索引是一个拥有自己唯一存储的对象,它为集合提供了一条快速访问路径。索引的存在主要是为了提高性能,因此,在优化MongoDB性能时,有效理解和使用索引是非常重要的。
1、B-树索引
B-树索引是MongoDB的默认索引结构。以下是B-树索引结构高等级的概述。
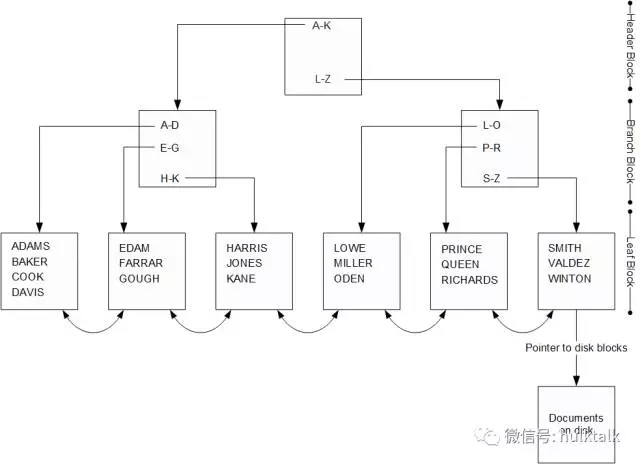
B-树索引具有分层树结构。树顶部是头部块。此块包含指向任何给定范围的键值的适当分支块的指针。分支块通常会指向适当的叶子块以获得更具体的范围,或者对于更大的索引,则指向另一个分支块。 叶子块包含一个键值列表和指向磁盘上文档位置的指针。
查看上面的图,让我们想象一下MongoDB如何遍历这个索引。 如果我们需要访问“BAKER”的记录,我们首先会查阅头部块。 头部块会告诉我们,从A到K开始的键值存储在最左边的分支块中。 访问这个分支块,我们发现从A到D开始的键值存储在最左边的叶子块中。 咨询这个叶子块,我们发现值“BAKER”以及它关联的磁盘位置,我们将用它来获得有关的文件。
叶子块包含前一个和后一个叶子块的链接。 这允许我们以升序或降序扫描索引,并且允许使用$gt或$lt操作符的范围查询使用索引进行处理。
与其他索引策略相比,B-树索引具有以下优点:
- 由于每个叶子节点处于相同的深度,所以性能是非常可预测的。 从理论上讲,集合中的任何文档都不会超过三或四次I/O。
- B树为大型集合提供了良好的性能,因为深度最多为四个(一个头部块,两个分支块级别和一个叶子块级别)。 一般来说,没有任何文件需要四个以上的I/O来定位。 实际上,因为头部块几乎总是已经加载到内存中,而分支块通常加载到内存中,所以实际的物理磁盘读取次数通常只有一次或两次。
- 因为与前一个和后一个叶子块的链接,所以B-树索引支持范围查询以及精确的查找是可行的。
B-树索引提供了灵活高效的查询性能。但是,在更改数据时维护B-树可能很昂贵。例如,考虑在上面的图表中插入一个键值为“NIVEN”的文档。要插入集合,我们必须在“L-O”块中添加一个新条目。如果在这个区域内有空闲空间,那么成本是很大的,但也许不会过多。但是如果块中没有可用空间会发生什么?
