在因式分解(factorization)的基础上,基于循环神经网络(RNN)的语言模型在多项基准上都达到了当前***的水平。尽管 RNN 作为通用近似器有出色的表达能力,但点积和 Softmax 的组合是否有能力建模条件概率(会随语境的变化而发生巨大的变化),这个问题还没有得到清楚的解答。
在这项工作中,我们从矩阵分解的角度研究了前面提到的基于 Softmax 的循环语言模型的表达能力。我们表明使用标准公式学习基于 Softmax 的循环语言模型等价于求解矩阵分解问题。更重要的是,因为自然语言高度依赖于语境,所以被分解的矩阵可能是高秩的(high-rank)。这进一步表明带有分布式(输出)词嵌入的基于标准 Softmax 的语言模型没有足够的能力建模自然语言。我们称之为 Softmax 瓶颈(Softmax bottleneck)。
我们提出了一种解决 Softmax 瓶颈的简单且有效的方法。具体而言,我们将离散隐变量(discrete latent variable)引入了循环语言模型,并且将 next-token 概率分布形式化为了 Mixture of Softmaxes(MoS)。Mixture of Softmaxes 比 Softmax 和以前的研究考虑的其它替代方法有更好的表达能力。此外,我们表明 MoS 可以学习有更大的归一化奇异值(normalized singular values)的矩阵,因此比 Softmax 和基于真实世界数据集的其它基准有高得多的秩。
我们有两大贡献。首先,我们通过将语言建模形式化为矩阵分解问题而确定了 Softmax 瓶颈的存在。第二,我们提出了一种简单且有效的方法,可以在当前***的结果上实现显著的提升。

论文地址:https://arxiv.org/pdf/1711.03953.pdf
摘要:我们将语言建模形式化了矩阵分解问题,并且表明基于 Softmax 的模型(包括大多数神经语言模型)的表达能力受限于 Softmax 瓶颈。鉴于自然语言高度依赖于语境,这就进一步表明使用分布式词嵌入的 Softmax 实际上没有足够的能力来建模自然语言。我们提出了一种解决这一问题的简单且有效的方法,并且在 Penn Treebank 和 WikiText-2 上分别将当前***的困惑度水平改善到了 47.69 和 40.68。
在 PTB 和 WT2 上的语言建模结果分别在表 1 和表 2 中给出。在参数数量差不多的情况下,MoS 的表现超越了所有使用了或没使用动态评估(dynamic evaluation)的基准,并且在当前***的基础上实现了显著的提升(困惑度改善了高达 3.6)。

表 1:在 Penn Treebank 的验证集和测试集上的单个模型困惑度。基准结果是从 Merity et al. (2017) 和 Krause et al. (2017) 获得的。† 表示使用了动态评估。
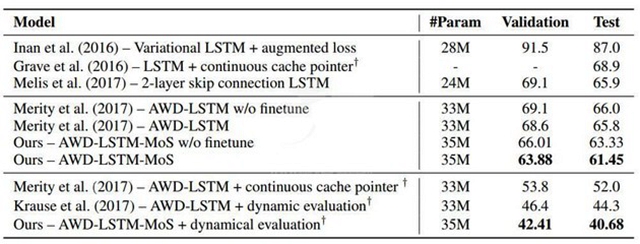
表 2:在 WikiText-2 上的单个模型困惑度。基准结果是从 Merity et al. (2017) 和 Krause et al. (2017) 获得的。† 表示使用了动态评估。
为了进一步验证上面所给出的改善确实源自 MoS 结构,而不是因为增加了额外的隐藏层或找到了一组特定的超参数,我们在 PTB 和 WT2 上执行了 ablation study(是指移除模型和算法的某些功能或结构,看它们对该模型和算法的结果有何影响)。

表 3:在 Switchboard 上的评估分数。
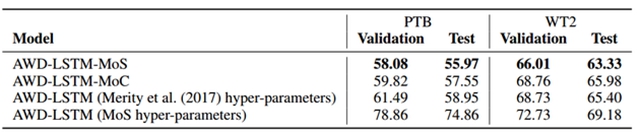
表 4:在 Penn Treebank 和 WikiText-2 上的 ablation study,没有使用微调或动态评估。
我们绘制了归一化的奇异值的累积百分比,即归一化的奇异值低于某个阈值的百分比。
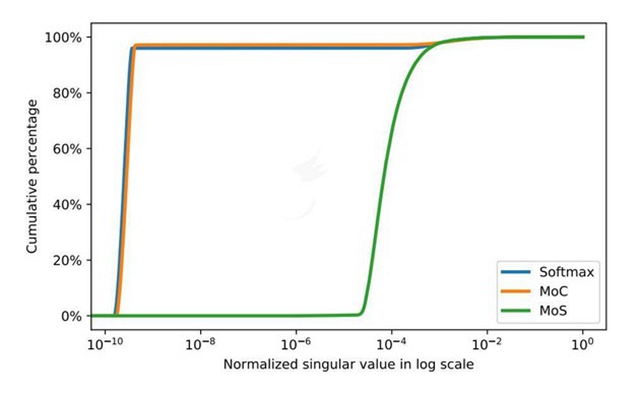
图 1:给定 [0,1] 中的一个值,归一化奇异值的累积百分比。