2017年,在移动应用的深度学习方面取得了一些重大进展。2017年4月,谷歌发布了轻量级神经网络MobileNets。2017年6月,苹果公司发布了Core ML,支持在移动设备上运行机器学习模型。除此之外,最近发布的一些高端设备配备了GPU,它们运行机器学习甚至比MacBook Pro还要快。

深度学习已经无处不在。在这篇文章里,我将会介绍深度学习在现实世界中的应用情况,并见识一下它们的速度到底有多快。
MobileNets应用
我们最近开发了一种新的深度神经网络,叫作MobileUNet,用于解决语义切分问题。它的设计极其简单,它在U-Net中使用了MobileNets。这里只列出其中关键的点,更多细节可以参考它的GitHub仓库。
- 它由编码器和解码器组成。
- 编码器使用了MobileNets,缺少用于分类的全连接层。
- 解码器使用卷积转置进行升采样(upsample)。
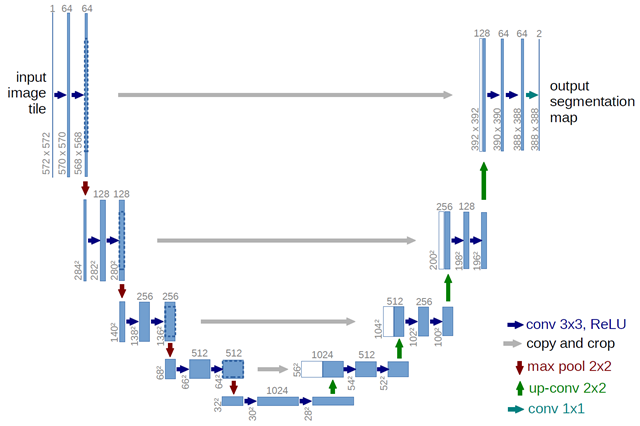
在开发该项目时,我们主要关心它的推理速度。我们知道深度神经网络在GPU上跑得更快一些,但如果运行在移动设备上会怎样呢?
这也就是为什么我们使用了MobileNets。
- 它使用深度卷积块(depthwise conv block)来加快推理速度。
- 它具有更高的准确性和推理速度比率。
- 它提供了一些参数用于在准确性和速度之间做出权衡。
我们可以得到较为理想的结果,如下图所示。
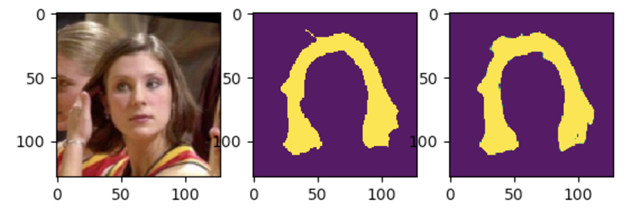
速度与准确性
在介绍MobileUNet的性能之前,我想先澄清几个一般性的概念。
是否所有的卷积(如Conv2D、DepthwiseConv2D和Conv2DTranspose)在不同的处理器上都有相同的速度表现?
答案是否定的。在不同的处理器上,有些操作会很快,有些会很慢。CPU和GPU之间的区别是很容易区分出来的,即使是不同的GPU之间也存在优化差异。
下图展示了普通的卷积块和深度卷积块之间的差别。
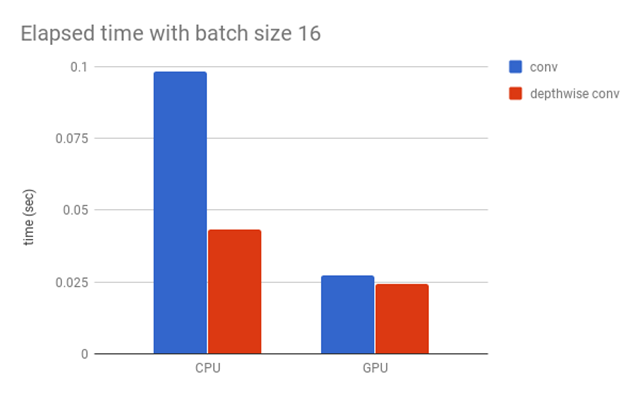
深度卷积块和普通卷积块在CPU上的表现差别很大,但在GPU上的差别却小了很多。
因此,如果你想要发布基于移动设备的深度学习应用,最好先在主流的设备上做一下测试。接下来,我要分享一下MobileUNet的各种指标。
我们主要使用了以下几个设备。
- iPhone 6 Plus
- iPhone 7 Plus
- iPhone 8 Plus
- Sony Xperia XZ(骁龙820)
