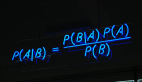前言
机器学习(ML)分为:监督学习,无监督学习,半监督学习等。
1.1 监督学习(supervised learning)
监督学习是训练神经网络和决策树的常见技术,高度依赖事先确定的分类系统给出的信息,对于神经网络,分类系统利用信息判断网络的错误,然后不断调整网络参数。对于决策树,分类系统用它来判断哪些属性提供了最多的信息。
从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。
监督学习的训练集要求包括输入输出,也可以说是特征和目标,训练集中的目标是由人标注的。
常见的有监督学习算法:回归分析和统计分类,最典型的算法是KNN和SVM。
有监督学习最常见的就是:regression & classification
Regression:Y是实数向量,回归问题,就是拟合(x,y)的一条曲线,使得价值函数(cost function) L最小。
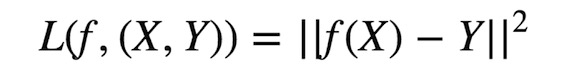
Classification:Y是一个有穷数(finite number),可以看做类标号,分类问题首先要给定有label的数据训练分类器,故属于有监督学习过程,分类过程中cost function l(X,Y)是X属于类Y的概率的负对数。
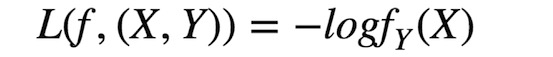
其中fi(X)=P(Y=i/X)。
有监督学习方法必须要有训练集与测试样本,在训练集中找规律,而对测试样本使用这种规律。
有监督学习的方法就是识别事物,识别的结果表现在给待识别数据加上了标签,因此训练样本集必须由带标签的样本组成。
1.2 名词KNN
k-Nearest Neighbors
在一个给定的数据点上找出k个最近的数据点,在分类的情况下输出输出类的多数投票值,以及在回归情况下目标值的平均值。
撸袖子
2.1 新新相映
软件是基于***的postgresql 10.0加上***的madlib 1.12。
为了操作方便,我这里使用基于docker的ubuntu 16.04安装madlib,这样以后就可以拿着这个镜像到处嗨了,以下操作就是在MAC里面进行的。
2.2 查看madlib版本
- #select madlib.version();
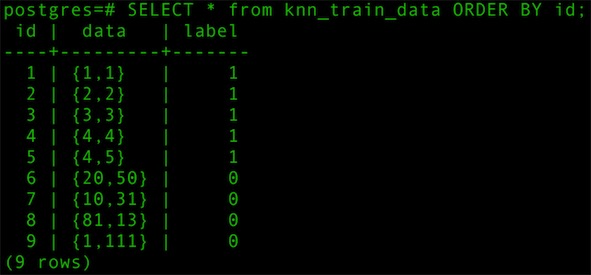
2.3 导入训练数据
- DROP TABLE IF EXISTS knn_train_data;
- CREATE TABLE knn_train_data (
- id integer,
- data integer[],
- label float
- );
- INSERT INTO knn_train_data VALUES
- (1, '{1,1}', 1.0),
- (2, '{2,2}', 1.0),
- (3, '{3,3}', 1.0),
- (4, '{4,4}', 1.0),
- (5, '{4,5}', 1.0),
- (6, '{20,50}', 0.0),
- (7, '{10,31}', 0.0),
- (8, '{81,13}', 0.0),
- (9, '{1,111}', 0.0);
- SELECT * from knn_train_data ORDER BY id;
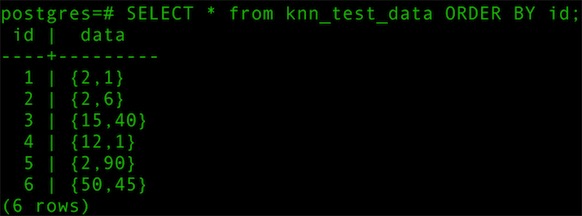
2.4 导入测试数据
- DROP TABLE IF EXISTS knn_test_data;
- CREATE TABLE knn_test_data (
- id integer,
- data integer[]
- );
- INSERT INTO knn_test_data VALUES
- (1, '{2,1}'),
- (2, '{2,6}'),
- (3, '{15,40}'),
- (4, '{12,1}'),
- (5, '{2,90}'),
- (6, '{50,45}');
- SELECT * from knn_test_data ORDER BY id;
2.5 分类训练
- SELECT * FROM madlib.knn(
- 'knn_train_data', -- 训练数据表名
- 'data', -- 训练数据所在列
- 'label', -- 训练标签
- 'knn_test_data', -- 测试数据表名
- 'data', -- 测试数据所在列
- 'id', -- 测试数据列名id
- 'madlib_knn_result_classification', -- 结果输出
- 'c', -- 分类
- 3 -- 最近相邻数
- );
2.6 查看分类输出结果
- SELECT * from madlib_knn_result_classification ORDER BY id;
图形化示例:

2.7 进行回归
- DROP TABLE IF EXISTS madlib_knn_result_regression;
- SELECT * FROM madlib.knn(
- 'knn_train_data', -- 训练数据表名
- 'data', -- 训练数据所在列
- 'label', -- 训练标签
- 'knn_test_data', -- 测试数据表名
- 'data', -- 测试数据所在列
- 'id', -- 测试数据列名id
- 'madlib_knn_result_regression', --结果输出
- 'r', -- 回归
- 3 -- 最近相邻数
- );
2.8 查看回归输出结果
- SELECT * from madlib_knn_result_regression ORDER BY id;
图形化示例:

小结
postgresql提供了对结构化数据的存储和加工的便捷,madlib提供了ML算法的支持,强强联手,相得益彰。
【作者简介】孙辉,DataHunter技术总监。曾在索尼等知名公司任职,先后担任过系统架构、技术总监等职位,负责过尚邮,索爱中文输入法,快牙,mPush(魔推)等知名产品研发。拥有15年深厚IT技术行业经验,熟悉掌控产品研发各个环节,有丰富的后端、前端、运维、DBA、测试经验。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】