架构设计中,大家都不喜欢耦合,但有哪些典型的耦合是我们系统架构设计中经常出现的,又该如何优化?
这里列举了 6 个点:IP、jar 包、数据库、服务、消息、扩容。
这些点,如果设计不慎,都会导致系统出现一些耦合问题,基本都是大家实际遇到的痛点。本文将与大家分享如何用常见的方案去解除这些耦合。

如何找到系统中的耦合
什么是耦合?就是每每我们作为技术人,在心中骂上下游、骂兄弟部门,说这个东西跟我有什么关系?为什么我要配合来做这个事情?这里面就非常有可能是系统中存在耦合的地方。
明明我们不应该联动,但兄弟部门要做一个事情,上下游要做一个事情,我却要被动地配合来做这个事情。还有可能这个配合的范围特别特别的大,那就说明耦合非常非常的重。
下面来看具体的六个案例。
典型耦合与对应解耦实践
IP 耦合
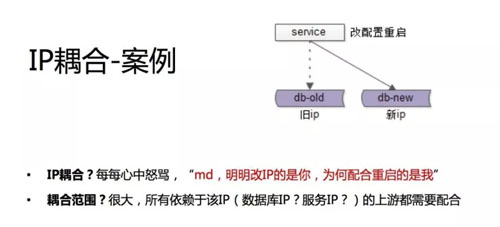
第一个案例,特别常见。原来线上有服务或者有条数据库,因为各种原因,例如磁盘硬件有故障,要换一台机器,然后运维给了我们一台机器,我们把数据库或者把服务给部署好了。
部署好了 IP 要换,原来有个旧 IP,现在有个新 IP。那就有很多上游依赖我,我 IP 换了怎么办?就找到上游说我的 IP 换了,麻烦上游部门改配置重启一下,连到我新的 IP 上去。
不知道大家工作中会不会遇到这样的场景,这时如果你作为上游的调用方,不管你调数据库还是调服务,你心里可能就在骂他了,明明是你 IP 变了,为什么配合重启、配合改配置的人是我?
特别是如果一个基础服务或者一个基础数据库,依赖它的人很多,那么你可能要找到这些依赖它的人,可能有 A 部门、B 部门、C 部门,所有业务都依赖你,你要全部找一遍,全部重启。
所以这个因为 IP 配置使得上下游耦合在一起的案例,它的耦合范围其实是非常广的,我们都觉得很讨厌。
我们的希望是:你改一个 IP,能不能我不动,你自己升级了,我流量就默默迁移过去,这是一个非常直观的理解上下游的耦合。
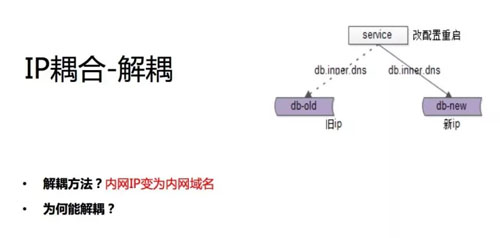
内网 IP 修改为内网域名,这是我们的实践,强烈的建议大家回去马上干这个事情。为什么我们 IP 要修改、要重启?
很有可能是我们将 IP 写在了自己的配置文件中。如果我们把这个内网 IP 变为内网域名,那么我们是不是就可以不让上游配合去改配置重启呢?
