












贵金属(注:贵金属为笔者部门业务)的行情系统提供的接口通过Redis获取数据,目前使用Redis最多只存储了大概8000条左右的分钟k的行情数据,考虑到将来可能会有更大数据量的查询需求,需要查询几月甚至几年的行情数据,要求数据库在提供功能的同时又能保证性能和稳定性。Redis通常只用做较小数据量的内存数据库,而传统关系数据库又有一定的查询性能瓶颈,所以考虑调研一下其它的NoSQL数据库。
一、为什么调研MongoDB?
图1-1是DB-Engines2017年11月数据库的排名统计,可以看到MongoDB总排名在第5,在NoSQL数据库中排名第1。
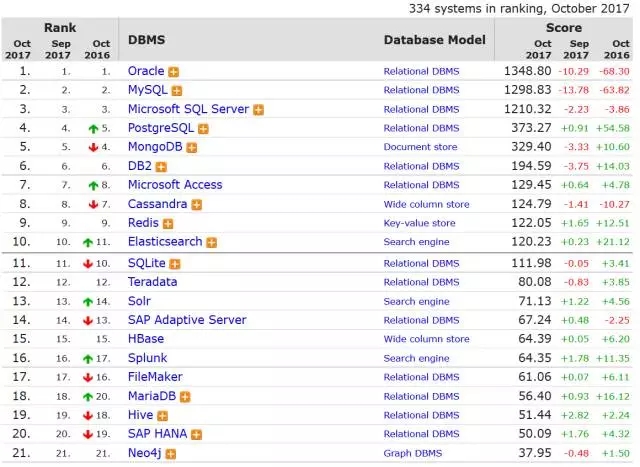
图1-1 DB-Engines2017年11月数据库的排名统计
优点:
- 社区活跃,用户较多,应用广泛
- MongoDB在内存充足的情况下数据都放入内存且有完整的索引支持,查询效率较高
- MongoDB的分片机制,支持海量数据的存储和扩展
缺点:
- 不支持事务
- 不支持join、复杂查询
初步调研下来,MongoDB具备我们需要的特性,而缺点不影响应用场景,故接下来我们就开始做实际的性能压测。
二、压测性能对比
1、准备条件
(1)MySQL 、MongoDB数据库所在服务器硬件环境

表2-1 服务器硬件环境主要参数
(2)***的数据库版本
MongoDB server version: 3.4.5
MongoDB client version: mongo-java-driver-2.14.3
MySQL server version:5.6.34
MySQL connector version: MySQL-connector-java-6.0.6
MongoDB使用的储存引擎wiredTiger
MySQL使用的储存引擎InnoDB
(3)数据库表结构及索引
MongoDB索引为dateTime 且是唯一索引。我们实际测试使用的MongoDB数据结构及字段如图2-1所示。
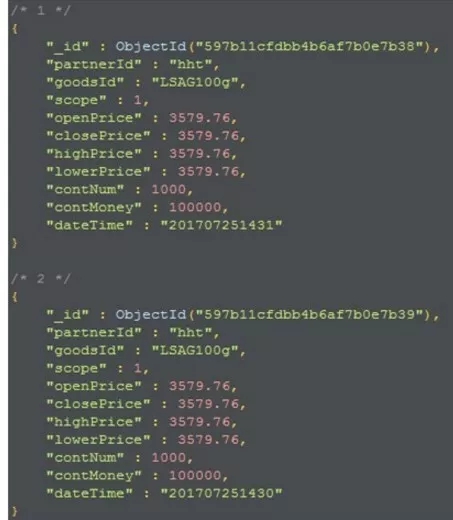
图2-1 MongoDB数据表记录示例
MySQL索引为DATETIME,PARTNER_ID,GOODS_ID,SCOPE且是唯一索引。我们实际测试使用的MySQL数据结构及字段如图2-2所示。

图2-2 MySQL数据表记录示例
SQL语句根据datetime字段进行时间范围的查询
(4)连接池***连接数都设置为200个,SQL语句调到***
2、百万、***别的下不同查询量不同并发量的压测结果
数据库表中记录数总量在百万、***别的压测数据及结果如表2-2所示。
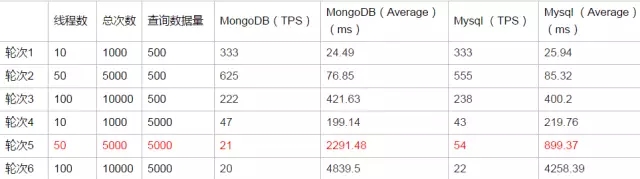
表2-2 百万、***别的压测数据及结果
3、亿级别的下不同查询量不同并发量的压测结果
数据库表中记录数总量在亿级别的压测数据及结果如表2-3所示。

