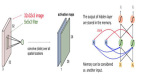
如今,TensorFlow大版本已经升级到了1.3,对很多的网络层实现了更高层次的封装和实现,甚至还整合了如Keras这样优秀的一些高层次框架,使得其易用性大大提升。相比早起的底层代码,如今的实现更加简洁和优雅。
本文是基于TensorFlow在中文数据集上的简化实现,使用了字符级CNN和RNN对中文文本进行分类,达到了较好的效果。
数据集
本文采用了清华NLP组提供的THUCNews新闻文本分类数据集的一个子集(原始的数据集大约74万篇文档,训练起来需要花较长的时间)。数据集请自行到THUCTC:一个高效的中文文本分类工具包下载,请遵循数据提供方的开源协议。
本次训练使用了其中的10个分类,每个分类6500条数据。
类别如下:
体育, 财经, 房产, 家居, 教育, 科技, 时尚, 时政, 游戏, 娱乐
这个子集可以在此下载:链接:http://pan.baidu.com/s/1bpq9Eub 密码:ycyw
数据集划分如下:
- 训练集: 5000*10
- 验证集: 500*10
- 测试集: 1000*10
从原数据集生成子集的过程请参看helper下的两个脚本。其中,copy_data.sh用于从每个分类拷贝6500个文件,cnews_group.py用于将多个文件整合到一个文件中。执行该文件后,得到三个数据文件:
- cnews.train.txt: 训练集(50000条)
- cnews.val.txt: 验证集(5000条)
- cnews.test.txt: 测试集(10000条)
预处理
data/cnews_loader.py为数据的预处理文件。
- read_file(): 读取文件数据;
- build_vocab(): 构建词汇表,使用字符级的表示,这一函数会将词汇表存储下来,避免每一次重复处理;
- read_vocab(): 读取上一步存储的词汇表,转换为{词:id}表示;
- read_category(): 将分类目录固定,转换为{类别: id}表示;
- to_words(): 将一条由id表示的数据重新转换为文字;
- preocess_file(): 将数据集从文字转换为固定长度的id序列表示;
- batch_iter(): 为神经网络的训练准备经过shuffle的批次的数据。
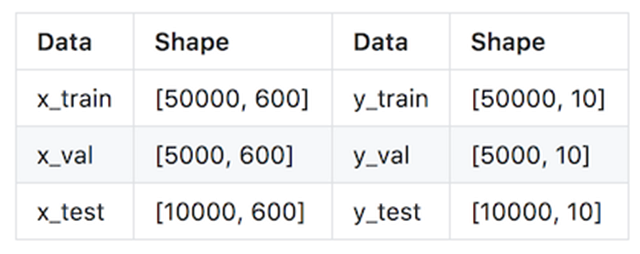
经过数据预处理,数据的格式如下:
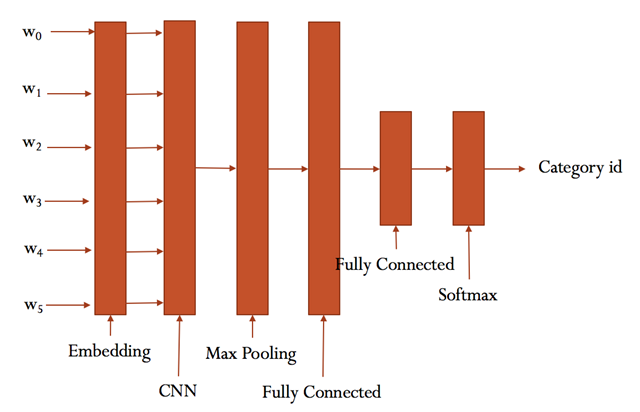
CNN卷积神经网络
配置项
CNN可配置的参数如下所示,在cnn_model.py中。
- class TCNNConfig(object):
- """CNN配置参数"""
- embedding_dim = 64 # 词向量维度
- seq_length = 600 # 序列长度
- num_classes = 10 # 类别数
- num_filters = 128 # 卷积核数目
- kernel_size = 5 # 卷积核尺寸
- vocab_size = 5000 # 词汇表达小
- hidden_dim = 128 # 全连接层神经元
- dropout_keep_prob = 0.5 # dropout保留比例
- learning_rate = 1e-3 # 学习率
- batch_size = 64 # 每批训练大小
- num_epochs = 10 # 总迭代轮次
- print_per_batch = 100 # 每多少轮输出一次结果
- save_per_batch = 10 # 每多少轮存入tensorboard
CNN模型
具体参看cnn_model.py的实现。
大致结构如下:
训练与验证
运行 python run_cnn.py train,可以开始训练。
若之前进行过训练,请把tensorboard/textcnn删除,避免TensorBoard多次训练结果重叠。
- Configuring CNN model...