假设我们现在不用 IP 了,用域名了。现在换了一台机器域名没变,IP 指向变了。我们可以让运维统一将内网 DNS 切到新的机器上面去,并将旧机器的连接切断,重连后就会自动连到新机器上去了。
这样的话只要运维配合就可以完成迁移,对于所有上游的调用方、服务的调用方、数据的调用方都不需要动,这是第一个案例。
我们的最佳实践是强烈建议使用内网域名来替换内网的 IP,连服务、连数据库统统取走。
公共库耦合
第二个案例是公共库,这个公共库可能是一个跟业务相关的通用业务库,比如用户的业务、支付的业务,这些业务写在了一个 jar 包里,各个业务线通过这个 jar 包来实现相关的一些业务逻辑。
所有的业务方因为这个公共库耦合了,不管你是 so、dll,还是 jar 包代码,不同语言的公共库方式不一样,本质是上游通过这个公共库耦合在一起。
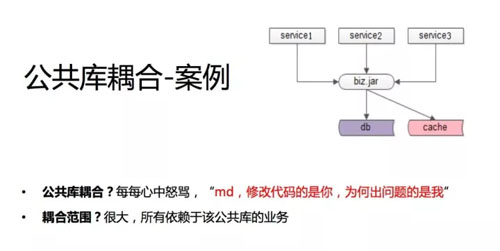
我们曾经碰到什么样的情况呢?58 有招聘、房产、二手很多业务线,用户的一些操作,登录、查询信息、修改信息可能都是相通的,所以我们有一个 user.jar,对所有用户的操作可能通过这个 jar 包去做。
然后有个业务线,比如说招聘,他可能修改了用户的操作的一些代码,修改了这个 jar 包。
修改之后,上线之前会进行测试,但招聘只会测试自己的业务,不会测试兄弟业务线的业务,导致上线的结果是,上线后兄弟业务线全挂了。
于是就出现了一个很有意思的场景, A 和 B 的业务老大在群里面说怎么业务都挂了,然后有研发兄跳出来解释说 C 部门上线了,所以我们都挂了,这个解释是很难说通的。
为什么兄弟部门好好的,他上线了他没问题,而我们挂了,就是因为 jar 包耦合在一起,可能我们也在心里会默默地骂他们,修改代码的是你,没问题的也是你,有问题的是我,我其实什么都没动,我很委屈。
多个上游因为 jar 包耦合在了一起,那有什么样的优化方法?
如果代码库个性很强
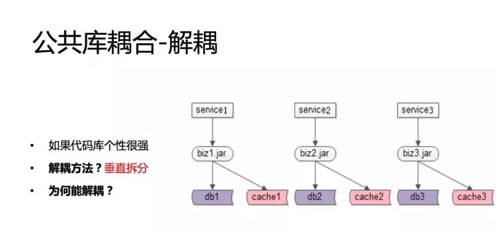
如果这个 jar 包、这个公共库的个性比较强,如果是偏招聘的、房产的、二手的,我们的建议是把这些个性的代码拆分到各个业务线自己的 jar 包里面去。
这样的话,你修改的那一块只影响你自己,至少不会扩大影响范围,这个需要对业务进行剖析,把个性的地方拿出来。
如果长时间解决不了,我刚刚说的那种耦合频发,出现的次数特别多,最差的情况下我们可以 copy 代码,比如说拷三份,但这个不推荐。
我们的建议:还是抽取其中的个性部分,把原来的一个 business 的 jar 包变成三个加包,每一块只跟一块业务相关。
如果公共库通用性很强
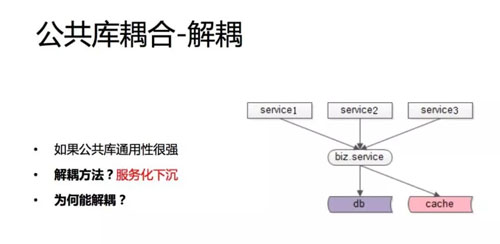
那如果这个库的共性比较强,我们建议通用的部分下沉独立一个 service,这个 service 对上游提供接口,我每次测试你也要测试接口的兼容性。
如果是新的业务,我们建议新增接口,这样至少不会对旧有的代码产生影响,通过 service 或 RPC 调用的方式来解除耦合。
数据库耦合
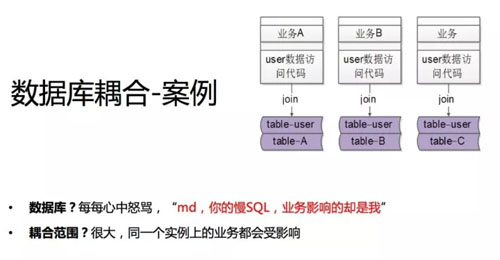
