












当我们想搭建一个Hadoop大数据平台时,碰到的第一个问题就是我们到底该如何选择硬件。
虽然Hadoop被设计为可以运行在标准的X86硬件上,但在选择具体服务器配置的时候其实没那么简单。为已知的工作负载或者应用场景选择硬件时,往往都要综合考虑性能因素和性价比,才能选择合适的硬件。比如,对于IO密集型的工作负载,用户往往需要为每个CPU core匹配更多的存储或更高的吞吐(more spindles per core)。
通过本文,您将学习到如何根据工作负载来选择硬件,包括一些其他您需要考虑的因素。
1.计算和存储
过去的十年,业界基本已经形成了刀片和SANs(Storage Area Networks)的标准,从而满足网格和处理密集型的工作负载。这种模式对于许多标准应用(比如Web服务器,应用服务器,较小的结构化数据和数据搬运)还都是适用的,但是随着数据量和用户数据的增长,基础设施的需求也发生了变化。Web服务器现在已经有了缓存层,数据库借助本地磁盘开始支持海量并发,数据搬运的压力迫使我们需要更多的在本地处理数据。
“很多人在搭建Hadoop集群时都没有去真正了解过工作负载”
硬件供应商更新了对应的产品来满足相应的需求,包括存储刀片,SAS(Serial Attached SCSI)交换机,外挂的SATA阵列和容量更大的机架。然而,Hadoop是基于一个全新的存储和处理数据的方式,尽量避免数据传输。Hadoop通过软件层来实现大数据的处理以及可靠性,而不像一个SAN存储所有数据,如果计算则传输到一系列刀片进行计算。
Hadoop将数据分布式存储在各台服务器上,使用文件副本来保证数据不丢以及容错。这样一个计算请求可以直接分发到存储数据的相应服务器并开始进行本地计算。由于Hadoop集群的每台节点都会存储和处理数据,所以你就需要考虑怎样为集群里的这些服务器选择合适的配置。
2.为什么跟工作负载有关系
在很多情况下,MapReduce/Spark都会遭遇瓶颈,比如从磁盘或者网络读取数据(IO-bound的作业),或者在CPU处理大量数据时(CPU-bound的作业)。IO-bound的作业的一个例子是排序,一般需要很少的处理(简单的比较)却需要大量的读写磁盘。CPU-bound的作业的一个例子是分类(classification),一些数据往往需要很复杂的处理。
典型的IO-bound的工作负载如下:
- 索引(Indexing)
- 分组(Grouping)
- 数据导入导出
- 数据传输和转换
典型的CPU-bound工作负载如下:
- 聚类和分类(Clustering/Classification)
- 复杂的文本挖掘
- 自然语言处理
- 特征提取
我们需要完全了解工作负载,才能够正确的选择合适的Hadoop硬件。很多人因为从来没有研究过工作负载,往往会导致Hadoop运行的作业是基于不合适的硬件。此外,一些工作负载往往会受到一些其他的限制。比如因为选择了压缩,本应该是IO-bound的工作负载实际却是CPU-bound的,或者因为算法选择不同而使MapReduce或者Spark作业受限。由于这些原因,当您不熟悉未来将要运行的工作负载时,可以选择一些较为均衡的硬件配置来搭建Hadoop集群。
接下来我们就可以在集群中运行一些MapReduce/Spark作业进行基准测试,来分析它们的bound方式。可以通过一些监控工具来确定工作负载的瓶颈。当然Cloudera Manager提供了这个功能,包括CPU,磁盘和网络负载的实时统计信息。通过Cloudera Manager,当集群在运行作业时,系统管理员可以通过dashboard很直观的查看每台机器的性能表现。
“第一步是了解运维部门管理的硬件。”
除了根据工作负载来选择硬件外,还可以与硬件厂商一起了解耗电和散热以节省额外的开支。由于Hadoop是运行在数十,数百甚至数千个节点上,尽可能多的考虑方方面面都可以节省成本。每个硬件厂商都提供了专门的工具来监控耗电和散热,以及如何改良的最佳实践。
