如何进行大规模在线数据迁移
工程团队常面临一项共同挑战:重新设计数据模型以支持清晰准确的抽象和更复杂的功能。这意味着,在生产环境中,需要迁移数以百万计的活跃数据对象,并且重构上千行代码。
用户期望 Stripe API 保障可用性和一致性。所以在进行迁移时,需要格外谨慎,必须保证数据的数值正确无误,并且 Stripe 的服务始终保持可用。
本文将展示国外移动支付服务商 Stripe 如何安全地对数以亿计的 Subscriptions(订阅服务)对象进行大规模迁移。
为什么迁移困难?
1.数据规模
数以亿计的 Subscriptions 对象。在生产环境数据库上进行涉及到所有这些对象的大规模迁移会有巨大的工作量。
想象一下,迁移一个 Subscription 对象需要花费一秒钟,若以顺序方式迁移一亿个对象将花费超过三年的时间。
2.服务运行时间
商业机构持续通过 Stripe 的服务进行交易。所有的基础设施升级都是在线进行,而不依赖于有计划的维护时段。因为不能在迁移过程中中断 Subscriptions 服务,在这个迁移过程中必须要保证所有服务 100% 处于可用状态。
3.数据正确性
代码库中的很多代码都在使用 Subscriptions 数据库表。如果试图一次性修改整个 Subscriptions 服务中数以千计的代码行,那几乎肯定会忽视一些边界情况 。工程团队必须确保每项服务都能够持续获取正确无误的数据。
在线迁移的模式
将数百万个对象从旧数据库表迁移到新表是很有难度的,但许多公司需要去做这样的事情。
以下是在进行大型在线迁移中常用的 4 步”双写模式“,具体步骤是:
- 向旧表和新表双写数据以保证它们之间的数据是同步的。
- 修改代码库中所有的数据读取路径以从新表读取数据。
- 修改代码库中所有的数据写入路径以将数据只写入新表。
- 删除依赖过时数据模型的旧数据。
迁移示例:Subscriptions
什么是Subscriptions?为什么需要进行数据迁移?
Stripe 的 Subscriptions 用于帮助 DigitalOcean 和 Squarespace 这类用户构建并管理他们客户的循环计费。在过去几年中,我们稳步增加了一些功能来支持更复杂的计费模式,例如多订阅、试用、优惠券和发票。
在早期,每个 Customer 对象最多只有一个 subscription 。 customers 信息存储为单独的记录。因为 customers 到 subscriptions 之间的映射关系非常简单,所以subscriptions 信息与 customers 信息存储在一起。
- class Customer
- Subscription subscription
- end
最终,我们的用户想要具有多个 subscriptions 的 customers 。我们决定将单一的 subscription 字段转换为 subscriptions 字段,以便存储具有多个 subscription 的数组。
- class Customer
- array: Subscription subscriptions
- end
当添加新功能时,这个数据模型便出现问题了。任何对 subscriptions 的修改都会引发整条 Customer 记录的更新,以及 subscriptions 相关的查询都要通过扫描 customer 对象实现。所以我们决定将 subscriptions 独立存储。
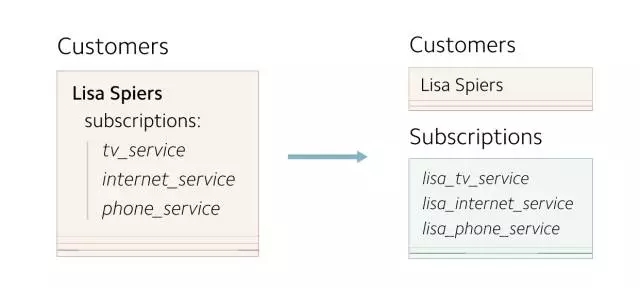
(重新设计的数据模型将 subscriptions 转移到独立的数据表中)