第三个案例应该也是大家会遇到比较多的情况,数据库的耦合。
我先说一下业务场景:业务 A、业务 B、业务 C,这里还是拿用户的业务举例,有些用户的数据是通用的,存在 table-user 里,而个性的数据我们存在个性的数据库里。
比如业务 A 我们可能有个 table-A、业务 B 有 table-B、业务 C 有 table-C。
假设我的业务线既要取个性的数据,又要取共性的数据,我们的代码往往这么写,个性表 join 个性表,UID 相同,UID 等于我的用户 1、2、3,个性的数据和共性的数据一起抽取出来,没有任何问题。
业务线 B、业务线 C 也是这么做的。所以你会发现 join 语句其实导致了 user 的 table 和业务线 A、B、C 的 table 耦合到一个数据库实例里。
这样会导致什么问题呢?比如 A 业务线要上线一个功能,这个功能没有索引,对全表都要扫描,数据库 CPU 100%,数据库实例 IO 性能下降,影响业务。
对B 和 C 都有影响,即某个业务线的数据库性能急剧下降导致所有业务都受影响。
这时 DBA 兄弟、运维兄弟杀过来说性能不行了,我再给你两台机器,给我两个实例,你会发现没用,所有表都耦合在一个实例里,给机器也拆不开,扩不了容。
2015 年我调去 58 到家时,当时整个 58 到家有一个库叫做 58 到家库,里面有几百个表,性能越来越低,但因为各种 join 又必须耦合在一个实例里,很悲惨。
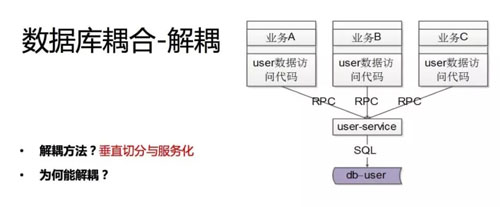
我们怎么做呢?垂直切分与服务化。你会发现跟 jar 包解耦非常相似,垂直拆分。
比如说用户的基础数据,我抽向一个用户的服务,user 最基础的数据库只能够被这个服务锁访问,数据库私有是服务化的一个特点。
此时业务线原来的业务怎么样满足?原来是业务方直接一个 join 既取了共有的数据又取了私有的数据,此时原来的一次数据库访问变成了两次数据库访问,第一次取个性数据,第二次取共性数据,然后业务层拼装。
之前的方式和之后的方式相比,之前的方式业务代码可能会更简单一些,因为它是将这个业务逻辑放在了 SQL 语句中,但是导致数据库耦合在了一起。
后面这种方式就是业务的代码会更复杂,会变成多次访问,将原来在 SQL 中进行的逻辑计算变成我们自己的代码的逻辑计算。
此时业务有自己的库,公共有公共的库,你会发现很有可能这些库早期也在一个实例,但是性能下降时可以很容易地新增实例,把其中一个公共的库从一个实例里放到另外一个实例,甚至新增一台机器做到硬件的扩容。
所以垂直切分是指业务侧自己的数据库放到自己的上去,公共的放到公共的上去,不要耦合在一个实例当中,这是一个比较典型的业务场景。
服务化耦合
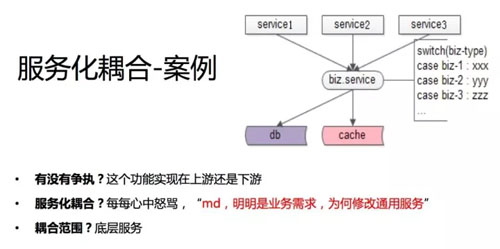
第四个案例是服务化耦合的例子。服务化之后,如果业务代码拆分得不干净,即使你做了服务化也不能够解除耦合。这里举一个服务化解耦不彻底的案例。
上面是 ABC 三个业务方,底下是一个通用的服务。假如你解耦不彻底,你这个通用的服务里有业务侧的代码,最典型的业务侧的代码是什么样的?