3.为CDH集群挑选硬件
在挑选硬件的时候,第一步是了解您的运维部门所管理的硬件类型。运维部门往往倾向于选择他们熟悉的硬件。但是,如果您是在搭建一个新的集群,并且无法准确的预测集群未来的工作负载,我们建议您还是选择适合Hadoop较为均衡的硬件。
一个Hadoop集群通常有4个角色:NameNode(和Standby NameNode),ResourceManager,NodeManager和DataNode。集群中的绝大多数机器同时是NodeManager和DataNode,既用于数据存储,又用于数据处理。
以下是较为通用和主流的NodeManager/DataNode配置:
- 12-24块1-6TB硬盘, JBOD (Just a Bunch Of Disks)
- 2 路8核,2路10核,2路12核的CPU, 主频至少2-2.5GHz
- 64-512GB内存
- 绑定的万兆网 (存储越多,网络吞吐就要求越高)
NameNode负责协调集群上的数据存储,ResourceManager则是负责协调数据处理。Standby NameNode不应该与NameNode在同一台机器,但应该选择与NameNode配置相同的机器。我们建议您为NameNode和ResourceManager选择企业级的服务器,具有冗余电源,以及企业级的RAID1或RAID10磁盘配置。
NameNode需要的内存与集群中存储的数据块成正比。我们常用的计算公式是集群中100万个块(HDFS blocks)对应NameNode的1GB内存。常见的10-50台机器规模的集群,NameNode服务器的内存配置一般选择128GB,NameNode的堆栈一般配置为32GB或更高。另外建议务必配置NameNode和ResourceManager的HA。
以下是NameNode/ResourceManager及其Standby节点的推荐配置。磁盘的数量取决于你想冗余备份元数据的份数。
- 4–6个1TB的硬盘,JBOD(1个是OS, 2个是NameNode的FS image [RAID 1], 1个配置给Apache ZooKeeper, 还一个是配置给Journal node)
- 2路6核,2路8核的CPU, 主频至少2-2.5GHz
- 64-256GB的内存
- 绑定的万兆网
“记住,Hadoop生态系统的设计需考虑并行环境。”
如果预期你的Hadoop集群未来会超过20台机器,建议集群初始规划就跨两个机架,每个机柜都配置柜顶(TOR,top-of-rack)的10GigE交换机。随着集群规模的扩大,跨越多个机架时,我们在机架之上还要配置冗余的核心交换机,带宽一般为40GigE,用来连接所有机柜的柜顶(TOR)交换机。拥有两个机架,可以让运维团队更好的了解机架内以及跨机架的网络通信需求。Hadoop网络要求可以参考Fayson之前的文章CDH网络要求(Lenovo参考架构)。
当搭建好Hadoop集群后,我们就可以开始识别和整理运行在集群之上的工作负载,并且为这些工作负载准备基准测试,以定位硬件的瓶颈在哪里。经过一段时间的基准测试和监控,我们就可以了解需要如何增加什么样配置的新机器。异构的Hadoop集群是比较常见的,特别是随着数据量和用例数量的增加,集群需要扩容时。所以如果因为前期并不熟悉工作负载,选择了一些较为通用的服务器,也并不是不能接受。Cloudera Manager支持服务器分组,从而使异构集群配置变的很简单。
以下是不同的工作负载的常见机器配置:
- Light Processing Configuration,1U的机器,一般为测试,开发或者低要求的场景:2个hex-core CPUs,24-64GB内存,8个磁盘(1TB或者2TB)
- Balanced Compute Configuration,均衡或主流的配置,1U/2U的机器:2个hex-core CPUs,48-256GB的内存,12-16块磁盘(1TB-4TB),硬盘为直通挂载
