型)背后的主要思想是:如果两个词汇项有相似的上下文,则它们是相似的。

换种说法,假设你有一个句子,比如「cats are mammals」,如果用「dogs」替换「cats」,该句子仍然是有意义的。因此在这个例子中,「dogs」和「cats」有相似的上下文(即,「are mammals」)。
居于上述的假设,我们可以考虑一个上下文窗口,即一个包含 k 个连续项的窗口。然后我们应该跳过一些单词以学习能得到除跳过项外其它所有的项的神经网络,并用该神经网络尝试预测跳过的项。如果两个词在大型语料库中共享相似的上下文,那么这些嵌入向量将有非常相近的向量。
9. 连续词袋模型
在自然语言处理中,我们希望学习将文档中每一个单词表示为一个数值向量,并使得出现在相似上下文中的单词有非常相似或相近的向量。在连续词袋模型(CBOW)中,我们的目标是能利用特定词的上下文而预测该特定词出现的概率。

我们可以通过在大型语料库中抽取大量语句而做到这一点。每当模型看到一个单词时,我们就会抽取该特定单词周围出现的上下文单词。然后将这些抽取的上下文单词输入到一个神经网络以在上下文出现的条件下预测中心词的概率。
当我们有成千上万个上下文单词与中心词,我们就有了训练神经网络的数据集样本。在训练神经网络中,***经过编码的隐藏层输出特定单词的嵌入表达。这种表达就正是相似的上下文拥有相似的词向量,也正好可以用这样一个向量表征一个单词的意思。
10. 迁移学习
现在让我们考虑图像到底如何如何流经卷积神经网络的,这有助于我们将一般 CNN 学习到的知识迁移到其它图像识别任务。假设我们有一张图像,我们将其投入到***个卷积层会得到一个像素组合的输出,它们可能是一些识别的边缘。如果我们再次使用卷积,就能得到这些边和线的组合而得到一个简单的图形轮廓。这样反复地卷积***就能层级地寻找特定的模式或图像。因此,***一层就会组合前面抽象的特征寻找一个非常特定的模式,如果我们的卷积网络是在 ImageNet 上训练的,那么***一层将组合前面抽象特征识别特定的 1000 个类别。如果我们将***一层替换为我们希望识别的类别,那么它就能很高效地训练与识别。

深度卷积网络每一个层会构建出越来越高级的特征表征方式,***几层往往是专门针对我们馈送到网络中的数据,因此早期层所获得的特征更为通用。
迁移学习就是在我们已训练过的 CNN 模型进行修正而得到的。我们一般会切除***一层,然后再使用新的数据重新训练新建的***一个分类层。这一过程也可以解释为使用高级特征重新组合为我们需要识别的新目标。这样,训练时间和数据都会大大减小,我们只需要重新训练***一层就完成了整个模型的训练。
深度学习非常注重技术,且很多技术都没有太多具体的解释或理论推导,但大多数实验结果都证明它们是有效的。因此也许从基础上理解这些技术是我们后面需要完成的事情。
原文:
https://towardsdatascience.com/the-10-deep-learning-methods-ai-practitioners-need-to-apply-885259f402c1