随着数据科学在人工智能发展中大放异彩,数据挖掘、机器学习进入了越来越多人的视野。而对于很多人来说,诸如机器学习之类的名次听起来是神乎其技,但其真正的内涵却不为一般人所知。
特别是对于从事数据科学领域的人来说,如何向外行人解释自己所从事的工作几乎是一个超级难题。那么到底什么是机器学习,如何用通俗易懂的语言来解释?我们通过以下几重境界来解释。
一、专业理论型
百科定义+专业术语,让人听起来不明觉厉,实则一脸懵逼
机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
机器学习已经有了十分广泛的应用,例如:数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人运用。
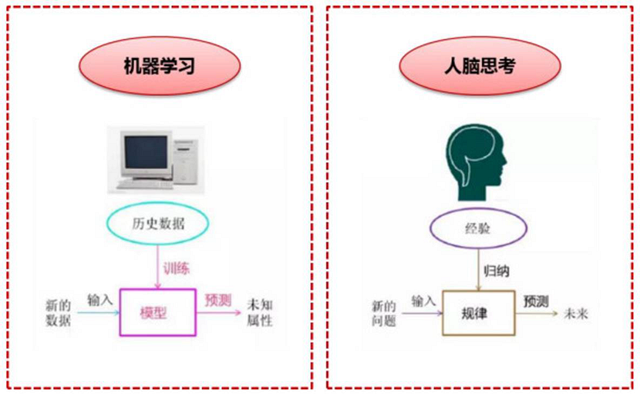
机器学习从本质上来说是一种学习结构, 整个结构包括环境、知识库和执行三个部分。 在整个过程中,环境向系统提供信息,系统利用这些信息修改知识库,以增进系统执行部分完成任务的效能,执行部分根据知识库完成任务,同时把获得的信息反馈给学习部分,从而继续改进知识库。
在具体的应用中,环境、知识和执行部分决定了具体的工作内容,学习部分所需要解决的问题完全由上述三部分确定。 简单来说,机器学习就是计算机利用已有的数据,得出了某种模型,并利用此模型预测未来的一种方法, 这与人脑的思考方式非常类似。
二、以小见大型
以某种机器学习具体的案例来说明,让人恍然大悟
一开始我们先来看一个人为设计的场景。假设一个房间里神奇地漂浮着无数个小球。我们想搞清楚这些小球停留的位置是否存在着一种特定的结构。比方说,小球是不是更易集中在某一特定区域?是不是故意避开某些点位?它们是均匀分布于整个空间吗?
但是房间一片漆黑,我们什么也看不见。于是我们找来了一部带闪光灯的照相机,想把漂浮在整个房间的小球都拍下来。照片犹如下图一样:
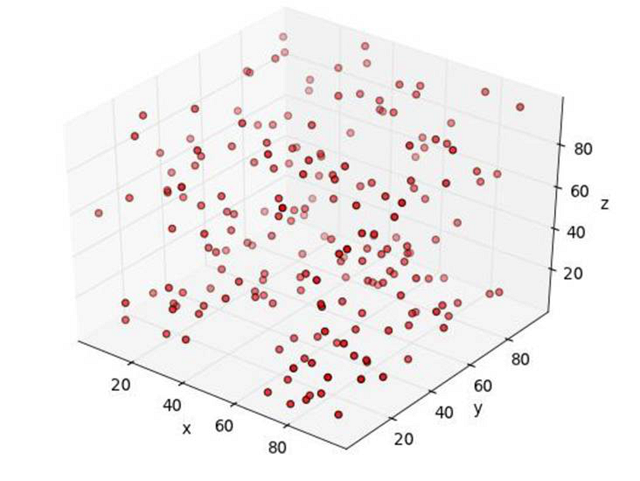
就算小球的位置之间确实存在某种联系,从这张照片上我们也看不出个所以然。看上去小球就像是均匀分布的一样。所以我们尝试着换了下位置,从新的角度拍下了第二张照片。