- Storage Heavy Configuration,重存储的配置,2U的机器:2个hex-core CPUs,48-128GB的内存,16-24块磁盘(2TB-6TB)。这种配置一旦多个节点或者机架故障,将对网络流量造成很大的压力
- Compute Intensive Configuration,计算密集型的配置,2U的机器:2个hex-core CPUs,64-512GB memory,4-8块磁盘(1TB-4TB)
注意:以上2路6核为最低的CPU配置,推荐的CPU选择一般为2路8核,2路10核,2路12核
下图显示如何根据工作负载来选择你的机器:
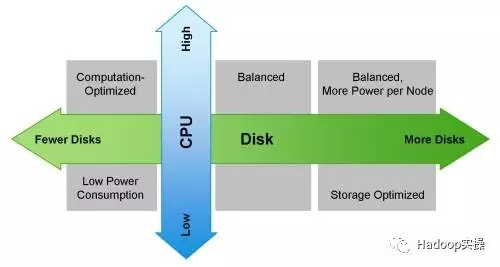
4.其他注意事项
Hadoop生态系统是一个并行环境的系统。在选择购买处理器时,我们不建议选择主频(GHz)最高的芯片,这样一般都代表了更高电源瓦数(130W+)。因为这会产生两个问题:更高的功率消耗和需要更多的散热。较为均衡的选择是在主频,价格和核数之间做一个平衡。
当存在产生大量中间结果的应用程序 – 输出结果数据与输入数据相当,或者需要较多的网络交换数据时,建议使用绑定的万兆网,而不是单个万兆网口。
当计算对内存要求比较高的场景,请记住,Java最多使用10%的内存来管理虚拟机。建议严格配置Hadoop使用的堆大小的限制,从而避免内存交换到磁盘,因为交换会大大影响计算引擎如MapReduce/Spark的性能。
优化内存通道宽度也同样重要。比如,当使用双通道内存时,每台机器都应配置一对DIMM。使用三通道内存时,每个机器都应该具有三倍的DIMM。同样,四通道DIMM应该被分为四组。
5.Hadoop其他组件的考虑
Hadoop远远不止HDFS和MapReduce/Spark,它是一个全面的数据平台。CDH平台包含了很多Hadoop生态圈的其他组件。我们在做群集规划的时候往往还需要考虑HBase,Impala和Solr等。它们都会运行在DataNode上运行,从而保证数据的本地性。
HBase是一个可靠的,列存储数据库,提供一致的,低延迟的随机读/写访问。Cloudera Search通过Solr实现全文检索,Solr是基于Lucene,CDH很好的集成了Solr Cloud和Apache Tika,从而提供更多的搜索功能。Apache Impala则可以直接运行在HDFS和HBase之上,提供交互式的低延迟SQL查询,避免了数据的移动和转换。
由于GC超时的问题,建议的HBase RegionServer的heap size大小一般为16GB,而不是简单的越大越好。为了保证HBase实时查询的SLA,可以通过Cgroups的的方式给HBase分配专门的静态资源。
Impala是内存计算引擎,有时可以用到集群80%以上的内存资源,因此如果要使用Impala,建议每个节点至少有128GB的内存。当然也可以通过Impala的动态资源池来对查询的内存或用户进行限制。
Cloudera Search在做节点规划时比较有趣,你可以先在一个节点安装Solr,然后装载一些文档,建立索引,并以你期望的方式进行查询。然后继续装载,直到索引建立以及查询响应超过了你的预期,这个时候你就需要考虑扩展了。单个节点Solr的这些数据可以给你提供一些规划时的参考,但不包括复制因子因素。
6.总结
选择并采购Hadoop硬件时需要一些基准测试,应用场景测试或者Poc,以充分了解你所在企业的工作负载情况。但Hadoop集群也支持异构的硬件配置,所以如果在不了解工作负载的情况下,建议选择较为均衡的硬件配置。还需要注意一点,Hadoop平台往往都会使用多种组件,资源的使用情况往往都会不一样,专注于多租户的设计包括安全管理,资源隔离和分配,将会是你成功的关键。

















