Map Reduce & YARN
A、简介
Apache Hadoop 是一个开源软件框架,可安装在一个商用机器集群中,使机器可彼此通信并协同工作,以高度分布式的方式共同存储和处理大量数据。最初,Hadoop 包含以下两个主要组件:Hadoop Distributed File System (HDFS) 和一个分布式计算引擎,该引擎支持以 MapReduce 作业的形式实现和运行程序。

MapReduce 是 Google 推广的一个简单的编程模型,它对以高度并行和可扩展的方式处理大数据集很有用。MapReduce 的灵感来源于函数式编程,用户可将他们的计算表达为 map 和 reduce 函数,将数据作为键值对来处理。Hadoop 提供了一个高级 API 来在各种语言中实现自定义的 map 和 reduce 函数。
Hadoop 还提供了软件基础架构,以一系列 map 和 reduce 任务的形式运行 MapReduce 作业。Map 任务 在输入数据的子集上调用 map 函数。在完成这些调用后,reduce 任务 开始在 map 函数所生成的中间数据上调用 reduce 任务,生成最终的输出。 map 和 reduce 任务彼此单独运行,这支持并行和容错的计算。
最重要的是,Hadoop 基础架构负责处理分布式处理的所有复杂方面:并行化、调度、资源管理、机器间通信、软件和硬件故障处理,等等。得益于这种干净的抽象,实现处理数百(或者甚至数千)个机器上的数 TB 数据的分布式应用程序从未像现在这么容易过,甚至对于之前没有使用分布式系统的经验的开发人员也是如此。
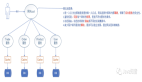
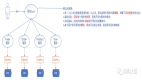
B、MR架构

将任务分割为 Map 端和 reduce 端。
一、JobClient JobTracker TaskTracker

- JobClient 向 JobTracker 请求一个新的 jobID
- 检查作业输出说明
- 计算作业输出划分split
- 将运行作业所需要的资源(作业的jar文件、配置文件、计算所得的输入划分)复制到一个以作业ID命名的目录中JobTracker的文件系统。
通过调用JobTracker的submitJob()方法,告诉JobTracker作业准备执行
JobTracker接收到submitJob()方法调用后,把此调用放到一个内部队列中,交由作业调度器进行调度,并对其进行初始化
创建运行任务列表,作业调度去首先从共享文件系统中获取JobClient已经计算好的输入划分信息(图中step6),然后为每个划分创建一个Map任务(一个split对应一个map,有多少split就有多少map)。
TaskTracker执行一个简单的循环,定期发送心跳(heartbeat)调用JobTracker
二、shuffle combine
整体的Shuffle过程包含以下几个部分:Map端Shuffle、Sort阶段、Reduce端Shuffle。即是说:Shuffle 过程横跨 map 和 reduce 两端,中间包含 sort 阶段,就是数据从 map task 输出到reduce task输入的这段过程。
sort、combine 是在 map 端的,combine 是提前的 reduce ,需要自己设置。
Hadoop 集群中,大部分 map task 与 reduce task 的执行是在不同的节点上。当然很多情况下 Reduce 执行时需要跨节点去拉取其它节点上的map task结果。如果集群正在运行的 job 有很多,那么 task 的正常执行对集群内部的网络资源消耗会很严重。而对于必要的网络资源消耗,最终的目的就是***化地减少不必要的消耗。还有在节点内,相比于内存,磁盘 IO 对 job 完成时间的影响也是可观的。从最基本的要求来说,对于 MapReduce 的 job 性能调优的 Shuffle 过程,目标期望可以有:
- 完整地从map task端拉取数据到reduce 端。
- 在跨节点拉取数据时,尽可能地减少对带宽的不必要消耗。
- 减少磁盘IO对task执行的影响。
- 总体来讲这段Shuffle过程,能优化的地方主要在于减少拉取数据的量及尽量使用内存而不是磁盘。
三、Map Shuffle

1、输入
在map task 执行时,其输入来源 HDFS的 block ,map task 只读取split 。Split 与 block 的对应关系可能是多对一,默认为一对一。
2、切分
决定于当前的 mapper的 part交给哪个 reduce的方法是:mapreduce 提供的Partitioner接口,对key 进行 hash 后,再以 reducetask 数量取模,然后到指定的 job 上。
然后将数据写入内存缓冲区中,缓冲区的作用是批量收集map结果,减少磁盘IO的影响。key/value对以及 Partition 的结果都会被写入缓冲区。写入之前,key 与value 值都会被序列化成字节数组。
3、溢写
由于内存缓冲区的大小限制(默认100MB),当map task输出结果很多时就可能发生内存溢出,所以需要在一定条件下将缓冲区的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写。
这个溢写是由另外单独线程来完成,不影响往缓冲区写map结果的线程。
整个缓冲区有个溢写的比例spill.percent。这个比例默认是0.8,
Combiner 将有相同key的 key/value 对加起来,减少溢写spill到磁盘的数据量。Combiner的适用场景:由于Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。故大多数情况下,combiner适用于输入输出的key/value类型完全一致,且不影响最终结果的场景(比如累加、***值等……)。
4、Merge
map 很大时,每次溢写会产生一个 spill_file,这样会有多个 spill_file,而最终的输出只有一个文件,在最终输出之前会对多个中间过程多次产生的溢写文件 spill_file 进行合并,此过程就是 merge。
merge 就是把相同 key 的结果加起来。(当然,如果设置过combiner,也会使用combiner来合并相同的key)
四、Reduce Shuffle