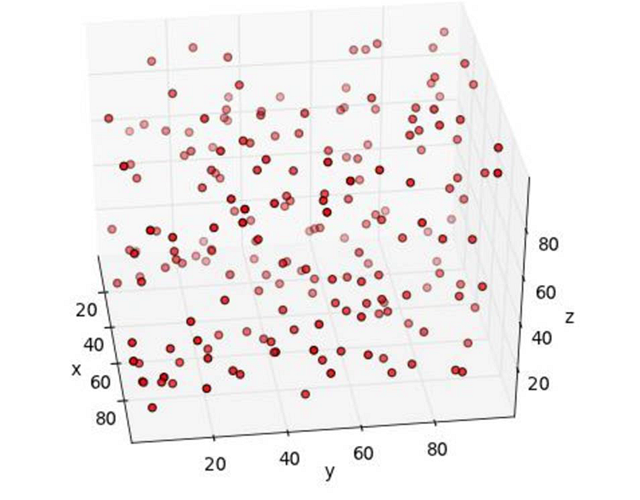
照片上的小球看起来还是随机分布的,没有任何规律。让我们换个高点的角度试试看。
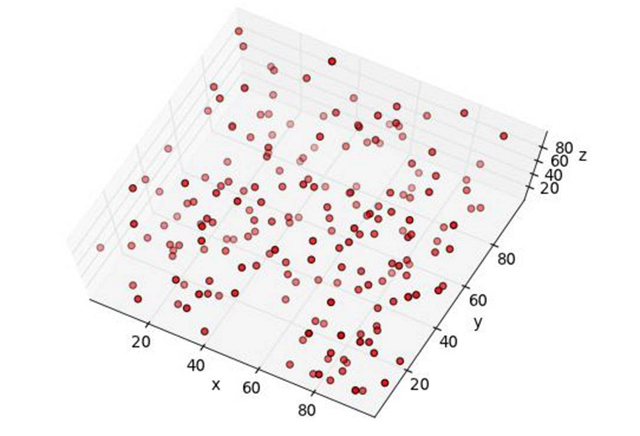
呃,还是看不出有什么规律来。那我们***再换个低点的角度试一次。
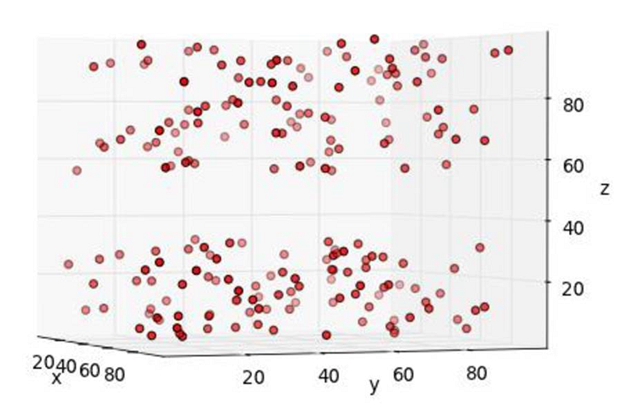
啊哈,这次有点意思了:看起来小球集中分布在靠近屋顶和地面的两个区域,中间这段没有一个小球。因此,为了发现这个规律,我们在拍照时就必须找到一个“好”的角度。如果角度不对,那我们永远都不可能找出任何规律。
在上面这个例子中,我们想说的其实是三维数据点。每个小球的位置都可以由3个数字来表示,每个数字分别代表它在XYZ三条轴上的位置。在实际的电脑运算中,数据点的位置会由更多的数字组合来表示。
比如医院病人的病历可能会包含500组数字,包括他的生日年月日、身高、体重、血压、最近一次的看病记录、胆固醇指标等等。我们会想要搞清楚不同病人的数据点之间是否存在某种规律,如心脏病人的数据点是否会集中分布?如果数据点确实会集中分布,当我们发现新入院病人的数据点也出现同样的趋势时,我们就可以推断这位病人很可能犯心脏病。当然,实际操作起来肯定不会如此简单。
一个人是不可能用肉眼看到这些数据点的。人怎么可能分得清500个维度呢?就像在上面那个例子中,没有人能看得清“黑屋”中小球,我们也同样看不见500个维度中的那些数据点。我们可以用二维图片来展示位于三维空间中的数据点,用同样的方法,我们也可以更低维度的“照片”来表现拥有500个维度的数据点。
只有从合适的“角度”拍下“照片”,我们才可以从中找出不同数据点之间的规律,不然将很难有所发现。这就是人们所说的如何从“大数据”中“发现见解”。
三、晓之以情,动之以理
这样来说,你家宠物应该都可以听明白了
买点芒果去
假设有一天你准备去买点芒果。有个小贩摆放了一车。你可以一个一个挑,然后小贩根据你挑的芒果的斤两来算钱(在印度的典型情况)。显然,你想挑最甜最熟的芒果对吧(因为小贩是按芒果的重量来算钱,而不是按芒果的品质来算钱的)。可是你准备怎么挑呢?