即服务层 switch case,根据调用方的类型走不通的业务逻辑代码。我们做服务化其实是想把共性的部分抽象下沉,是共性的部分会做的服务。但如果解耦不彻底,就会有传入不同 biz-type 执行不同逻辑这样的代码。
这会出现什么问题呢?如果新增业务需求,你会发现很有可能要改代码的是底层的服务,比如说业务 1 来了一个需求,他过来找到你,说我这个需求有个扩展,麻烦你这边升级一下。
业务 2 和业务 3 相同,明明有需求的是业务方,为什么修改代码的是我底层呢,业务需求方很多,所有业务需求侧都是你来实现,你是忙不过来的。这时你可能在心中骂他。
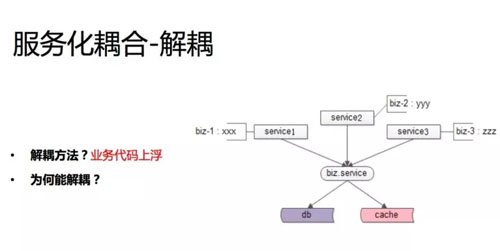
这个的耦合范围相对较小,因为只有一个基础服务维护的痛点。解决方案也很容易想到,当然是把业务个性化的 case 分支搬到上游去,底层只做通用的功能。
业务代码上浮,这样的话上游的业务迭代速度、迭代效率会提升,每块业务有功能就会自己实现了,不需要兄弟部门去实现,没有一个沟通的过程。这是服务化不彻底的一个常见的耦合的案例。
消息通知耦合
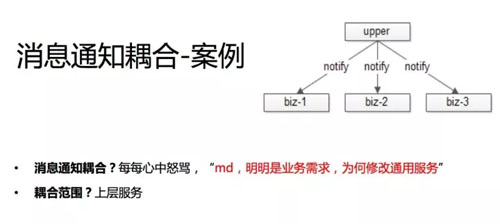
第五个案例是消息通知的耦合。我猜应该也有很多公司遇到过,有一些事件,这个事件可能要让很多下游知晓,这里举一个我们曾经出现过的案例。
58 同城发布帖子,发布帖子的这个事件可能要周知很多方,例如有一个用户分级的服务,他发了帖之后,这个用户发帖的一些统计数据,一些信息数据可能要进行更新。
还要通知离线消息反作弊的部门在发布这个帖子之后,可能做一些离线的分析和处理,看有没有反作弊的嫌疑。
甚至我们这个消息可能要通知业务线,比如说招聘业务线,最近做了一些营销活动,只要发招聘的帖子就给你奖积分。
帖子发布服务,这本来应该是一个非常基础的服务,它是否要承担将帖子消息同步给通知关注方的职责呢?
最早我们是怎么实现的?58 同城都是服务化的架构,通过 RPC 告诉你发布一个帖子。
所以我们的上游是帖子发布的基础服务,他会通知反作弊的部门说发了一个帖子,会通知数据统计的部门发个帖子,会通知业务线说发个帖子,这样的架构其实是因为这个通知上下游耦合在了一起。
然后我们在什么时候会偷偷地去骂这个下游呢?假设现在又新增了一个业务线,房产业务线也做营销活动,也要关注帖子发布,麻烦发布的兄弟能不能调用一下我。
发布的兄弟会发现改的是发布服务的代码,他原来要调 123,他现在还要调 4,有人有新增的需求还要调 5。发布服务的工程师很痛苦,明明有需求的是业务方,但修改代码的却是我。
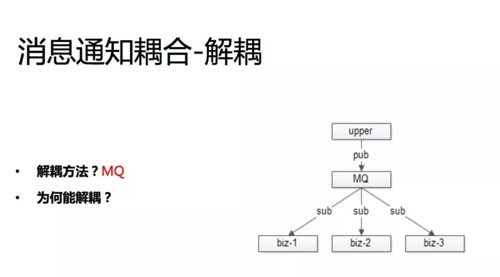
原因就是消息的上下游耦合在一起。非常常见的解耦方案是通过 MQ,这个案例里的 MQ 以及下一个案例里的配置中心是互联网架构中两个非常常见的解耦工具。
MQ 能够做到上下游物理上和逻辑上都解耦,增加 MQ 之后,首先上游互不知道彼此的存在,它当然不会建立物理连接了,大家都与 MQ 建立物理连接,就是物理连接上解耦了。
逻辑上也解耦了,消息发布方甚至不用知道哪些下游订阅了这个消息。新增消息的订阅方只需要找 MQ 就行了,上游不需要关注。
所以 MQ 是一个非常常见的物理上解耦、逻辑上也解耦的利器。
下游扩容耦合
第六个案例,我相信也几乎是所有的公司都会遇到的一个案例,它和第一个案例很像,但又不一样。
我们的第一个案例是说 IP 变化,上游调下游 IP 发生了变化,我们的建议是使用内网域名,而不是 IP 来做配置,来做上下游的连接解耦。