表2-3 亿级别的压测数据及结果
压测结果分析:
- 当每次查询数据量在500条时,无论表中数据总量千万或者亿级别,MySQL和MongoDB在100线程并发的情况下查询性能相当,表现良好,平均响应时间在500ms以内,TPS在230左右。
- 当每次查询数据量在5000条时,表中数据总量为***别时,MongoDB在50线程并发情况下查询性能不及MySQL 的一半,100线程并发情况查询性能都很差,平均响应时间在4500ms左右,表中数据总量为亿级别时,在50个及以上的并发情况下,MongoDB和MySQL性能都较差。
在本案例简单数据模型下时间范围内的等值查询应用场景下,MongoDB在高并发条件下的大数据量查询性能并没有比MySQL更好。另外还有一点需要注意的是,在本案例中,数据总量由***别到***别再到亿级别的变化过程中,对于查询性能的影响都不是很大,但对于查询数据量的数倍增长却十分敏感,所以在考量数据库查询性能时,也要重点考量应用的单次查询量的需求。
尽管MongoDB在我们的这种应用场景下并没有达到预期的性能,我们也简单地的调研了下MySQL和MongoDB对于内存的使用机制以及一些可能影响查询效率的内部配置。
三、MySQL和MongoDB内存结构
1、InnoDB内存使用机制
InnoDB体系结构如图3-1所示。

图3-1 InnoDB体系结构
压测MySQL使用的是InnoDB存储引擎,InnoDB关于查询效率有影响的两个比较重要的参数分别是innodb_buffer_pool_size,innodb_read_ahead_threshold。
innodb_buffer_pool_size指的是InnoDB缓冲池的大小,本例中InnoDB缓冲池大小为20G,该参数的大小可通过命令指定innodb_buffer_pool_size 20G。缓冲池使用改进的LRU算法进行管理,维护一个LRU列表、一个FREE列表,FREE列表存放空闲页,数据库启动时LRU列表是空的,当需要从缓冲池分页时,首先从FREE列表查找空闲页,有则放入LRU列表,否则LRU执行淘汰,淘汰尾部的页分配给新页。
innodb_read_ahead_threshold相对应的是数据预加载机制,innodb_read_ahead_threshold 30表示的是如果一个extent中的被顺序读取的page超过或者等于该参数变量的,InnoDB将会异步的将下一个extent读取到buffer pool中,比如该参数的值为30,那么当该extent中有30个pages被sequentially的读取,则会触发InnoDB linear预读,将下一个extent读到内存中;在没有该变量之前,当访问到extent的***一个page的时候,InnoDB会决定是否将下一个extent放入到buffer pool中;可以在MySQL服务端通过show InnoDB status中的Pages read ahead和evicted without access两个值来观察预读的情况:
Innodb_buffer_pool_read_ahead:表示通过预读请求到buffer pool的pages;
Innodb_buffer_pool_read_ahead_evicted:表示由于请求到buffer pool中没有被访问,而驱逐出内存的页数。
可以看出来,MySQL的缓冲池机制是能充分利用内存且有预加载机制,在某些条件下目标数据完全在内存中,也能够具备非常好的查询性能。
2、MongoDB的存储结构及数据模型
(1)本例中MongoDB使用的储存引擎是WiredTiger,WiredTiger的结构如图3-2所示。
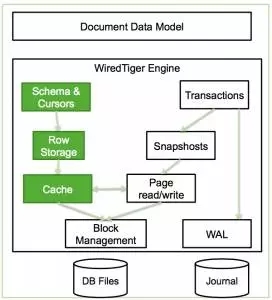
图3-2 WiredTiger Engine的结构
WiredTiger Cache的实现原理图如图3-3所示。
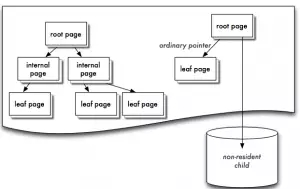
图3-3 WiredTiger Cache的实现原理图
Wiredtiger的Cache采用Btree的方式组织,每个Btree节点为一个page,root page是btree的根节点,internal page是btree的中间索引节点,leaf page是真正存储数据的叶子节点;btree的数据以page为单位按需从磁盘加载或写入磁盘。
可以通过在配置文件中指定storage.wiredTiger.engineConfig.cacheSizeGB参数设定引擎使用的内存量。此内存用于缓存工作集数据(索引、namespace,未提交的write,query缓冲等)。
(2)数据模型
内嵌
MongoDB的文档是无模式的,所以可以支持各种数据结构,内嵌模型也叫做非规格化模型(denormalized)。在MongoDB中,一组相关的数据可以是一个文档,也可以是组成文档的一部分。