提醒一下,四步迁移方案如下:
- 向旧表和新表双写数据以保证它们之间的数据是同步的。
- 修改代码库中所有的数据读取路径以从新表读取数据。
- 修改代码库中所有的数据写入路径以将数据只写入新表。
- 删除依赖过时数据模型的旧数据。
下面介绍这四个步骤的具体实践。
***步:双写
创建一张新的数据库表,作为迁移的开始。***步是开始复制新数据,同时写入新旧两处存储中。之后,再将缺失的数据回填至新存储,已使两处存储具有相同的数据
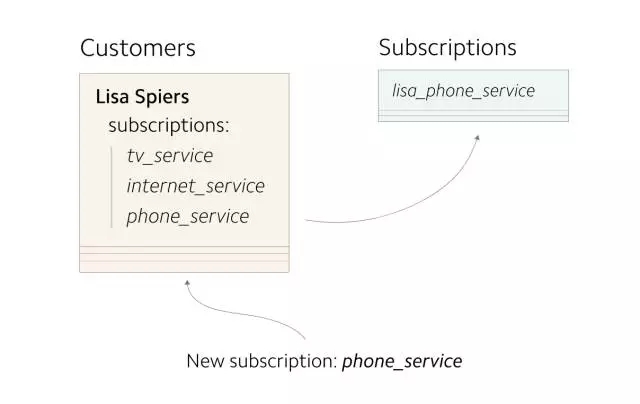
(所有新写入的数据都应更新新旧两处存储)
在 Stripe 的案例中,我们将所有新创建的 subscriptions 同时写入 Customers 表和 Subscriptions 表。在开始双写两张表之前,需要评估额外的写入操作对生产环境数据库性能的潜在影响。可以通过缓慢提高重复对象的百分比来缓解性能问题,同时持续关注系统运行指标。
进行到此时,新创建的对象已同时存在于两张表中,而旧对象只能在旧表中找到。接下来将以懒惰方式( lazy fashion )开始复制已存在的旧对象:每当对象更新时,将它们自动复制到新表中。这种方式可逐步转移已存在的数据。
***,将剩余的 subscriptions 数据回填至新表。
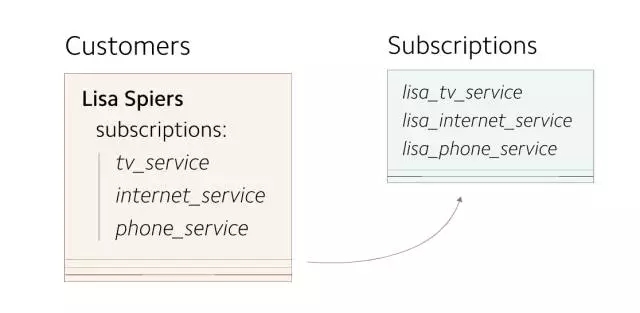
(回填已存在 subscriptions 数据至新表)
在正在对外提供服务的数据库上找到所有需要迁移的数据是回填操作中代价***的部分。通过查询数据库查找所有对象的方式将需要在生产环境数据库上执行相当多的查询操作,这将耗费很多时间。幸运的是,可以将数据从线上导入对生产环境数据库完全无影响的离线流程中。我们创建适用于我们 Hadoop 集群的数据库快照,这让我们可以使用 MapReduce 以离线、分布式的方式快速处理数据。
我们使用 Scalding 来管理 MapReduce 作业。 Scalding 是用 Scala 编写的非常实用的库,可以很容易地编写MapReduce作业(10行代码即可实现一个简单的作业)。 在这种情况下,使用 Scalding 帮助工程团队找出所有subscriptions 数据。具体步骤如下:
- 编写一份 Scalding 作业,提供所有需要复制的 subscription ID 的列表。
- 通过一组进程并行执行来大规模的复制 subscriptions 数据。
- 迁移完成后,需再次运行 Scalding 作业,以确保所有 subscriptions 数据都已存在于 Subscriptions 表中。
第二步:改变所有读操作路径
到目前为止,新旧数据表已是同步状态。下一步要做的是在新表上进行所有的读操作。
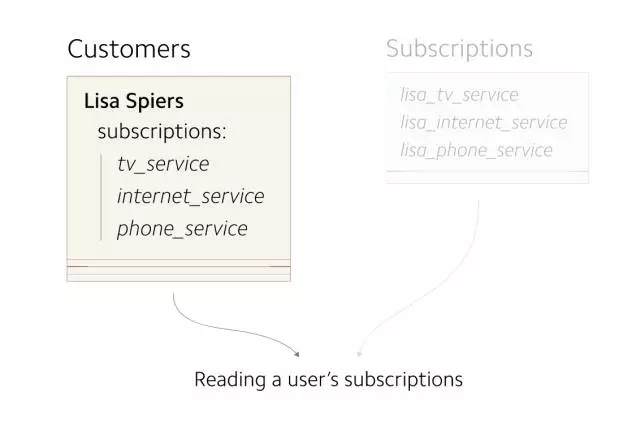
(目前,所有的读操作在 Customers 表上进行,需要将这些操作转移到 Subscriptions 表上)
需要确保从新表读数据是安全的,subscription 在新旧表中的数据应该是一致的。可以使用 GitHub 出品的 Scientist 来辅助验证读操作。Scientist 是一个 Ruby 库, 它可以让我们在生产环境运行实验,比对不同代码的运行结果并对不一致的结果发出警告 。通过 Scientist ,可实时生成针对不一致结果的警告和指标。当实验代码中发生错误,其余的应用程序是不会受到任何影响的。
实验按如下进行:
- 使用 Scientist 从 Subscriptions 表和 Customers 表同时读取数据。