1、reduce shuffle
在 reduce task 之前,不断拉取当前 job 里每个 maptask 的最终结果,然后对从不同地方拉取过来的数据不断地做 merge ,也最终形成一个文件作为 reduce task 的输入文件。
2、copy
Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为maptask早已结束,这些文件就归TaskTracker管理在本地磁盘中。
3、merge
Copy 过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比 map 端的更为灵活,它基于 JVM 的 heap size 设置,因为 Shuffle 阶段 Reducer 不运行,所以应该把绝大部分的内存都给 Shuffle 用。这里需要强调的是,merge 有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下***种形式不启用,让人比较困惑,是吧。当内存中的数据量到达一定阈值,就启动内存到磁盘的 merge 。与 map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有 map 端的数据时才结束,然后启动第三种磁盘到磁盘的 merge 方式生成最终的那个文件。
4、reducer的输入
merge 的***会生成一个文件,大多数情况下存在于磁盘中,但是需要将其放入内存中。当reducer 输入文件已定,整个 Shuffle 阶段才算结束。然后就是 Reducer 执行,把结果放到 HDFS 上。
C、YARN
YARN(Yet Another Resource Negotiator),下一代MapReduce框架的名称,为了容易记忆,一般称为MRv2(MapReduce version 2)。该框架已经不再是一个传统的MapReduce框架,甚至与MapReduce无关,她是一个通用的运行时框架,用户可以编写自己的计算框架,在该运行环境中运行。用于自己编写的框架作为客户端的一个lib,在运用提交作业时打包即可。
五、why YARN instead of MR
MR 的缺点
经典 MapReduce 的最严重的限制主要关系到可伸缩性、资源利用和对与 MapReduce 不同的工作负载的支持。在 MapReduce 框架中,作业执行受两种类型的进程控制:
- 一个称为 JobTracker 的主要进程,它协调在集群上运行的所有作业,分配要在 TaskTracker 上运行的 map 和 reduce 任务。
- 许多称为 TaskTracker 的下级进程,它们运行分配的任务并定期向 JobTracker 报告进度。
- 大型的 Hadoop 集群显现出了由单个 JobTracker 导致的可伸缩性瓶颈。
此外,较小和较大的 Hadoop 集群都从未***效地使用他们的计算资源。在 Hadoop MapReduce 中,每个从属节点上的计算资源由集群管理员分解为固定数量的 map 和 reduce slot,这些 slot 不可替代。设定 map slot 和 reduce slot 的数量后,节点在任何时刻都不能运行比 map slot 更多的 map 任务,即使没有 reduce 任务在运行。这影响了集群的利用率,因为在所有 map slot 都被使用(而且我们还需要更多)时,我们无法使用任何 reduce slot,即使它们可用,反之亦然。
Hadoop 设计为仅运行 MapReduce 作业。随着替代性的编程模型(比如 Apache Giraph 所提供的图形处理)的到来,除 MapReduce 外,越来越需要为可通过高效的、公平的方式在同一个集群上运行并共享资源的其他编程模型提供支持。
- 原MapReduce框架的不足
- JobTracker是集群事务的集中处理点,存在单点故障
- JobTracker需要完成的任务太多,既要维护job的状态又要维护job的task的状态,造成过多的资源消耗
- 在taskTracker端,用map/reduce task作为资源的表示过于简单,没有考虑到CPU、内存等资源情况,当把两个需要消耗大内存的task调度到一起,很容易出现OOM
- 把资源强制划分为map/reduce slot,当只有map task时,reduce slot不能用;当只有reduce task时,map slot不能用,容易造成资源利用不足。
- 解决可伸缩性问题
在 Hadoop MapReduce 中,JobTracker 具有两种不同的职责:
管理集群中的计算资源,这涉及到维护活动节点列表、可用和占用的 map 和 reduce slots 列表,以及依据所选的调度策略将可用 slots 分配给合适的作业和任务
协调在集群上运行的所有任务,这涉及到指导 TaskTracker 启动 map 和 reduce 任务,监视任务的执行,重新启动失败的任务,推测性地运行缓慢的任务,计算作业计数器值的总和,等等
为单个进程安排大量职责会导致重大的可伸缩性问题,尤其是在较大的集群上,JobTracker 必须不断跟踪数千个 TaskTracker、数百个作业,以及数万个 map 和 reduce 任务。相反,TaskTracker 通常近运行十来个任务,这些任务由勤勉的 JobTracker 分配给它们。
为了解决可伸缩性问题,一个简单而又绝妙的想法应运而生:我们减少了单个 JobTracker 的职责,将部分职责委派给 TaskTracker,因为集群中有许多 TaskTracker。在新设计中,这个概念通过将 JobTracker 的双重职责(集群资源管理和任务协调)分开为两种不同类型的进程来反映。
六、YARN 的优点
- 更快地MapReduce计算
- 对多框架支持
- 框架升级更容易

YARN
- ResourceManager 代替集群管理器
- ApplicationMaster 代替一个专用且短暂的 JobTracker
- NodeManager 代替 TaskTracker
- 一个分布式应用程序代替一个 MapReduce 作业
一个全局 ResourceManager 以主要后台进程的形式运行,它通常在专用机器上运行,在各种竞争的应用程序之间仲裁可用的集群资源。
在用户提交一个应用程序时,一个称为 ApplicationMaster 的轻量型进程实例会启动来协调应用程序内的所有任务的执行。这包括监视任务,重新启动失败的任务,推测性地运行缓慢的任务,以及计算应用程序计数器值的总和。有趣的是,ApplicationMaster 可在容器内运行任何类型的任务。
NodeManager 是 TaskTracker 的一种更加普通和高效的版本。没有固定数量的 map 和 reduce slots,NodeManager 拥有许多动态创建的资源容器。