- Configuring TensorBoard and Saver...
- Loading training and validation data...
- Time usage: 0:00:14
- Training and evaluating...
- Epoch: 1
- Iter: 0, Train Loss: 2.3, Train Acc: 10.94%, Val Loss: 2.3, Val Acc: 8.92%, Time: 0:00:01 *
- Iter: 100, Train Loss: 0.88, Train Acc: 73.44%, Val Loss: 1.2, Val Acc: 68.46%, Time: 0:00:04 *
- Iter: 200, Train Loss: 0.38, Train Acc: 92.19%, Val Loss: 0.75, Val Acc: 77.32%, Time: 0:00:07 *
- Iter: 300, Train Loss: 0.22, Train Acc: 92.19%, Val Loss: 0.46, Val Acc: 87.08%, Time: 0:00:09 *
- Iter: 400, Train Loss: 0.24, Train Acc: 90.62%, Val Loss: 0.4, Val Acc: 88.62%, Time: 0:00:12 *
- Iter: 500, Train Loss: 0.16, Train Acc: 96.88%, Val Loss: 0.36, Val Acc: 90.38%, Time: 0:00:15 *
- Iter: 600, Train Loss: 0.084, Train Acc: 96.88%, Val Loss: 0.35, Val Acc: 91.36%, Time: 0:00:17 *
- Iter: 700, Train Loss: 0.21, Train Acc: 93.75%, Val Loss: 0.26, Val Acc: 92.58%, Time: 0:00:20 *
- Epoch: 2
- Iter: 800, Train Loss: 0.07, Train Acc: 98.44%, Val Loss: 0.24, Val Acc: 94.12%, Time: 0:00:23 *
- Iter: 900, Train Loss: 0.092, Train Acc: 96.88%, Val Loss: 0.27, Val Acc: 92.86%, Time: 0:00:25
- Iter: 1000, Train Loss: 0.17, Train Acc: 95.31%, Val Loss: 0.28, Val Acc: 92.82%, Time: 0:00:28
- Iter: 1100, Train Loss: 0.2, Train Acc: 93.75%, Val Loss: 0.23, Val Acc: 93.26%, Time: 0:00:31
- Iter: 1200, Train Loss: 0.081, Train Acc: 98.44%, Val Loss: 0.25, Val Acc: 92.96%, Time: 0:00:33
- Iter: 1300, Train Loss: 0.052, Train Acc: 100.00%, Val Loss: 0.24, Val Acc: 93.58%, Time: 0:00:36
- Iter: 1400, Train Loss: 0.1, Train Acc: 95.31%, Val Loss: 0.22, Val Acc: 94.12%, Time: 0:00:39
- Iter: 1500, Train Loss: 0.12, Train Acc: 98.44%, Val Loss: 0.23, Val Acc: 93.58%, Time: 0:00:41
- Epoch: 3
- Iter: 1600, Train Loss: 0.1, Train Acc: 96.88%, Val Loss: 0.26, Val Acc: 92.34%, Time: 0:00:44
- Iter: 1700, Train Loss: 0.018, Train Acc: 100.00%, Val Loss: 0.22, Val Acc: 93.46%, Time: 0:00:47
- Iter: 1800, Train Loss: 0.036, Train Acc: 100.00%, Val Loss: 0.28, Val Acc: 92.72%, Time: 0:00:50
- No optimization for a long time, auto-stopping...