如果叶子块中没有空闲空间用于新条目,则需要索引拆分。必须分配新块,并将现有块中的一半条目移入新块。除此之外,还需要在分支块中添加一个新条目(以便指向新创建的叶子块)。如果分支块中没有空闲空间,则分支块也必须分割。
这些索引拆分是一项昂贵的操作:必须分配新块,并将索引条目从一个块移到另一个块。
2、索引选择性
属性或属性组的选择性是对这些属性的索引的有用性的常用度量。如果文档或索引具有大量的唯一值或重复值很少,则它们是有选择的。例如,DATE_AND_TIME_OF_BIRTH属性将非常有选择性,而GENDER属性将不会被选择。
选择性索引比非选择性索引更有效,因为它们更直接地指向特定的值。MongoDB优化器通常会使用最有选择性的索引。
3、唯一索引
唯一的索引是阻止组成索引的属性的任何重复值的索引。如果你尝试在包含此类重复值的集合上创建唯一索引,则会收到错误消息。同样,如果尝试插入包含重复唯一索引键值的文档,也会收到错误。
通常会创建一个唯一索引,以防止重复值而不是提高性能。 但是,唯一的索引文件通常非常有效 - 它们只能指向一个文件,因此非常有选择性。
4、连接索引
连接索引只是一个包含多个属性的索引。连接键的优点在于它比单个键索引更具有选择性。属性的组合将指向比由单个属性组成的索引更少数量的文档。包含find()或$match子句中引用的所有属性的连接索引将特别有效。
如果你经常查询集合中的多个文档,那么为这些文档创建一个连接索引是一个很好的主意。例如,我们可以通过Surname(姓氏)和Firstname(名字)查询people集合。在这种情况下,我们可能希望在Surname和Firstname上创建一个索引。例如:
- db.people.createIndex({ "Surname":1 ,"Firstname":1} );
使用这样的索引,我们可以快速找到people中所有匹配给定的Surname \ Firstname 组合。 这样的索引比单独的Surname索引或单独的Surname和Firstname索引要有效得多。
如果连接索引只能在所有键出现find()或$match时使用,则连接索引的使用可能会非常有限。幸运的是,连接索引可以非常有效地使用,提供任何初始或主要属性。主要属性是在索引定义中最早指定的属性。
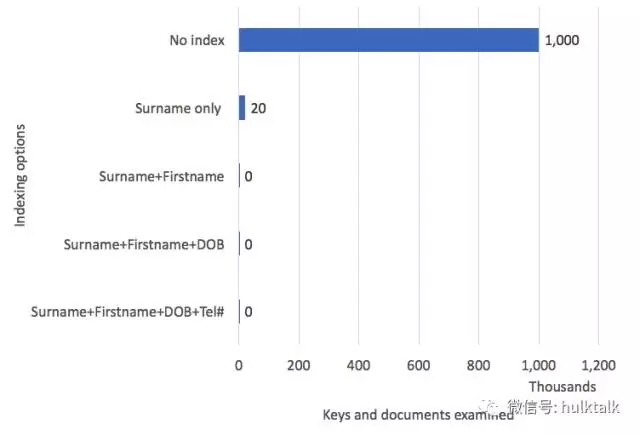
上图显示了将属性添加到连接索引时获得的改进。涉及的查询是在一个1,000,000个文档的people集合上:
- db.people.find(
- { Firstname: "KAREN",
- Surname: "SMITH",
- dob: ISODate("2006-01-21T05:55:32.520Z")
- },
- { _id: 0, tel: 1 }
- );
例如,我们通过提供Surname,Firstname和dob来检索电话号码。
全面集合扫描要求我们访问所有1,000,000个文档。仅索引surname就减少到20,028个文件 - 实际上是收集中的所有“SMITHS”。添加firstname将文档数减少到188个。通过添加dob,我们只需可以访问两个:访问一个索引条目并从那里访问集合以获取电话号码。 ***的优化是添加电话号码tel属性。 现在我们根本不需要访问集合 - 我们需要的就是索引。 这有时被称为“覆盖”指数。
请注意,覆盖索引通常要求查询包含一个投影,以消除索引中包含的属性以外的所有属性。
5、连接索引指南
以下指南将有助于确定何时使用连接索引,以及如何确定应包含哪些属性以及按何种顺序。
- 在集合中为find()或$match条件一起出现的属性创建连接索引。
- 如果属性有时会以find()或$match的形式出现,请将它们放在索引的开头。
- 如果连接的索引还支持不是所有属性都被指定的查询,则连接索引更有用。 例如,createIndex({"Surname" : 1, "Firstname" : 1})比createIndex({"Firstname" : 1, "Surname" : 1})更有用,因为只针对surname的查询比仅针对firstname的查询更有可能发生。
- 属性越有选择性,在索引的前端越有用。但是,请注意,WiredTiger索引压缩可以从根本上缩小索引。当领先的列较少选择时,索引压缩更有效。所以如果属性的顺序不是由前面三个考虑因素决定的,你可能不得不尝试索引顺序。
总结
在MongoDB的优化过程中,只有深入理解内部的索引机制,我们才能更好的提升MongoDB的性能。