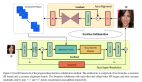
单图像超分辨率技术涉及到增加小图像的大小,同时尽可能地防止其质量下降。这一技术有着广泛用途,包括卫星和航天图像分析、医疗图像处理、压缩图像/视频增强及其他应用。我们将在本文借助三个深度学习模型解决这个问题,并讨论其局限性和可能的发展方向。
我们通过网页应用程序的形式部署开发结果,允许在自定义图像上测试文中的大多数方法,同样你也可以查看我们的实例:http://104.155.157.132:3000/。
单图像超分辨率:问题陈述
我们的目标是采用一个低分辨率图像,产生一个相应的高分辨率图像的评估。单图像超分辨率是一个逆问题:多个高分辨率图像可以从同一个低分辨率图像中生成。比如,假设我们有一个包含垂直或水平条的 2×2 像素子图像(图 1)。不管条的朝向是什么,这四个像素将对应于分辨率降低 4 倍的图像中的一个像素。通过现实中的真实图像,一个人需要解决大量相似问题,使得该任务难以解决。

图 1:从左到右依次是真值 HR 图像、相应的 LR 图像和一个训练用来最小化 MSE 损失的模型的预测。
首先,让我们先了解一个评估和对比模型的量化质量检测方法。对于每个已实现的模型,我们会计算一个通常用于测量有损压缩编解码器重建质量的指标,称之为峰值信噪比(PSNR/Peak Signal to Noise Ratio)。这一指标是超分辨率研究中使用的事实标准。它可以测量失真图像与原始高质量图像的偏离程度。在本文中,PSNR 是原始图像与其评估版本(噪声强度)之间图像(信号强度)可能的最大像素值与最大均方误差(MSE)的对数比率。
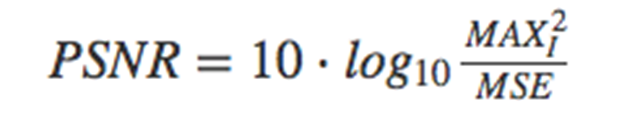
PSNR 值越大,重建效果越好,因此 PSNR 的最大值化自然会最小化目标函数 MSE。我们在三个模型中的两个上使用了该方法。在我们的实验中,我们训练模型把输入图像的分辨率提升四倍(就宽度和高度而言)。在这一因素之上,哪怕提升小图像的分辨率也变的很困难。比如,一张分辨率提升了八倍的图像,其像素数量扩大了 64 倍,因此需要另外的原始格式的 64 倍内存存储它,而这是在训练之中完成的。我们已经在文献常用的 Set5、Set14 和 BSD100 基准上测试了模型。这些文献中引用了在这些数据集上进行测试的模型的结果,使得我们可以对比我们的结果和之前作者的结果。
这些模型已在 PyTorch 做了实现(http://pytorch.org/)。
为什么选择深度学习?
提高图像分辨率的最常用技术之一是插值(interpolation)。尽管易于实现,这一方法在视觉质量方面依然有诸多不足,比如很多细节(比如尖锐的边缘)无法保留。



图 2:最常见的插值方法产生的模糊图像。自上而下依次是最近邻插值、双线性插值和双立方插值。该图像的分辨率提升了四倍。
更复杂的方法则利用给定图像的内部相似性或者使用低分辨率图像数据集及其对应的高质量图像,有效地学习二者之间的映射。在基于实例的 SR 算法中,稀疏编码方法是最为流行的方法之一。
这一方法需要找到一个词典,允许我们把低分辨率图像映射到一个中间的稀疏表征。此外,HR 词典已被学习,允许我们存储一个高分辨率图像的评估。该流程通常涉及若干个步骤,且无法全部优化。理想情况下,我们希望把这些步骤合而为一,其中所有部分皆可优化。这种效果可以通过神经网络来达到,网络架构受到稀疏编码的启发。
更多信息请参见:http://www.irisa.fr/prive/kadi/Gribonval/SuperResolution.pdf。
SRCNN
SRCNN 是超越传统方法的首个深度学习方法。它是一个卷积神经网络,包含 3 个卷积层:图像块提取与表征、非线性映射和最后的重建。
图像在馈送至网络之前需要通过双立方插值进行上采样,接着它被转化为 YCbCr 色彩空间,尽管该网络只使用亮度通道(Y)。然后,网络的输出合并已插值的 CbCr 通道,输出最终彩色图像。我们选择这一步骤是因为我们感兴趣的不是颜色变化(存储在 CbCr 通道中的信息)而只是其亮度(Y 通道);根本原因在于相较于色差,人类视觉对亮度变化更为敏感。
我们发现 SRCNN 很难训练。它对超参数的变化非常敏感,论文中展示的设置(前两层的学习率为 10-4,最后两层的学习率为 10-5,使用 SGD 优化器)导致 PyTorch 实现输出次优结果。我们观察到在不同的学习率下,输出结果有一些小的改变。最后我们发现,使性能出现大幅提升的是设置是:每层的学习率为 10-5,使用 Adam 优化器。最终网络在 1.4 万张 32×32 的子图上进行训练,图像和原始论文中的图像来自同样的数据集(91 张图像)。