扩容换 IP 是一个场景,扩容又是第二个场景。
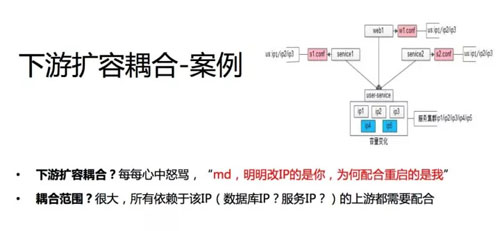
现在有 service1、service2、Web1,底层的 service 是个集群,随着业务、数据量、并发的增长,service 要扩容了,我要新增两个节点。
假设我要新增 IP4、IP5,你会发现案例一的场景又出现了,你得通知所有的上游麻烦帮忙增加两 个IP,增加两个内网域名,因为我扩容了。扩容的明明是下游,但需要修改配置、需要重启的是上游。
我们早期的解决方案是怎么样的?我们对配置采用的是配置私藏的方式。
一般对于每个上游来说,都有个自己的配置文件,依赖于下游,这个配置文件会放在上游的配置文件里。
service2 一般有一个配置 conf,这个里面写了依赖于内网配置,内网域名是 123,然后这个服务在启动时可能通过配置把这个连接建立上。
Web 也是一样,它有一个 Web1.conf,大家想想自己所服务的公司是不是这样的。
它是一个数据的扩散,本来数据在这一份,但是你会发现这个数据扩散到不同的上游,每个人都存储一份这样的数据,我这个数据要变动时每个上游都需要变动。
如果数据只存在一个地方,这一个地方变了就都变了,不用担心数据的一致性。
如果你能够知道上游是谁,通知你的上游去为用户改善配置重启还好,我们碰到的痛点是什么?
58 同城几千号人,业务几百个,那么多,我不知道谁依赖了我,如果我能知道 123 依赖了我,那我就告诉你就行了。
现在我不知道谁依赖了我,因为你连接我,你不需要经过我的允许,你在手册上看调用方式是什么就看懂了。我们会增加 IP,我怎么通知你?
刚刚说根本的原因其实是一份配置数据扩散到了多个上游,那我们能不能将这个配置数据放在一个地方不扩散,我改了这一个地方就都改了?
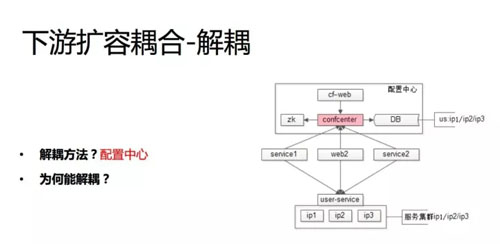
解决方案是配置中心,配置中心的细节我在这不展开讲,网上可能也有一些公司的实践,配置后台、DB 存储等。
配置中心是一个典型的逻辑上解耦、但物理上不解耦的一个架构工具。我们的所有上游依赖于下游,还要建立物理的连接。
你引入配置中心之后,它不是通过私有的配置,也不是通过全局的配置文件去读取下游的 IP,而是配置中心说我要访问 user service。
配置中心告诉他 user service 的内网域名是 123,service 的 1、2、3 还是按照内网的 1、2、3,物理上还是连接 user service,所有的上游都按照这种方式读取下游的配置。
在配置中心侧,他就能够知道有哪些人连接了 user service,他在配置中心的后台就可以配哪些人我设置多少的限流,然后将这个限流可以同步到调用方的客户端,当然也可以同步到服务端进行双向的保护。
如果 user service 进行扩容,比如我要增加几个节点,我增加了 4 和 5,那么我在配置后台说增加了 4 和 5,后台能够知道哪些上游依赖了它,反向给后台通知,就完全不需要上游去做了。
总结

解耦之后系统能够更美好一点,程序员心中能够少一点怨气,希望今天分享的主题及案例能够帮助大家解决一些工作中的实际问题,谢谢大家。
沈剑,架构师之路公众号作者。曾任百度高级工程师、58 同城高级架构师、58 同城技术委员会主席、58 同城 C2C 技术部负责人。现任 58 到家技术委员会主席,高级技术总监,负责 58 速运研发与管理工作。本质,技术人一枚。