- 如果读取到的数据不一致,则向工程团队发出警告。
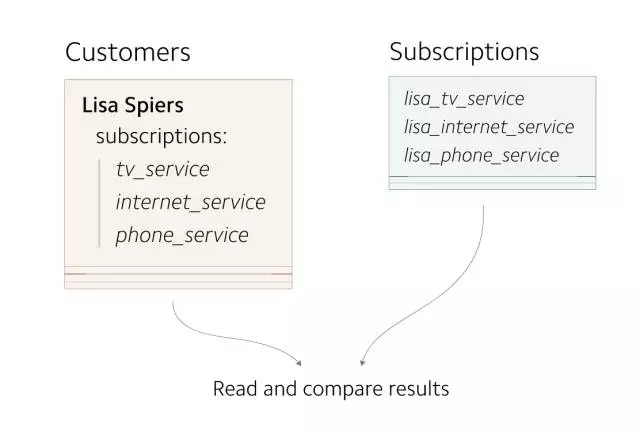
GitHub 的 Scientist 可运行读取两张表并对数据做对比的实验。
在确认所有数据是一致的后,就可以开始从新表读取数据了。
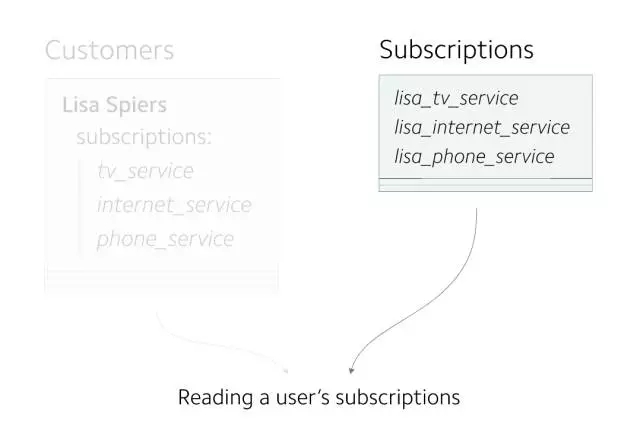
(实验成功,现在所有的读操作都在 Subscriptions 表上进行)
第三步:改变所有写操作路径
接下来,需要更新写操作路径,将数据写入新的 Subscriptions 表。 实施的目标是逐步推进这些改变,所以需要采取谨慎的策略。
直到现在,数据一直写入旧表,然后被复制到新表:

现在要颠倒这个顺序:先将数据写入新表,然后将其写入旧表中。 通过保持这两张表的一致性,我们可以进行增量更新并仔细观察每个更改。
重构 subscriptions 的所有写操作代码可以说是迁移中***挑战性的部分。 Stripe 服务中处理 subscriptions 操作的逻辑(例如更新,分期付款、续费)涉及多个服务的数千行代码。
成功重构的关键是增量处理:将尽可能多的代码路径分隔成可能的最小单元,以便可以仔细应用每个更改。 新旧两张表的数据在重构的任何一个阶段都需要保持一致。
对于每个代码路径,我们需要使用整体方法来确保我们的更改是安全的。 我们不能仅仅只使用新数据替代旧数据:每一个逻辑块都需要仔细斟酌。 如果错过了任何情况,可能就会造成数据不一致。 值得庆幸的是,可以运行更多的 Scientist 实验来提醒工程团队可能存在的任何不一致。
新的,简化的写数据路径如下所示:

可通过在调用 subscriptions 数组时触发报错的方法,确保没有代码继续使用过时的subscriptions 数组:
- class Customer
- def subscriptions
- hard_assertion_failed("Accessing subscriptions array on customer")
- end
- end
第四步:删除旧数据
***的(也是最令人满意的)步骤是移除旧的写操作代码,并最终删除。
一旦确定没有任何代码依赖过时数据模型的 subscriptions 字段,就不再需要将数据写入旧表:

随着这一变化,代码不再使用旧数据源,新数据源成为唯一数据源。
现在,可以删除所有 Customer 对象上的 subscriptions 数组,并且逐渐以懒惰的方式处理“删除”操作。 每次 subscription 被加载后,都会自动清空这个 subscriptions 数组,然后运行 Scalding 作业并迁移,以查找任何剩余的要删除的对象。 最终的数据模型如下:

结论
在保证 Stripe API 数据一致性的同时进行迁移是非常复杂的工作。安全进行这项迁移的几个要点是:
- 我们制定了一个四阶段迁移策略,可以让我们在生产环境中不停服进行数据切换。
- 使用Hadoop离线处理数据,使用MapReduce以并行方式处理大量数据,而不是依赖在生产环境数据库上执行的代价高昂的查询。
- 所做的所有更改都是渐进式的。 我们从未试图一次更改几百行代码。
- 所有的变化都是高度透明和可观察的。 Scientist 的实验只要有一条数据在生产环境中是不一致的,就立即提醒工程团队。 在整个迁移过程中,我们都对安全的迁移怀有信心。
我们发现这种方法在我们执行过的许多在线数据迁移中都很有效。我们希望这些实践做法对于其他团队进行大规模迁移也是有帮助的。