图 3:左上:双立方插值,右上:SRCNN,左下:感知损失,右下:SRResNet。SRCNN、感知损失和 SRResNet 图像由对应的模型输出。
感知损失(Perceptual loss)
尽管 SRCNN 优于标准方法,但还有很多地方有待改善。如前所述,该网络不稳定,你可能会想优化 MSE 是不是最佳选择。
很明显,通过最小化 MSE 获取的图像过于平滑。(MSE 输出图像的方式类似于高分辨率图像,导致低分辨率图像,[图 1])。MSE 无法捕捉模型输出和真值图像之间的感知区别。想象一对图像,第二个复制了第一个,但是改变了几个像素。对人类来说,复制品和原版几乎无法分辨,但是即使是如此细微的改变也能使 PSNR 显著下降。
如何保存给定图像的可感知内容?神经风格迁移中也出现了类似的问题,感知损失是一个可能的解决方案。它可以优化 MSE,但不使用模型输出,你可以使用从预训练卷积神经网络中提取的高级图像特征表示(详见 https://github.com/pytorch/vision/blob/master/torchvision/models/vgg.py#L81)。这种方法的基础在于图像分类网络(如 VGG)把物体细节的信息存储在特征图中。我们想让自己提升后的图像中的物体尽可能地逼真。
除了改变损失函数,网络架构也需要重新建模。该模型比 SRCNN 深,使用残差块,在低分辨率图像上进行大部分处理(加速训练和推断)。提升也发生在网络内部。在这篇论文中(https://arxiv.org/abs/1603.08155),作者使用转置卷积(transposed convolution,又叫解卷积,deconvolution),3×3 卷积核,步幅为 2。该模型输出的「假」图像看起来与棋盘格滤镜效果类似。为了降低这种影响,我们还尝试了 4×4 卷积的解卷积,以及最近邻插值与 3×3 的卷积层,步幅为 1。最后,后者得到了最好的结果,但是仍然没有完全移除「假」图像。
与论文中描述的过程类似,我们的训练流程包括从 MS‑COCO 近一万张图像中抽取的一些 288×288 随机图像组成的数据集。我们将学习率设置为 10-3,使用 Adam 优化器。与上面引用的论文不同,我们跳过了后处理(直方图匹配),因为该步骤无法提供任何改进。
SRResNet
为了最大化 PSNR 性能,我们决定实现 SRResNet 网络,它在标准基准上达到了当前最佳的结果。原论文(https://arxiv.org/abs/1609.04802)提到一种扩展方式,允许修复更高频的细节。
和上文描述的残差网络一样,SRResNet 的残差块架构基于这篇文章(http://torch.ch/blog/2016/02/04/resnets.html)。存在两个小的更改:一个是 SRResNet 使用 Parametric ReLU 而不是 ReLU,ReLU 引入一个可学习参数帮助它适应性地学习部分负系数;另一个区别是 SRResNet 使用了图像上采样方法,SRResNet 使用了子像素卷积层。详见:https://arxiv.org/abs/1609.07009。
SRResNet 生成的图像和论文中呈现的结果几乎无法区分。训练用了两天时间,训练过程中,我们使用了学习率为 10-4 的 Adam 优化器。使用的数据集包括来自 MS‑COCO 的 96×96 随机图像,与感知损失网络类似。
未来工作
还有一些适用于单图像超分辨率的有潜力的深度学习方法,但由于时间限制,我们没有一一测试。
这篇近期论文(https://arxiv.org/abs/1707.02921)提到使用修改后的 SRResNet 架构获得了非常好的 PSNR 结果。作者移除残差网络中的批归一化,把残差层的数量从 16 增加到 32。然后把网络在 NVIDIA Titan Xs 上训练七天。我们通过更快的迭代和更高效的超参数调整,把 SRResNet 训练了两天就得到了结果,但是无法实现上述想法。
我们的感知损失实验证明 PSNR 可能不是一个评估超分辨率网络的合适指标。我们认为,需要在不同类型的感知损失上进行更多研究。我们查看了一些论文,但是只看到网络输出的 VGG 特征图表示和真值之间的简单 MSE。现在尚不清楚为什么 MSE(每像素损失)在这种情况中是一个好的选择。
另一个有潜力的方向是生成对抗网络。这篇论文(https://arxiv.org/abs/1609.04802)使用 SRResNet 作为 SRGAN 架构的一部分,从而扩展了 SRResNet。该网络生成的图像包含高频细节,比如动物的皮毛。尽管这些图像看起来更加逼真,但是 PSNR 的评估数据并不是很好。



图 4:从上到下:SRResNet 实现生成的图像、SRResNet 扩展生成的图像,以及原始图像
结论
本文中,我们描述了用于单图像超分辨率的三种不同的卷积神经网络实验,下图总结了实验结果。

图 5:本文讨论模型的优缺点
使用 PSNR 在标准基准数据集上进行度量时,即使简单的三层 SRCNN 也能够打败大部分非机器学习方法。我们对感知损失的测试证明,该指标不适合评估我们的模型性能,因为:我们能够输出美观的图像,但使用 PSNR 进行评估时,竟然比双立方插值算法输出的图像差。最后,我们重新实现了 SRResNet,在基准数据集上重新输出当前最优的结果。