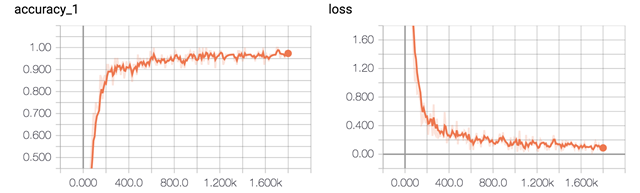
在验证集上的最佳效果为94.12%,且只经过了3轮迭代就已经停止。
准确率和误差如图所示:
测试
运行 python run_cnn.py test 在测试集上进行测试。
- Configuring CNN model...
- Loading test data...
- Testing...
- Test Loss: 0.14, Test Acc: 96.04%
- Precision, Recall and F1-Score...
- precision recall f1-score support
- 体育 0.99 0.99 0.99 1000
- 财经 0.96 0.99 0.97 1000
- 房产 1.00 1.00 1.00 1000
- 家居 0.95 0.91 0.93 1000
- 教育 0.95 0.89 0.92 1000
- 科技 0.94 0.97 0.95 1000
- 时尚 0.95 0.97 0.96 1000
- 时政 0.94 0.94 0.94 1000
- 游戏 0.97 0.96 0.97 1000
- 娱乐 0.95 0.98 0.97 1000
- avg / total 0.96 0.96 0.96 10000
- Confusion Matrix...
- [[991 0 0 0 2 1 0 4 1 1]
- [ 0 992 0 0 2 1 0 5 0 0]
- [ 0 1 996 0 1 1 0 0 0 1]
- [ 0 14 0 912 7 15 9 29 3 11]
- [ 2 9 0 12 892 22 18 21 10 14]
- [ 0 0 0 10 1 968 4 3 12 2]
- [ 1 0 0 9 4 4 971 0 2 9]
- [ 1 16 0 4 18 12 1 941 1 6]
- [ 2 4 1 5 4 5 10 1 962 6]
- [ 1 0 1 6 4 3 5 0 1 979]]
- Time usage: 0:00:05
在测试集上的准确率达到了96.04%,且各类的precision, recall和f1-score都超过了0.9。
从混淆矩阵也可以看出分类效果非常优秀。
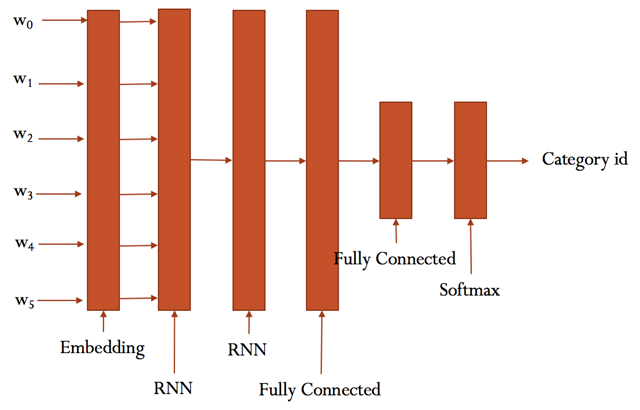
RNN循环神经网络
配置项
RNN可配置的参数如下所示,在rnn_model.py中。
- class TRNNConfig(object):
- """RNN配置参数"""
- # 模型参数
- embedding_dim = 64 # 词向量维度
- seq_length = 600 # 序列长度
- num_classes = 10 # 类别数
- vocab_size = 5000 # 词汇表达小
- num_layers= 2 # 隐藏层层数
- hidden_dim = 128 # 隐藏层神经元
- rnn = 'gru' # lstm 或 gru
- dropout_keep_prob = 0.8 # dropout保留比例
- learning_rate = 1e-3 # 学习率
- batch_size = 128 # 每批训练大小
- num_epochs = 10 # 总迭代轮次
- print_per_batch = 100 # 每多少轮输出一次结果
- save_per_batch = 10 # 每多少轮存入tensorboard
RNN模型
具体参看rnn_model.py的实现。
大致结构如下:
训练与验证
这部分的代码与 run_cnn.py极为相似,只需要将模型和部分目录稍微修改。
运行 python run_rnn.py train,可以开始训练。
若之前进行过训练,请把tensorboard/textrnn删除,避免TensorBoard多次训练结果重叠。
- Configuring RNN model...