MobileNets提供了一个叫作alpha的参数用于控制速度和准确性之间的比率,所以我们也在MobileUNet里使用了这个参数。我们选择了4个alpha值(1、0.75、0.5和0.25)和4种尺寸的图像(224、192、160、128)。
下图是速度对比。
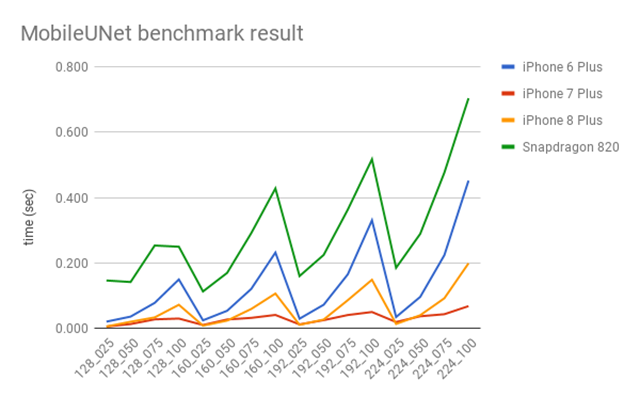
让人感到惊讶的是,速度最快的并不是iPhone 8 Plus,而是iPhone 7 Plus。iPhone 7 Plus真的很快,在实时应用方面完全没有问题。iPhone 6 Plus和骁龙820就没那么快了,特别是当alpha值很大的时候就更慢了。
下图是准确性对比。
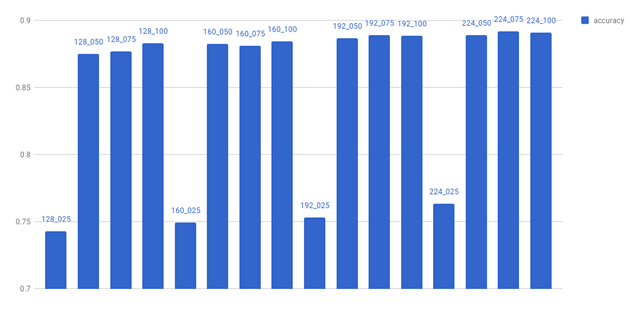
在alpha达到0.25时,准确性开始急速下降。准确性随着alpha的值和图像尺寸呈线性下降。所以,我们不使用alpha 0.25这个值。
下图展示了在骁龙820上运行的速度和准确性。
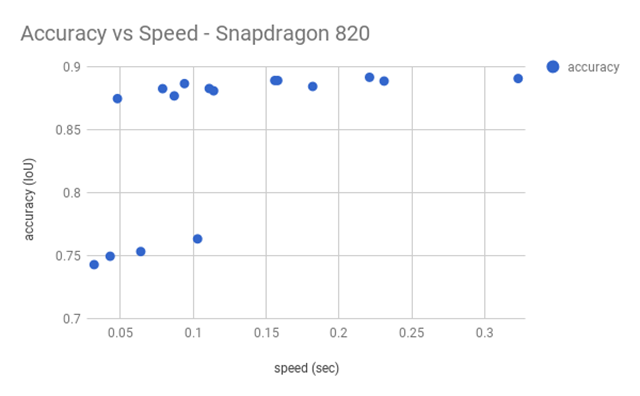
如果速度对于我们来说很重要,那么就可以考虑左上角那个,尺寸为128,准确性为0.875 IoU,alpha值为0.5。如果更看重准确性,那么可以选择尺寸为192、alpha值为0.5的那个。
当然,我们也可以为不同的设备使用不同的模型,但这样会增加复杂性。
现在让我们来看看为什么iPhone 7 Plus会比iPhone 8 Plus更快。
之前已经说过,速度取决于每个处理器。iPhone 7 Plus的GPU比iPhone 8 Plus的GPU更加契合我们的神经网络,为此我做了一个实验。
我们将MobileUNet的编码器和解码器分为不同的部分,并测试它们的性能。
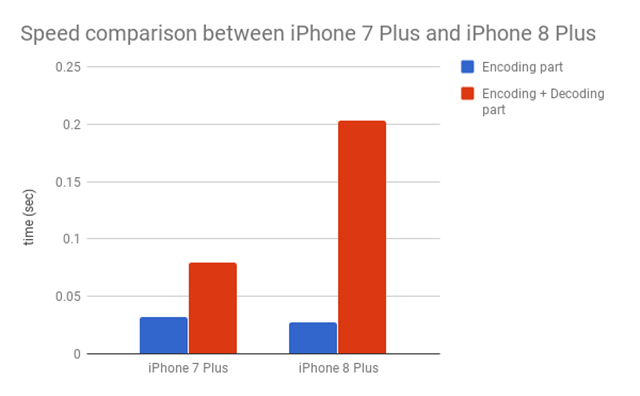
很明显,解码器部分是iPhone 8 Plus的瓶颈所在。我们在解码器中使用了Conv2DTranspose,iPhone 7 Plus的GPU针对Conv2DTranspose进行过优化,而iPhone 8 Plus则没有。
用于基准测试的脚本放在了Gist上。
结论
在移动设备上使用深度学习已经成为一种趋势,在不久的将来,深度学习的应用会越来越方便。
但不是所有的设备都配备了高端GPU,所以进行性能调优是很有必要的。因为不同的处理器具有不同的特点,所以一定要使用真实的设备进行性能测试。
性能测试本身并不难,甚至不需要使用训练过的模型,我们完全可以使用未训练的模型找出性能的瓶颈。