图3-4 内嵌文档示例
内嵌类型支持一组相关的数据存储在一个文档中,这样的好处就是,应用程序可以通过比较少的的查询和更新操作来完成一些常规的数据的查询和更新工作。
当遇到以下情况的时候,我们应该考虑使用内嵌类型:
如果数据关系是一种一对一的包含关系,例如下面的文档,每个人都有一个contact字段来描述这个人的联系方式。像这种一对一的关系,使用内嵌类型可以很方便的进行数据的查询和更新。
{
”_id”: ,
”name”: “Wilber”,
”contact”: {
“phone”: “12345678”,
“email”: “wilber@shanghai.com”
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
如果数据的关系是一对多,那么也可以考虑使用内嵌模型。例如下面的文档,用posts字段记录所有用户发布的博客。在这中情况中,如果应用程序会经常通过用户名字段来查询改用户发布的博客信息。那么,把posts作为内嵌字段会是一个比较好的选择,这样就可以减少很多查询的操作。
{
“_id”: ,
“name”: “Wilber”,
“contact”: {
”phone”: “12345678”,
”email”: “wilber@shanghai.com”
},
”posts”: [
{
”title”: “Indexes in MongoDB”,
”created”: “12/01/2014”,
”link”: “www.linuxidc.com”
},
{
”title”: “Replication in MongoDB”,
”created”: “12/02/2014”,
”link”: “www.linuxidc.com”
},
{
”title”: “Sharding in MongoDB”,
”created”: “12/03/2014”,
”link”: “www.linuxidc.com”
}
]
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
根据上面的描述可以看出,内嵌模型可以给应用程序提供很好的数据查询性能,因为基于内嵌模型,可以通过一次数据库操作得到所有相关的数据。同时,内嵌模型可以使数据更新操作变成一个原子写操作。然而,内嵌模型也可能引入一些问题,比如说文档会越来越大,这样就可能会影响数据库写操作的性能,还可能会产生数据碎片(data fragmentation)。
引用
相对于嵌入模型,引用模型又称规格化模型(Normalized data models),通过引用的方式来表示数据之间的关系。这里同样使用来自MongoDB文档中的图片,在这个模型中,把contact和access从user中移出,并通过user_id作为索引来表示它们之间的联系。

图3-5 引用文档示例
当我们遇到以下情况的时候,就可以考虑使用引用模型了:
- 使用内嵌模型往往会带来数据的冗余,却可以提升数据查询的效率。但是,当应用程序基本上不通过内嵌模型查询,或者说查询效率的提升不足以弥补数据冗余带来的问题时,我们就应该考虑引用模型了。
- 当需要实现复杂的多对多关系时,可以考虑引用模型。比如我们熟知的例子,学生-课程-老师关系,如果用引用模型来实现三者的关系,可能会比内嵌模型更清晰直观,同时会减少很多冗余数据。
- 当需要实现复杂的树形关系时,可以考虑引用模型。
四、应用场景分析
1、MongoDB的应用场景
(1)表结构不明确且数据不断变大
MongoDB是非结构化文档数据库,扩展字段很容易且不会影响原有数据。内容管理或者博客平台等,例如圈子系统、存储用户评论之类的。
(2)更高的写入负载
MongoDB侧重高数据写入的性能,而非事务安全,适合业务系统中有大量“低价值”数据的场景。本身存的就是json格式数据。例如做日志系统。
(3)数据量很大或者将来会变得很大
MySQL单表数据量达到5-10G时会出现明细的性能降级,需要做数据的水平和垂直拆分、库的拆分完成扩展,MongoDB内建了sharding、很多数据分片的特性,容易水平扩展,比较好的适应大数据量增长的需求。
(4)高可用性
自带高可用,自动主从切换(副本集)
不适用的场景
(1)MongoDB不支持事务操作,需要用到事务的应用建议不用MongoDB。
(2)MongoDB目前不支持join操作,需要复杂查询的应用也不建议使用MongoDB。
2、关系型数据库和非关系型数据库的应用场景对比
关系型数据库适合存储结构化数据,如用户的帐号、地址:
- 这些数据通常需要做结构化查询,比如join。这时候,关系型数据库就要胜出一筹
- 这些数据的规模、增长的速度通常是可以预期的
- 事务性、一致性
NoSQL适合存储非结构化数据,如文章、评论:
- 这些数据通常用于模糊处理,如全文搜索、机器学习
- 这些数据是海量的,而且增长的速度是难以预期的
- 根据数据的特点,NoSQL数据库通常具有***(至少接近)伸缩性
- 按key获取数据效率很高,但是对join或其它结构化查询的支持就比较差



