你记得奶奶和你说过, 嫩黄的芒果比暗黄的甜。 所以你有了一个简单的判断标准:只挑嫩黄的芒果。你检查各个芒果的颜色, 挑了些嫩黄的,买单,走人,爽不?
可事实没那么简单。
生活是很复杂的
你回到家,开始慢慢品尝你的芒果。你发现有一些芒果没有想的那么甜。你焦虑了。显然,奶奶的智慧不够啊。挑芒果可不是看看颜色那么简答的。
经过深思熟虑(并且尝了各种不同类型的芒果), 你发现那些大个儿的,嫩黄的芒果绝对是甜的,而小个儿,嫩黄的芒果,只有一半的时候是甜的(比如你买了100个嫩黄的芒果,50个比较大,50个比较小, 那么你会发现50个大个儿的芒果是甜的,而50个小个儿的芒果,平均只有25个是甜的)。
你对自己的发现非常开心,下次去买芒果的时候你就将这些规则牢牢的记在心里。但是下次再来到市集的时候,你发现你最喜欢的那家芒果摊搬出了镇子。于 是你决定从其它卖芒果的小贩那里购买芒果,但是这位小贩的芒果和之前那位产地不同。现在,你突然发现你之前学到的挑芒果办法(大个儿的嫩黄的芒果最甜)又 行不通了。你得从头再学过。你在那位小贩那里,品尝了各类芒果,你发现在这里,小个儿、暗黄的芒果其实才是最甜的。
没多久,你在其它城市的远房表妹来看你。你准备好好请她吃顿芒果。但是她说芒果甜不甜无所谓,她要的芒果一定要是最多汁的。于是,你又用你的方法品尝了各种芒果,发现比较软的芒果比较多汁。
之后,你搬去了其它国家。在那里,芒果吃起来和你家乡的味道完全不一样。你发现绿芒果其实比黄芒果好吃。
再接着,你娶了一位讨厌芒果的太太。她喜欢吃苹果。你得天天去买苹果。于是,你之前积累的那些挑芒果的经验一下子变的一文不值。你得用同样的方法,去学习苹果的各项物理属性和它的味道间的关系。你确实这样做了,因为你爱她。
有请计算机程序出场
现在想象一下,最近你正在写一个计算机程序帮你挑选芒果(或者苹果)。你会写下如下的规则:
if(颜色是嫩黄 and 尺寸是大的 and 购自最喜欢的小贩): 芒果是甜的
if(软的): 芒果是多汁的
………………
你会用这些规则来挑选芒果。你甚至会让你的小弟去按照这个规则列表去买芒果,而且确定他一定会买到你满意的芒果。
但是一旦在你的芒果实验中有了新的发现, 你就不得不手动修改这份规则列表。你得搞清楚影响芒果质量的所有因素的错综复杂的细节。
如果问题越来越复杂, 则你要针对所有的芒果类型,手动地制定挑选规就变得非常困难。你的研究将让你拿到芒果科学的博士学位(如果有这样的学位的话)。
可谁有那么多时间去做这事儿呢。
有请机器学习算法
机器学习算法是由普通的算法演化而来。通过自动地从提供的数据中学习,它会让你的程序变得更“聪明”。
你从市场上的芒果里随机的抽取一定的样品(训练数据), 制作一张表格, 上面记着每个芒果的物理属性, 比如颜色, 大小, 形状, 产地, 卖家, 等等。(这些称之为特征)。
还记录下这个芒果甜不甜, 是否多汁,是否成熟(输出变量)。你将这些数据提供给一个机器学习算法(分类算法/回归算法),然后它就会学习出一个关于芒果的物理属性和它的质量之间关系的模型。
下次你再去市集, 只要测测那些芒果的特性(测试数据),然后将它输入一个机器学习算法。算法将根据之前计算出的模型来预测芒果是甜的,熟的, 并且/还是多汁的。
该算法内部使用的规则其实就是类似你之前手写在纸上的那些规则(例如, 决策树),或者更多涉及到的东西,但是基本上你就不需要担心这个了。
瞧,你现在可以满怀自信的去买芒果了,根本不用考虑那些挑选芒果的细节。更重要的是,你可以让你的算法随着时间越变越好(增强学习),当它读进更多 的训练数据, 它就会更加准确,并且在做了错误的预测之后自我修正。但是最棒的地方在于,你可以用同样的算法去训练不同的模型, 比如预测苹果质量的模型, 桔子的,香蕉的,葡萄的,樱桃的,西瓜的,让所有你心爱的人开心:)
这,就是专属于你的机器学习,很炫酷吧。