- Configuring TensorBoard and Saver...
- Loading training and validation data...
- Time usage: 0:00:14
- Training and evaluating...
- Epoch: 1
- Iter: 0, Train Loss: 2.3, Train Acc: 8.59%, Val Loss: 2.3, Val Acc: 11.96%, Time: 0:00:08 *
- Iter: 100, Train Loss: 0.95, Train Acc: 64.06%, Val Loss: 1.3, Val Acc: 53.06%, Time: 0:01:15 *
- Iter: 200, Train Loss: 0.61, Train Acc: 79.69%, Val Loss: 0.94, Val Acc: 69.88%, Time: 0:02:22 *
- Iter: 300, Train Loss: 0.49, Train Acc: 85.16%, Val Loss: 0.63, Val Acc: 81.44%, Time: 0:03:29 *
- Epoch: 2
- Iter: 400, Train Loss: 0.23, Train Acc: 92.97%, Val Loss: 0.6, Val Acc: 82.86%, Time: 0:04:36 *
- Iter: 500, Train Loss: 0.27, Train Acc: 92.97%, Val Loss: 0.47, Val Acc: 86.72%, Time: 0:05:43 *
- Iter: 600, Train Loss: 0.13, Train Acc: 98.44%, Val Loss: 0.43, Val Acc: 87.46%, Time: 0:06:50 *
- Iter: 700, Train Loss: 0.24, Train Acc: 91.41%, Val Loss: 0.46, Val Acc: 87.12%, Time: 0:07:57
- Epoch: 3
- Iter: 800, Train Loss: 0.11, Train Acc: 96.09%, Val Loss: 0.49, Val Acc: 87.02%, Time: 0:09:03
- Iter: 900, Train Loss: 0.15, Train Acc: 96.09%, Val Loss: 0.55, Val Acc: 85.86%, Time: 0:10:10
- Iter: 1000, Train Loss: 0.17, Train Acc: 96.09%, Val Loss: 0.43, Val Acc: 89.44%, Time: 0:11:18 *
- Iter: 1100, Train Loss: 0.25, Train Acc: 93.75%, Val Loss: 0.42, Val Acc: 88.98%, Time: 0:12:25
- Epoch: 4
- Iter: 1200, Train Loss: 0.14, Train Acc: 96.09%, Val Loss: 0.39, Val Acc: 89.82%, Time: 0:13:32 *
- Iter: 1300, Train Loss: 0.2, Train Acc: 96.09%, Val Loss: 0.43, Val Acc: 88.68%, Time: 0:14:38
- Iter: 1400, Train Loss: 0.012, Train Acc: 100.00%, Val Loss: 0.37, Val Acc: 90.58%, Time: 0:15:45 *
- Iter: 1500, Train Loss: 0.15, Train Acc: 96.88%, Val Loss: 0.39, Val Acc: 90.58%, Time: 0:16:52
- Epoch: 5
- Iter: 1600, Train Loss: 0.075, Train Acc: 97.66%, Val Loss: 0.41, Val Acc: 89.90%, Time: 0:17:59
- Iter: 1700, Train Loss: 0.042, Train Acc: 98.44%, Val Loss: 0.41, Val Acc: 90.08%, Time: 0:19:06
- Iter: 1800, Train Loss: 0.08, Train Acc: 97.66%, Val Loss: 0.38, Val Acc: 91.36%, Time: 0:20:13 *
- Iter: 1900, Train Loss: 0.089, Train Acc: 98.44%, Val Loss: 0.39, Val Acc: 90.18%, Time: 0:21:20
- Epoch: 6
- Iter: 2000, Train Loss: 0.092, Train Acc: 96.88%, Val Loss: 0.36, Val Acc: 91.42%, Time: 0:22:27 *
- Iter: 2100, Train Loss: 0.062, Train Acc: 98.44%, Val Loss: 0.39, Val Acc: 90.56%, Time: 0:23:34
- Iter: 2200, Train Loss: 0.053, Train Acc: 98.44%, Val Loss: 0.39, Val Acc: 90.02%, Time: 0:24:41
- Iter: 2300, Train Loss: 0.12, Train Acc: 96.09%, Val Loss: 0.37, Val Acc: 90.84%, Time: 0:25:48
- Epoch: 7
- Iter: 2400, Train Loss: 0.014, Train Acc: 100.00%, Val Loss: 0.41, Val Acc: 90.38%, Time: 0:26:55
- Iter: 2500, Train Loss: 0.14, Train Acc: 96.88%, Val Loss: 0.37, Val Acc: 91.22%, Time: 0:28:01
- Iter: 2600, Train Loss: 0.11, Train Acc: 96.88%, Val Loss: 0.43, Val Acc: 89.76%, Time: 0:29:08
- Iter: 2700, Train Loss: 0.089, Train Acc: 97.66%, Val Loss: 0.37, Val Acc: 91.18%, Time: 0:30:15
- Epoch: 8
- Iter: 2800, Train Loss: 0.0081, Train Acc: 100.00%, Val Loss: 0.44, Val Acc: 90.66%, Time: 0:31:22
- Iter: 2900, Train Loss: 0.017, Train Acc: 100.00%, Val Loss: 0.44, Val Acc: 89.62%, Time: 0:32:29
- Iter: 3000, Train Loss: 0.061, Train Acc: 96.88%, Val Loss: 0.43, Val Acc: 90.04%, Time: 0:33:36
- No optimization for a long time, auto-stopping...
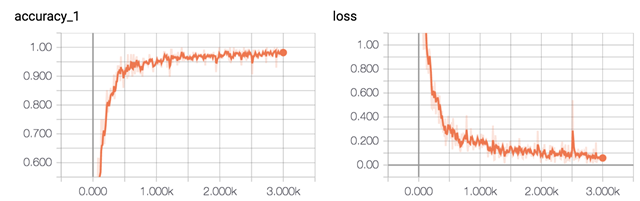
在验证集上的最佳效果为91.42%,经过了8轮迭代停止,速度相比CNN慢很多。
准确率和误差如图所示:
测试
运行 python run_rnn.py test 在测试集上进行测试。
- Testing...
- Test Loss: 0.21, Test Acc: 94.22%
- Precision, Recall and F1-Score...
- precision recall f1-score support
- 体育 0.99 0.99 0.99 1000
- 财经 0.91 0.99 0.95 1000
- 房产 1.00 1.00 1.00 1000
- 家居 0.97 0.73 0.83 1000
- 教育 0.91 0.92 0.91 1000
- 科技 0.93 0.96 0.94 1000
- 时尚 0.89 0.97 0.93 1000
- 时政 0.93 0.93 0.93 1000
- 游戏 0.95 0.97 0.96 1000
- 娱乐 0.97 0.96 0.97 1000
- avg / total 0.94 0.94 0.94 10000
- Confusion Matrix...
- [[988 0 0 0 4 0 2 0 5 1]
- [ 0 990 1 1 1 1 0 6 0 0]
- [ 0 2 996 1 1 0 0 0 0 0]
- [ 2 71 1 731 51 20 88 28 3 5]
- [ 1 3 0 7 918 23 4 31 9 4]
- [ 1 3 0 3 0 964 3 5 21 0]
- [ 1 0 1 7 1 3 972 0 6 9]
- [ 0 16 0 0 22 26 0 931 2 3]
- [ 2 3 0 0 2 2 12 0 972 7]
- [ 0 3 1 1 7 3 11 5 9 960]]
- Time usage: 0:00:33
在测试集上的准确率达到了94.22%,且各类的precision, recall和f1-score,除了家居这一类别,都超过了0.9。
从混淆矩阵可以看出分类效果非常优秀。
对比两个模型,可见RNN除了在家居分类的表现不是很理想,其他几个类别较CNN差别不大。
还可以通过进一步的调节参数,来达到更好的效果。